Weekly Hallucinations: GPT-5.3-Codex-Spark, Sonnet 4.6 and China's MoE Offensive
Author: Aleksei Beltiukov

Six flagship releases in one week. Let's dive in to see who has made real progress and who just updated their benchmarks.
GPT-5.3-Codex-Spark, the result of a partnership between OpenAI and Cerebras. They claim 1000+ tok/sec. Judging by the video, the model works incredibly fast. The context window is 128K (compared to the usual Codex's 400K), but fast compacting compensates for the difference. Groq and Cerebras are already making fast inference the new norm.
If OpenAI's next full-scale model with Cerebras power delivers at least 200-300 tok/sec, it could kill its main competitor, Anthropic. Right now, we choose the model that writes code better, but later it will simply be uncomfortable to work with a model that outputs 70-80 tok/sec. As I mentioned last week, Opus 4.6 Fast is 2.5 times faster than the regular Opus but 6 times more expensive. OpenAI doesn't charge extra for speed, but to try it out, you need a Pro subscription for $200.
Since the release of GPT-5.3-Codex and Opus 4.6 in early February, the holy wars on Twitter haven't stopped as everyone tries to decide which model is better. If you're interested too, here is what I think is a decent comparison. Personally, my impressions of these models are exactly the same.
On Monday morning, I woke up to the news: OpenAI hired Peter Steinberger, the creator of OpenClaw. He will lead the personal agents division. The community is outraged. Sam Altman called him a genius.
And Meta, seemingly offended that they couldn't recruit the genius, released Manus Agents. It looks very much like it was inspired by OpenClaw.
It seems to me that if anyone needs personal agents right now, it's mobile devices. Especially Apple with their Siri, which is already embarrassing to mention. Partnerships with OpenAI and Google Gemini have not yet yielded results.
And while I was writing this, Anthropic released Sonnet 4.6. Benchmarks place it close to Opus, even surpassing it in some tasks (office work, financial analysis). They've seriously improved computer use: the model manages interfaces more stably and breaks less during long sessions. Agentic coding is at 79.6%, nearly as good as Opus (80.8%). The 1M context is in beta (where else). Next week, I'll try to gather real user feedback on the model.
Don't forget that OpenAI is running a promotion: Codex is available even on the free tier and Go, and those who already have a subscription have been given increased limits. You can create a new account and, if you're lucky, get an offer for a Plus subscription for zero dollars and zero cents.
Anthropic isn't lagging behind either: on February 11, Claude Cowork for Windows was released, and features that previously required payment became available on the free tier. If you haven't tried it yet—give it a go.
What about China? Qwen3.5 from Alibaba: 397B parameters, 17B active. GLM-5 from Z-ai: 744B parameters, 40B active. The principle is the same: the MoE architecture stores the knowledge of a massive model, but only a small part works during inference. The GPU load is like that of a 17-40B model, but it competes with Opus in benchmarks. There are also rumors about the upcoming release of DeepSeek v4. I talked about modern LLM architectures here.
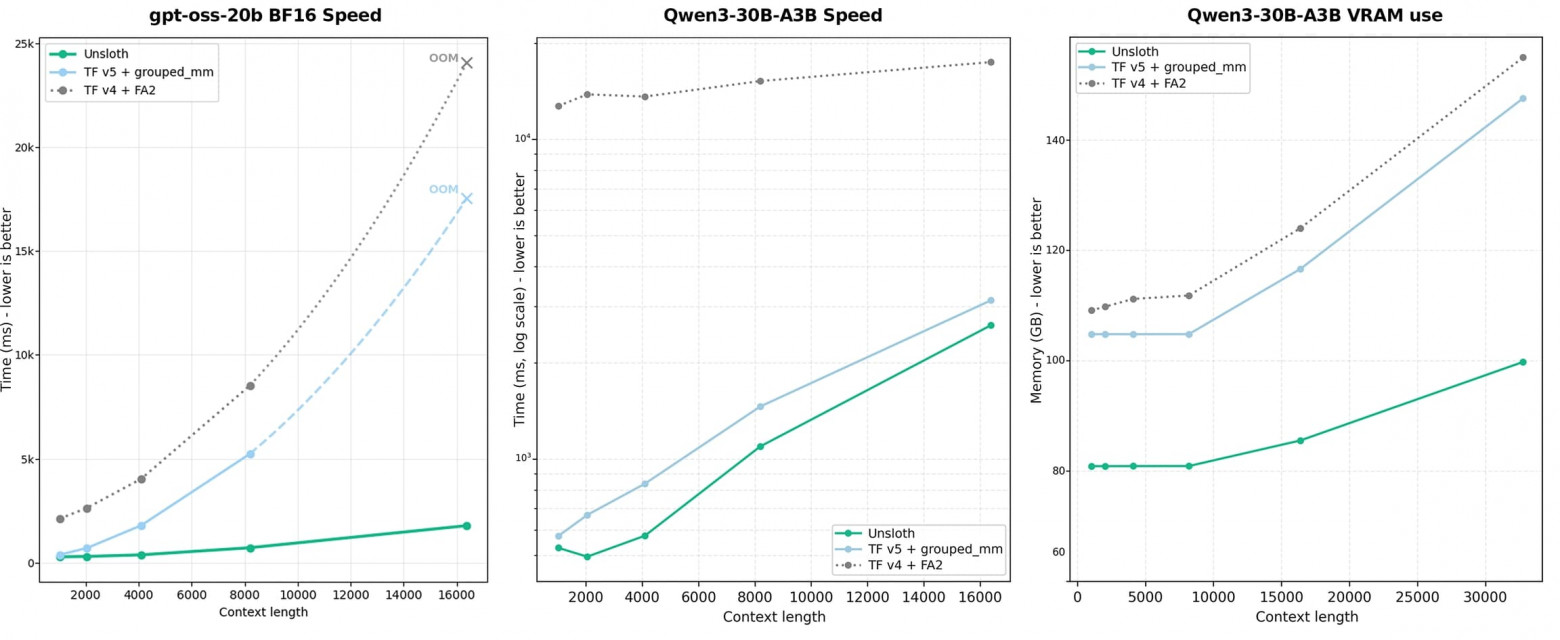
Unsloth has released custom Triton kernels for training MoE models. They're 12 times faster than standard training, use 35% less VRAM, and have no loss in accuracy. It runs on an RTX 3090. Fine-tuning MoE models for your tasks on a single GPU is no longer a fantasy. For self-hosters, this is arguably the biggest news of the week.
About benchmarks. The new Chinese models show 70-80% on SWE-Bench Verified. It's impressive until you look at SWE-rebench. This is a newer benchmark specifically designed so that answers cannot be found on the internet: tasks are from repositories that were not in the training data. A flagship like Opus 4.6 gives 51.7%, while the Chinese "killers" are clustered around ~40%. SWE-bench has turned into a standardized test where the winner is the one who solved the most practice exams, not the one who writes better code.
Seedance 2.0 from ByteDance showed that text-to-video has crossed the "is this real?" threshold. But with quality come questions: the model recognized a blogger by their face and recreated their voice. Some consider this overfitting, while others think ByteDance itself hyped the story for PR.
Qwen-Image-2.0 has shrunk from 20B to 7B without losing quality, featuring native 2K and text rendering. I really like the direction image generation is heading, and this magic began in August.

If you have time to try only one thing this week, try Codex on the free tier while the promotion lasts. If you have time for two, compare it with Claude Code on the same task. The conclusions might surprise you.
Stay curious.


