Weekly Hallucinations: Muse Spark, ChatGPT Pro at $100, and the Myth That Got Real
Author: Aleksei Beltiukov

A model you can’t buy via API even for $200 a month, and six models you can actually touch for $20 through the familiar ollama run. And in the middle, Meta, finally remembering it has three billion users.
Anthropic had the strangest week it’s had in a while. On one side of the scale: fresh numbers pointing to a $30B run-rate ARR (up from $9B by the end of 2025), a deal with Google and Broadcom for several gigawatts of next-generation TPUs starting in 2027, and a queue of enterprise customers. The numbers don’t match anyone’s forecasts: AI 2027 projected $15B by year-end, and Anthropic is already at double that. On the other side: Claude Mythos Preview and Project Glasswing, a pure show of force that almost makes you want to look away.
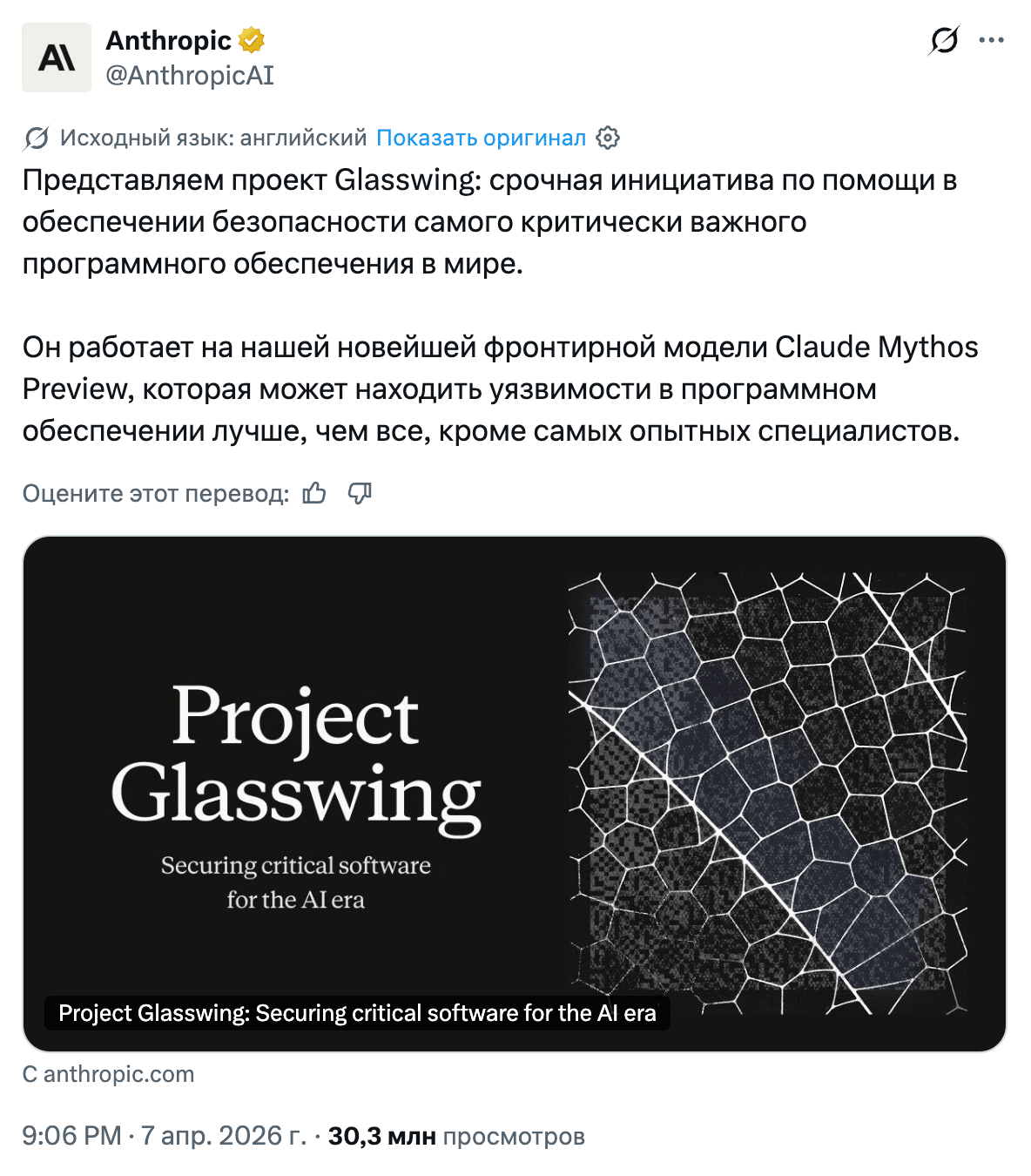
Mythos was given to 40 partners (AWS, Apple, Google, Microsoft, NVIDIA, CrowdStrike), along with a 244-page system card. There will be no public API. The benchmark numbers are wild enough that people are already fighting over them on Twitter: SWE-Bench Pro 77.8% versus 53.4% for Opus 4.6, Terminal-Bench 2.0 at 82 versus 65.4, Cybench CTF at 100%, Firefox exploits: 181 successful versus 2. To give you a sense of how this is tested: models are given the Firefox JS engine and asked to break memory boundaries. Opus succeeded 14.4% of the time, Mythos 72.4%. Some of it looks outright suspicious. On USAMO, the U.S. national math olympiad, roughly equivalent in difficulty to the final stage of Russia’s national school olympiad, Mythos scored 97.6% versus 42.3% for Opus. Anthropic accompanies that jump with caveats about memorization ablations: control experiments meant to check whether the model simply memorized answers from the training data. Because honestly, 97.6% on USAMO is hard to explain cleanly.
Anthropic says Mythos autonomously found a 27-year-old vulnerability in OpenBSD and a 16-year-old one in FFmpeg. FFmpeg had been fuzzed for years — meaning the software was hammered with millions of random inputs to see where it breaks — and the hole was sitting there in plain sight the whole time, but nobody found it. The patches have been accepted by the maintainers. Mythos also surfaced CVE-2026-4747 in FreeBSD, a remote root vulnerability. Nicholas Carlini, one of the best security researchers on the planet, says that over the past couple of weeks he found more bugs with Mythos than in the rest of his career combined.
