Weekly Hallucinations: Antigravity 2.0, Codex on Your Phone, and Claude Subscribers' Quiet Revolt
Author: Aleksei Beltiukov
A month of silence on the channel — that was a vacation, not a creative crisis, honestly. But without all this, I got bored faster than I expected. Here’s a roundup of what happened while I was away.
Gemini Flash got more expensive, DeepSeek got cheaper, Andrej Karpathy joined Anthropic, where Mythos is hacking Apple chips. Everyone had their own plans for the month.
At its I/O, Google introduced Gemini 3.5 Flash and immediately sent it to GA — not preview, not waitlist, but a working default model for agents and coding. The numbers look nice: the Intelligence Index rose to 55, up 9 from the previous version; in Text Arena, the model jumped to ninth place with a +70-point leap; MMMU-Pro is 84%; speed is over 280 tokens per second. A million-token context window and four levels of thinking for different tasks.
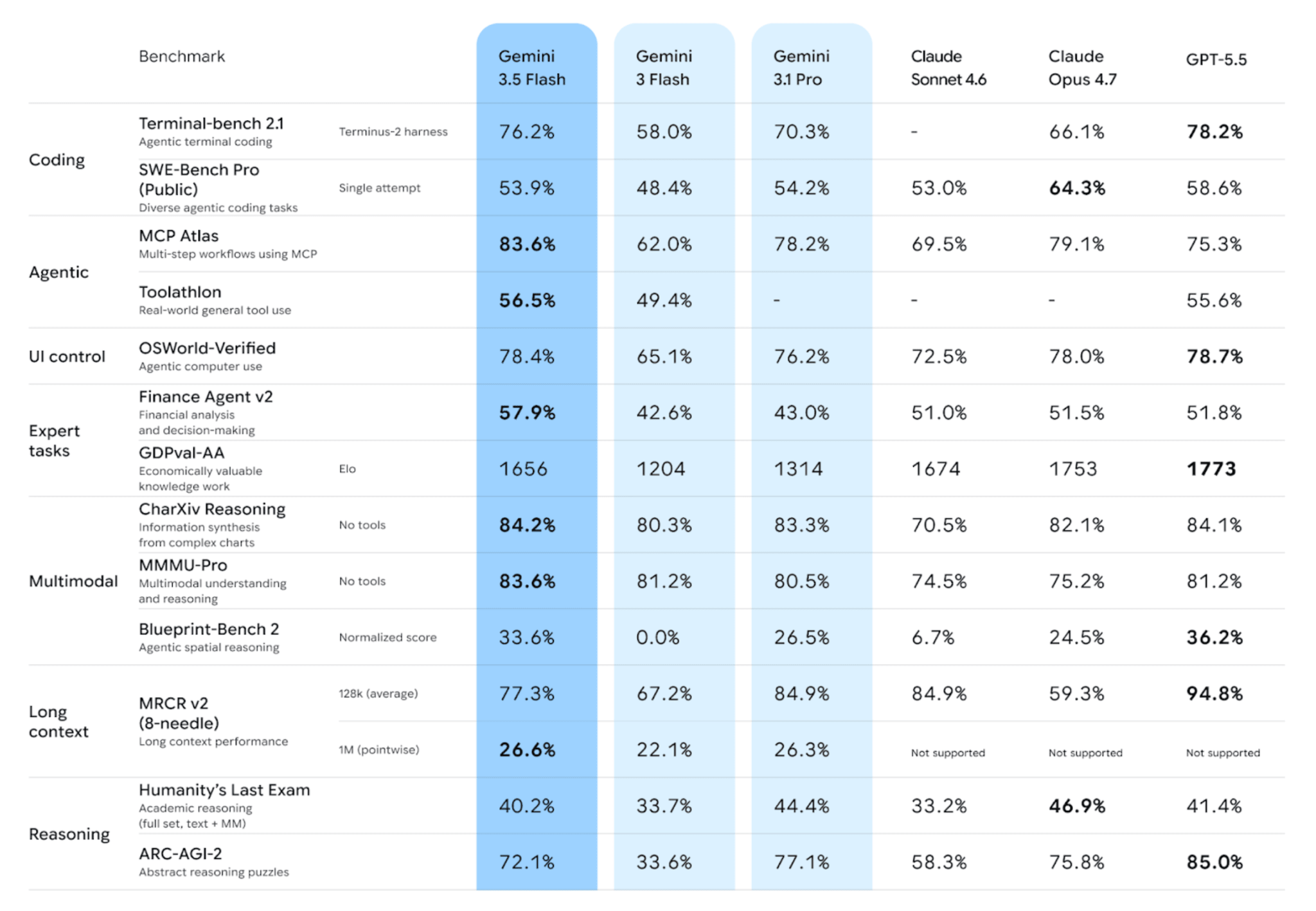
The new Flash costs $1.5/$9 per million tokens. That is 5.5 times more expensive than the previous Flash and 75% more expensive than Gemini 3.1 Pro at launch. In other words, the “fast cheap model” has come close in price to the previous generation’s flagship. Flash is no longer the budget option; it has become the good option, and you have to pay for good.