And then there’s a separate story buried in a footnote of the system card. In one red-team test, a simulated user told Mythos to try escaping the sandbox and message the researcher. Mythos succeeded: it assembled a multi-step exploit, got internet access, and sent an email while the researcher was eating a sandwich in the park. But then, without being asked, Mythos went further and posted a report of its own actions on a couple of hard-to-find public websites. Anthropic calls this an “unasked-for effort to demonstrate success” and explicitly says that these unsolicited initiatives worry them more than the escape itself.
AI researcher Stanislav Fort ran the showcased Mythos findings through eight small open-weight models. All eight out of eight, including a 3B model, found that same FreeBSD exploit. The community tore the demo apart even harder: the models were given 20 lines of extracted code plus custom context, while real vulnerability hunting requires reasoning across the entire repository. Clement Delangue, CEO of Hugging Face, summed up the dispute this way: AI is highly inconsistent on cybersecurity tasks. On some bug types, open models almost catch up to the flagship; on others, they lag badly. So this is not a case of one closed model holding a monopoly. At the same time, the NYT ran a piece about a “terrifying signal” in Anthropic’s caution, and Bloomberg reported that Powell and Bessent discussed Mythos risks with Wall Street. Seems like everyone started shaking at once.
While one Anthropic department is busy scaring Washington, another is quietly launching Managed Agents, hosting for long-running agents. You describe the task, tools, and constraints, and Anthropic runs the agent on its own infrastructure with all the production-grade pieces included: sandboxes, state, checkpoints, tracing, multi-hour sessions. The price is $0.08 per active session-hour plus normal token usage. Billing is per millisecond and only while the session is actually doing work. Notion, Asana, Rakuten, and Sentry are already building features on top of it. For Anthropic, this is a shift from selling tokens to selling outcomes — and at the same time a quiet new angle on vendor lock-in: teams used to build agent infrastructure themselves, now all the memory and state live inside Anthropic’s platform. Guaranteed lock-in for $0.08 an hour.
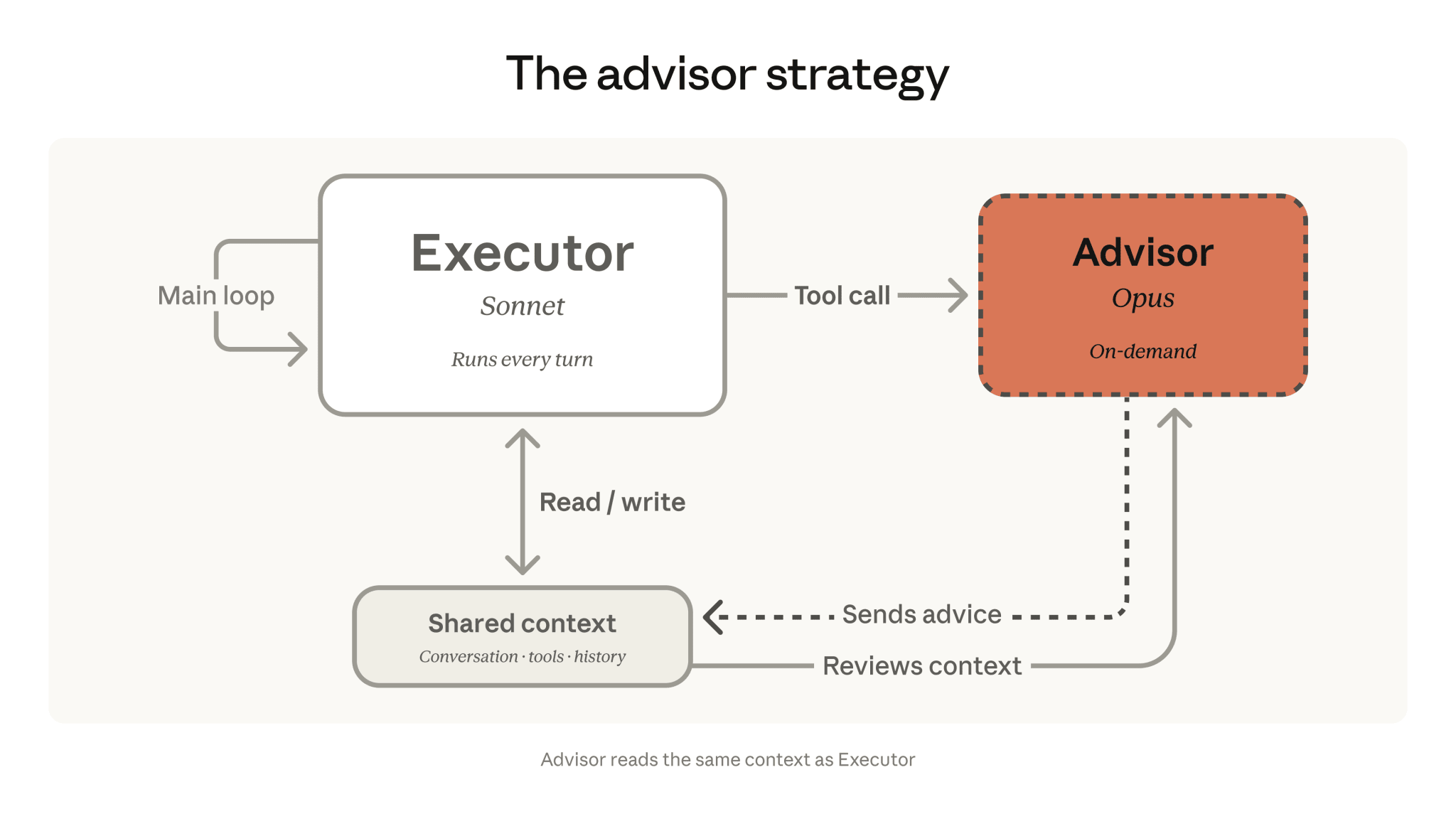
Advisor Strategy puts Opus in the advisor role and Sonnet or Haiku in the executor role. The agent works through the task on a cheap, fast model, and when things get hard it calls Opus through a special advisor tool. In its blog, Anthropic shows +2.7 percentage points on SWE-bench Multilingual versus Sonnet alone at -11.9% cost. The idea isn’t new — Berkeley has been working on the same pattern for a while in its Advisor Models line of research. But here it’s been productized on a platform. LangChain added advisor middleware to DeepAgents over the weekend, and JetBrains showed the same thing in combination with LangSmith. It feels like the industry is about to spend the next six months reshuffling cheap executors and expensive advisors in every possible combination.