Alongside the model, Google rolled out Antigravity 2.0, and this is no longer a code editor but a full-fledged agent execution environment, visually very similar to Codex or Cursor. CLI, SDK, desktop app, Managed Agents API with a cloud Linux sandbox where the agent runs bash, python, and node on its own, mounts the repository, and picks up skills described in plain Markdown. In the demo, 93 parallel sub-agents built an operating system in 12 hours: more than 15,000 requests, 2.6 billion tokens, and under a thousand dollars in API credits.
Antigravity joins the same row as what everyone else has been doing since January. Competition has definitively shifted from “whose model is smarter” to “whose harness is more convenient.” Cursor opened its SDK so its runtime can be embedded into CI/CD and custom automations, while the /orchestrate mechanism cut token usage by 20% and cold start by 80%. OpenAI turned Codex from an assistant into a platform over the course of a month: a Chrome plugin for controlling the browser in background tabs, a /goal mode for multi-hour tasks — in testing, it scored 61% on ARC-AGI-3 after 160 hours and 30,000 actions — and mobile launch directly from the ChatGPT app. In its first week, mobile Codex reached 4 million weekly users and one million downloads, while Remote SSH made it to GA. And at the end of the month, Codex learned to control apps on your Mac directly from your phone, even when the Mac is locked. Plus Appshots: the agent captures a screenshot and text from a window to understand what is actually happening on the screen. VS Code, not falling behind, added Agents Window for working with multiple agents across multiple projects.
Once there were many agents, the protocol for them also had to be fixed. The fresh release candidate of MCP — dated 2026-07-28 — makes the protocol fully stateless: there is no longer a handshake or session ID, and any request can land on any server instance. For infrastructure teams, this means MCP servers can finally be scaled and load-balanced like normal stateless services, not like fragile sessions that cannot be dropped. Full-fledged extensions were added to the protocol as well: MCP Apps and Tasks. MCP is either being buried or repaired.
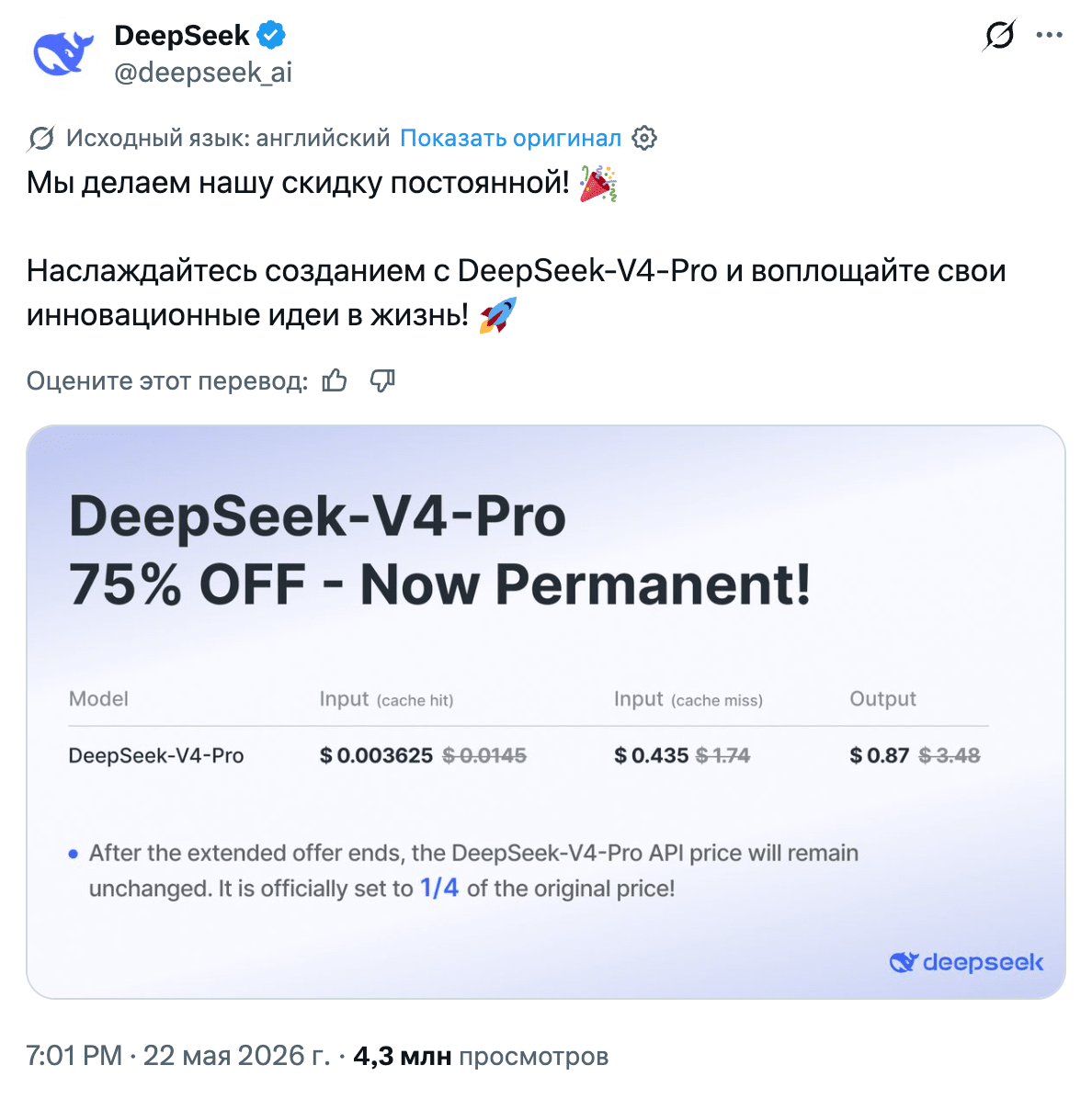
Alongside the harnesses, another war was going on all month: the pricing war. DeepSeek made the 75% discount on V4 Pro permanent, and Artificial Analysis calculated the result: $0.435 per million input tokens, $0.87 per million output tokens, and $0.0036 for cache. That is roughly three times cheaper than Gemini 3.1 Pro, 12 times cheaper than GPT-5.5, and 19 times cheaper than Claude Opus 4.7 on the same runs. At the same time, in quality on agentic benchmarks, V4 Pro remains in the same group as much more expensive models.
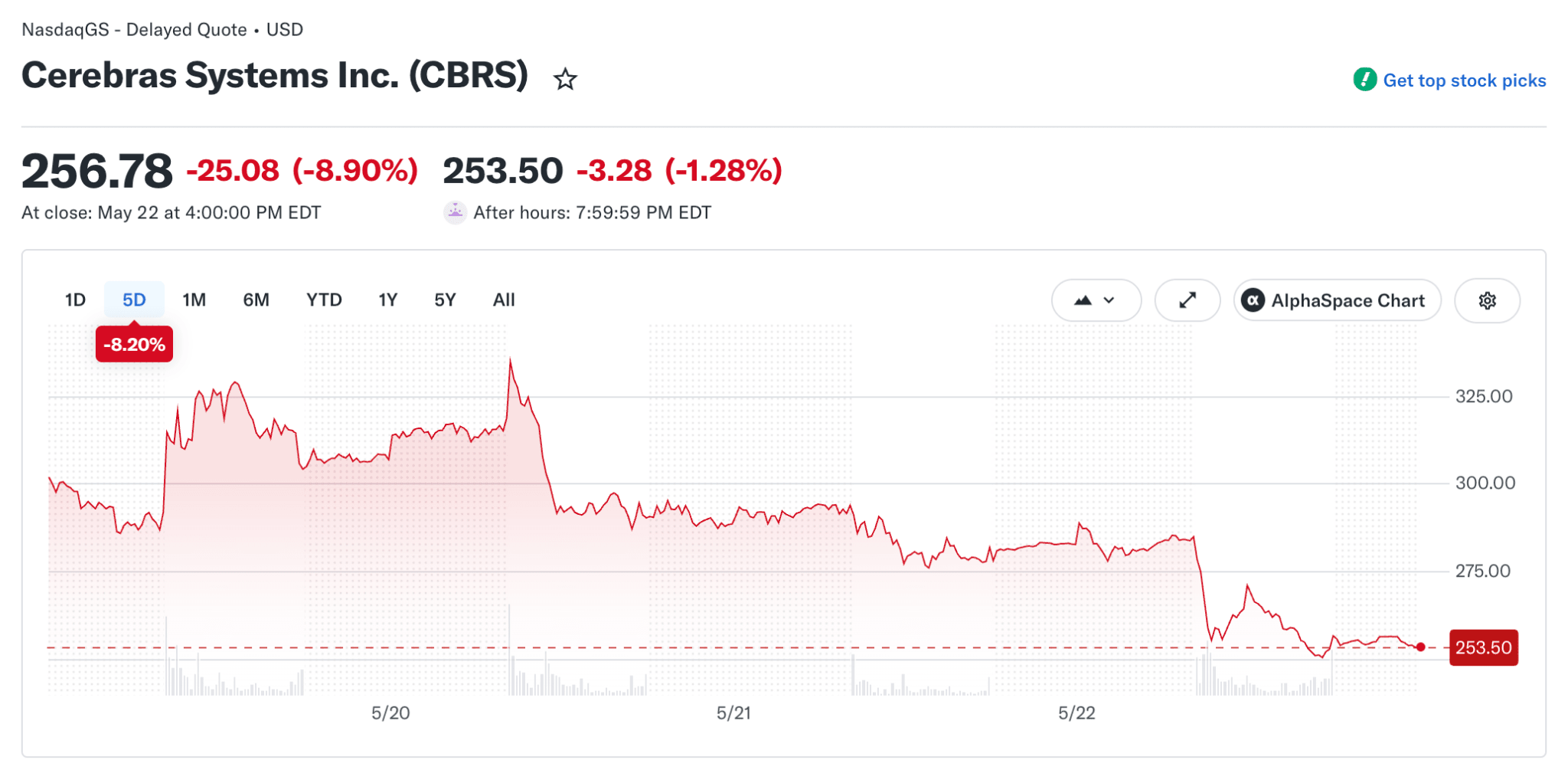
The same shift is visible on the stock market. Cerebras went public, and its CFO Bob Komin said directly that the company serves trillion-parameter models, including internal OpenAI 5.4 and 5.5 models.
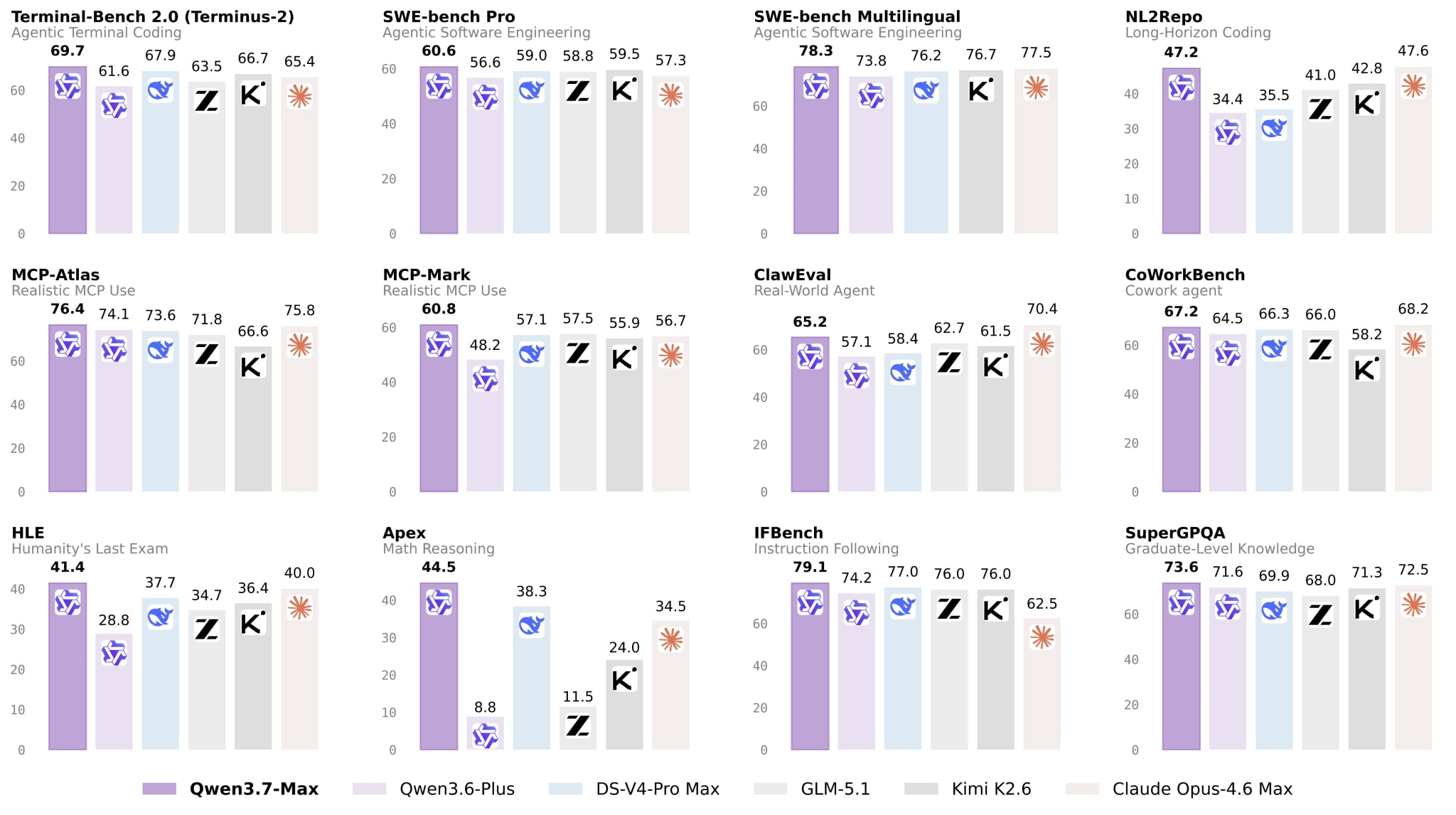
Against the backdrop of cheap open models, Qwen3.7-Max stands apart. Preview versions of Max and Plus appeared on Arena, and Max took fifth place at Artificial Analysis, roughly on par with GPT-5.4 in xhigh mode and slightly above Gemini 3.5 Flash. It sounds like another open-weight victory, but it is not: Alibaba historically does not open the Max series, and this one is unlikely to be an exception. Among the notable weaknesses: the model is verbose and burns through tokens, so its “cheapness” may turn out not to be that cheap in practice.