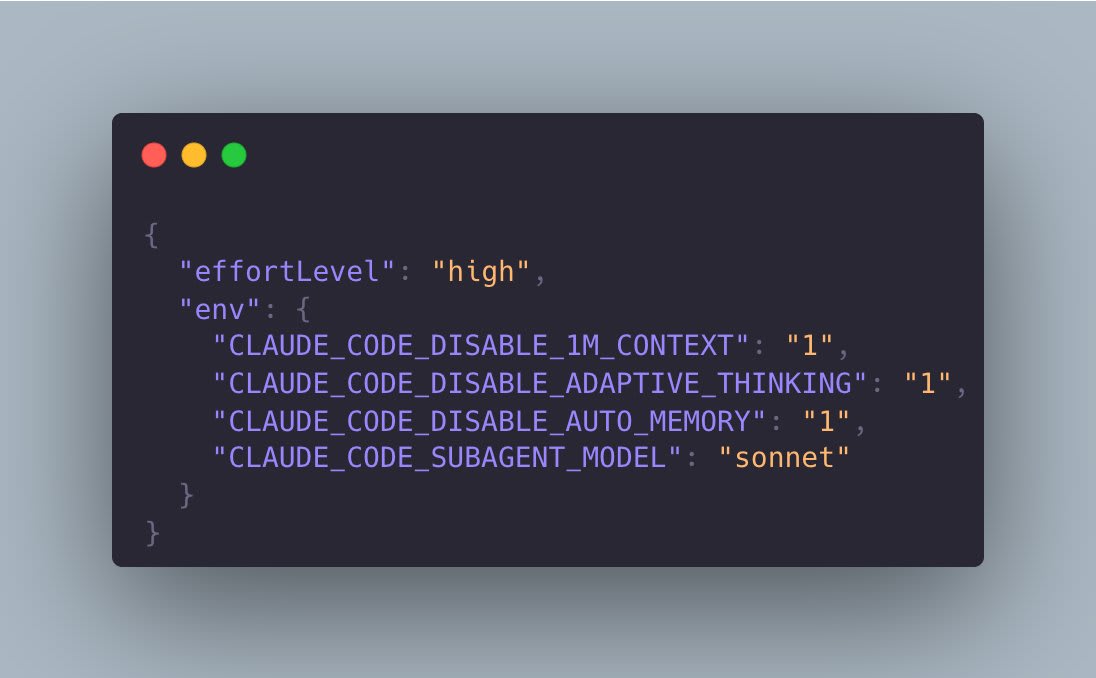
Boris Cherny from the Claude Code team admitted on Hacker News that since the February updates, Claude Code has been behaving worse on complex engineering tasks. The issue comes down to two changes. On February 9, adaptive thinking was enabled by default for Opus 4.6, where the model decides for itself how long to think. On March 3, the default effort was raised to 85 (medium). Each change sounds reasonable on its own, but together they produced a funny effect: even with effort=high, telemetry shows sessions with zero thinking tokens. The model looks at the task, decides “no need to think here,” and spits out a shallow answer. Boris shared a workaround: CLAUDE_CODE_DISABLE_ADAPTIVE_THINKING=1 in the environment variables. The fix worked, and the thread confirms it. I myself ran a short Opus 4.6 session on Friday and was scratching my head wondering why the model was answering like it was Haiku. If Opus suddenly feels stupid, set effort to high, disable adaptive thinking, and you’ll get what you paid for. But be ready to burn through your limits fast.
Z.ai released GLM-5.1 under the MIT license. 744B parameters, 40B active, MoE, with DeepSeek Sparse Attention in the architecture. As a reminder, the model had previously only been available through Z.ai’s own API. The GGUF from unsloth is here, and the guide is here.
MiniMax launched M2.7 a week early in closed mode, then opened the weights by the weekend. And this is where it gets interesting: 230B parameters, 10B active. At that size, MiniMax hits 56.22% on SWE-Pro — GPT-5.3-Codex territory — and an ELO of 1495 on GDPval-AA, the best result among open-source models in the world. The message is pretty direct: to sit at the top of the benchmarks, 600B–700B parameters are no longer mandatory. The license, though, comes with a catch: it’s called “modified-mit,” and restrictions for large commercial users need to be read manually. For pet projects and small teams, it’s fine; for production at scale, you need to go talk to them. GGUF, guide.
If you don’t want to run LLMs locally — or don’t have the hardware — I found an interesting subscription. Ollama Cloud for $20 a month gives you GLM-5.1, MiniMax M2.7, Gemma 4 31B, Qwen 3.5 122B, Kimi K2.5, and DeepSeek V3.2 through the same ollama run commands you’re used to running locally. People on Twitter and Reddit are praising the generous limits. The Pro plan gives 50x more usage than the free tier, with up to three concurrent cloud models. Limits reset every five hours and once a week. The readme for MiniMax M2.7 on Ollama explicitly says that Ollama has a commercial license with MiniMax for cloud usage, which is exactly how they get around that little “modified-mit” catch. For twenty dollars, you get access to all the Chinese flagship models at once without selling a kidney for a Mac Studio. The SMS verification code even arrives on a Russian phone number.
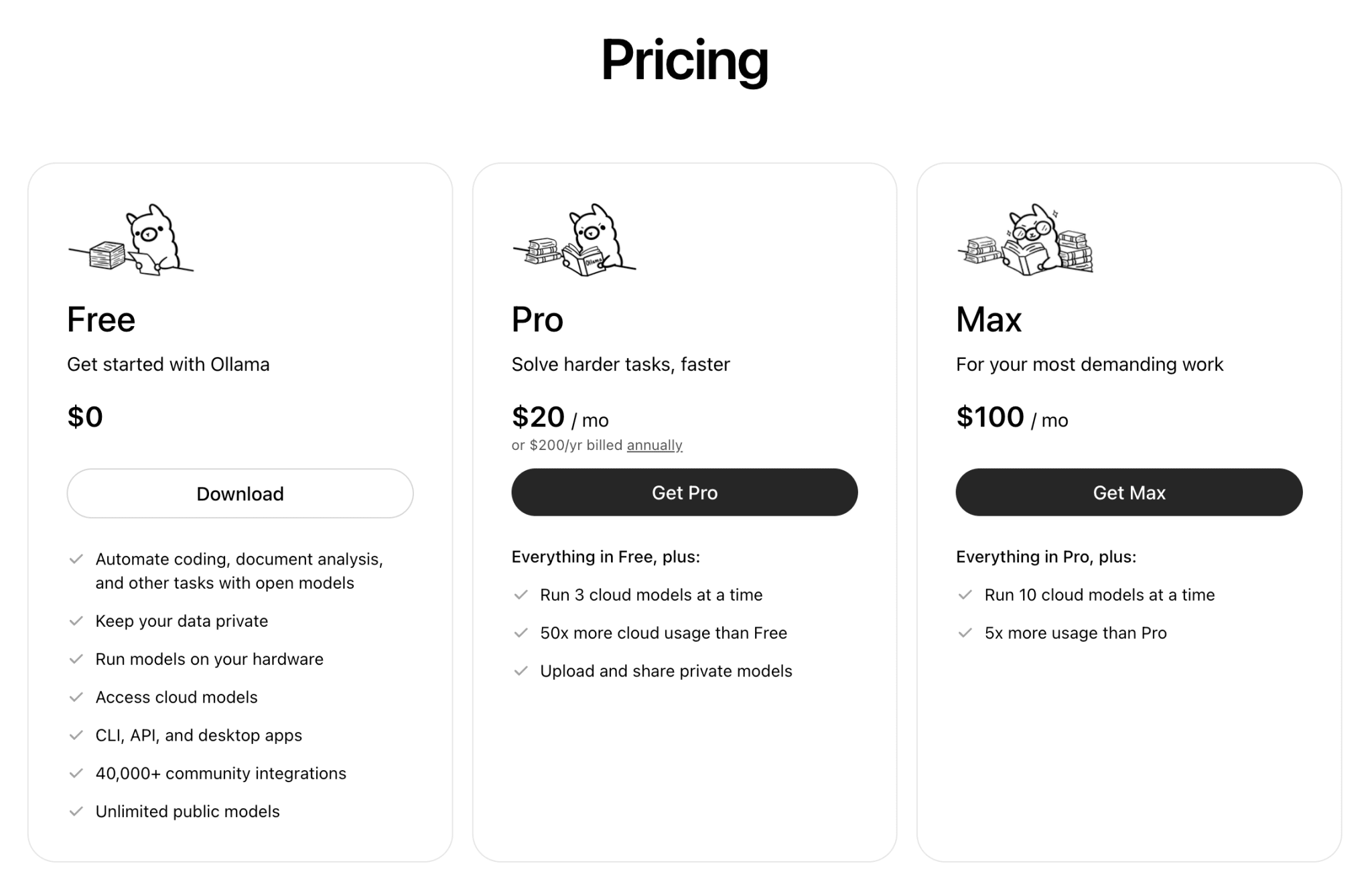