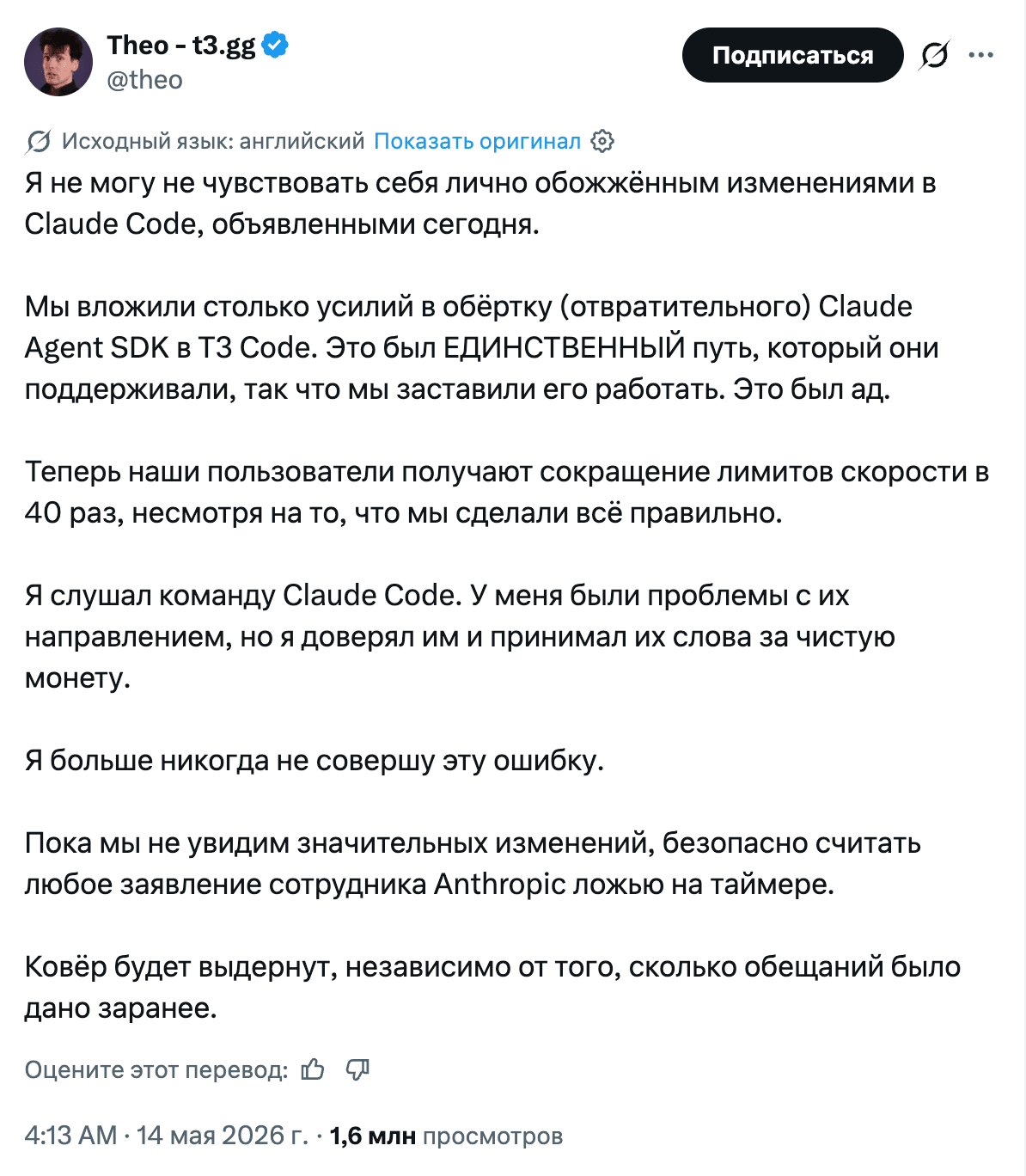
Anthropic had a nervous month. Starting June 15, paid Claude plans receive a separate credit pool for programmatic use: Agent SDK, claude -p, GitHub Actions. Formally, this is a “clarification of limits”; in practice, it is a quiet downgrade: developers calculated that the practical value of the automation tier fell from roughly $2,000 worth of tokens to $200. The reaction was predictably loud, a wave of cancellations followed, and Anthropic responded by raising weekly limits by 50% until July 13 and resetting five-hour limits. A familiar story: first you get people used to generosity, then gently tighten the screws, then roll it back. And all of this against the backdrop of a valuation around $900 billion and a 34.4% share of business customers versus OpenAI’s 32.3%.
Andrej Karpathy joined the Anthropic team, returning to frontier LLM research with a pause in his educational projects. According to Axios, he will work on research automation and a new direction in pretraining. When a person half the industry knows from his educational videos leaves teaching for pretraining, that alone is a signal of where interest has shifted.

The Calif team — Bruce Dang, Dion Blazakis, and Josh Main — together with Mythos Preview found the first public kernel memory corruption vulnerability on Apple’s M5 chip, the very one that bypasses MIE, the hardware memory integrity protection Apple had been building for years. The timeline is sobering: the vulnerability was discovered on April 25, a working exploit was built by May 1 — five days — and by May 14 they were already sitting with it in Apple Park. Target: macOS 26.4.1. Mechanism: a data-only privilege escalation chain from a regular user to root via system calls. This is not a one-off trick: the same Mythos, over the course of a month, helped find more than ten thousand critical vulnerabilities as part of Project Glasswing and became the first model to pass both AISI cyber ranges. The defense took five years to build and five days to bypass. In this pair, the sword side is still accelerating faster than the shield side.
An interesting question: if a “cheap” model burns twice as many tokens on a task, is it still cheap?
Stay curious.