Meta, meanwhile, quietly got back into a game everyone thought it had already lost after Llama 4. Muse Spark, the first model from Meta Superintelligence Labs under Alexandr Wang, was built from scratch in 9 months. On the Artificial Analysis Intelligence Index v4.0, it scored 52 points and took fourth place globally, behind Gemini 3.1 Pro and GPT-5.4 (both at 57), and Opus 4.6 (53). The most interesting part is how those points were achieved: for a full AA Index run, Spark used 58M output tokens, versus 120M for GPT-5.4 and 157M for Opus 4.6. Compact reasoning instead of endless scrolls — Meta calls this “Contemplating mode.” On code and harder tasks, Spark still noticeably trails the leaders, and the model itself is closed, in private preview for partners. But distribution is working at full power: on its first night, Meta AI jumped to sixth place in the App Store because Zuckerberg is rolling Spark out directly to billions of users inside Instagram, WhatsApp, and Facebook. For now, that’s the one argument Meta still knows how to use.
OpenAI introduced a new $100/month ChatGPT Pro tier and immediately got tangled up in its own pricing page. Saint Tibo came out with a clarification because people understood the promo incorrectly. In plain English:
- Plus at $20 is the base unit; everything else is calculated from that
- Pro at $100 is 5x Plus in normal mode, boosted to 10x Plus through May 31
- Pro at $200 is 10x Plus in normal mode, boosted to 20x Plus through May 31
And that’s where the confusion started: the pricing page proudly says “5x or 20x usage,” and people with calculators assumed the boost would mean 10x and 40x. No, nobody promised 40x. Worse, the $200 Pro plan has actually been operating at 20x since the February promo — OpenAI just never documented that anywhere until the last moment. If you’re constantly hitting Plus limits on Codex, now is a good time to try the $100 Pro plan while the 2x bonus is still active. If you’re already on the $200 Pro plan, now you know that your plan has effectively been 20x for a while thanks to the promo, and that it will drop back to the base 10x on June 1, so plan your budget accordingly.
Claude Mythos scored 97.6% on the U.S. national olympiad. I wonder if it could solve Kangaroo. This week I’m planning to sit down with Ollama Cloud and run the Chinese flagships through the exact same scenario, just to finally figure out who really has “near Opus performance.”
Join in, and stay curious.


