Weekly Hallucinations: Claude Opus 4.7, Qwen 35B-A3B, and the end of pull requests

While Twitter argues about whether Opus got smarter or not, Codex has already moved into your Mac, and Hermes is quietly turning into a full-fledged alternative to OpenClaw in the background.
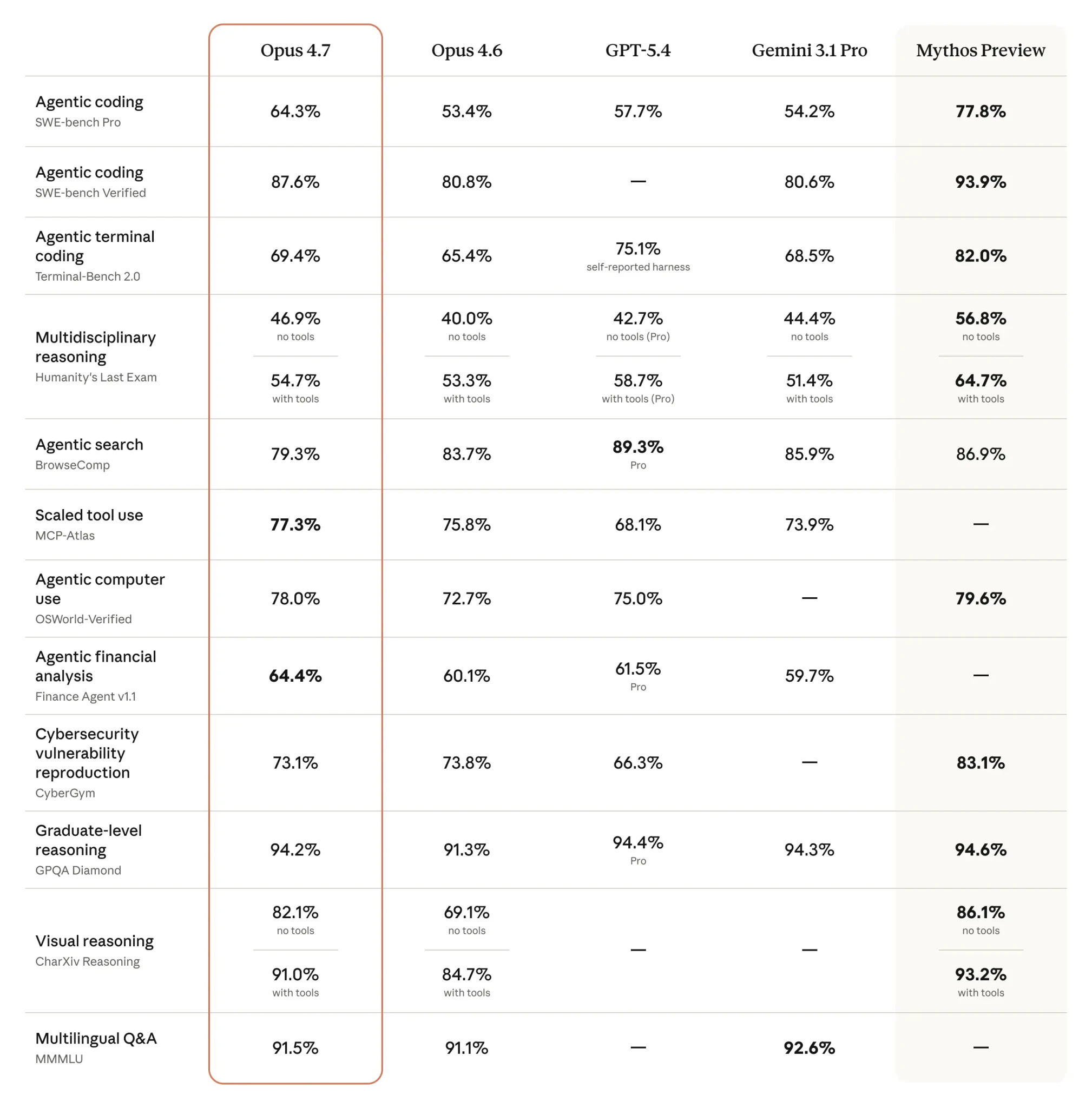
This week, Anthropic released Claude Opus 4.7. They promise better performance on long-running tasks, coding, instruction-following, and self-checking. Pricing stays the same, $5 / $25 per 1M input and output tokens. A new reasoning effort level, xhigh, appeared alongside it, sitting between high and max. Claude Code now defaults to xhigh, which is a hint that the model is tuned more for “pour and walk away” workflows than for pair programming. Personally, I spend 80% of my time on medium and occasionally switch to high.
The benchmark picture looks lively. SWE-bench Pro at 64.3% (+11 versus 4.6), SWE-bench Verified at 87.6% (+7), TerminalBench 2.0 at 69.4%. According to Artificial Analysis, the Intelligence Index now has an almost dead-even top three: Opus 4.7 at 57.3, Gemini 3.1 Pro at 57.2, and GPT-5.4 at 56.8. On its internal benchmark, Cursor jumped from 58% to 70%, while Notion got a +14% quality boost and cut tool errors to one-third.
At the same time, Anthropic showed off Claude Design. It is a research preview that generates prototypes, slides, and landing pages from text descriptions, with export to Canva/PPTX/PDF/HTML and handoff into Claude Code. Twitter immediately compared it to Figma, Lovable, and v0, and Figma stock dipped on the announcement. Anthropic has clearly decided that its territory does not end with chat and code.
Opus 4.7 got a new tokenizer, and the same input is now counted as 1.0–1.35x more tokens. Boris Cherny from the Claude Code team quickly raised limits for subscribers, but API users immediately reached for calculators. At the same time, MRCR v2 at 1M tokens dropped from 78.3% → 32.2%. Boris replied that MRCR rewards distractor-stacking tricks and pointed to Graphwalks, where scores improved from 38.7% → 58.6%, as a more useful metric. The independent NYT Connections Extended added more fuel: 4.6 scored 94.7%, while 4.7 (high) fell to 41.0%. The benchmark author clarified that the issue was safety refusals, not reasoning failures; on permitted tasks, the model scores 90.9%. On Twitter, there are two reactions in parallel: some call the new system prompt “lobotomized,” while others say the model is the first one that actually “understands” what they are trying to do.
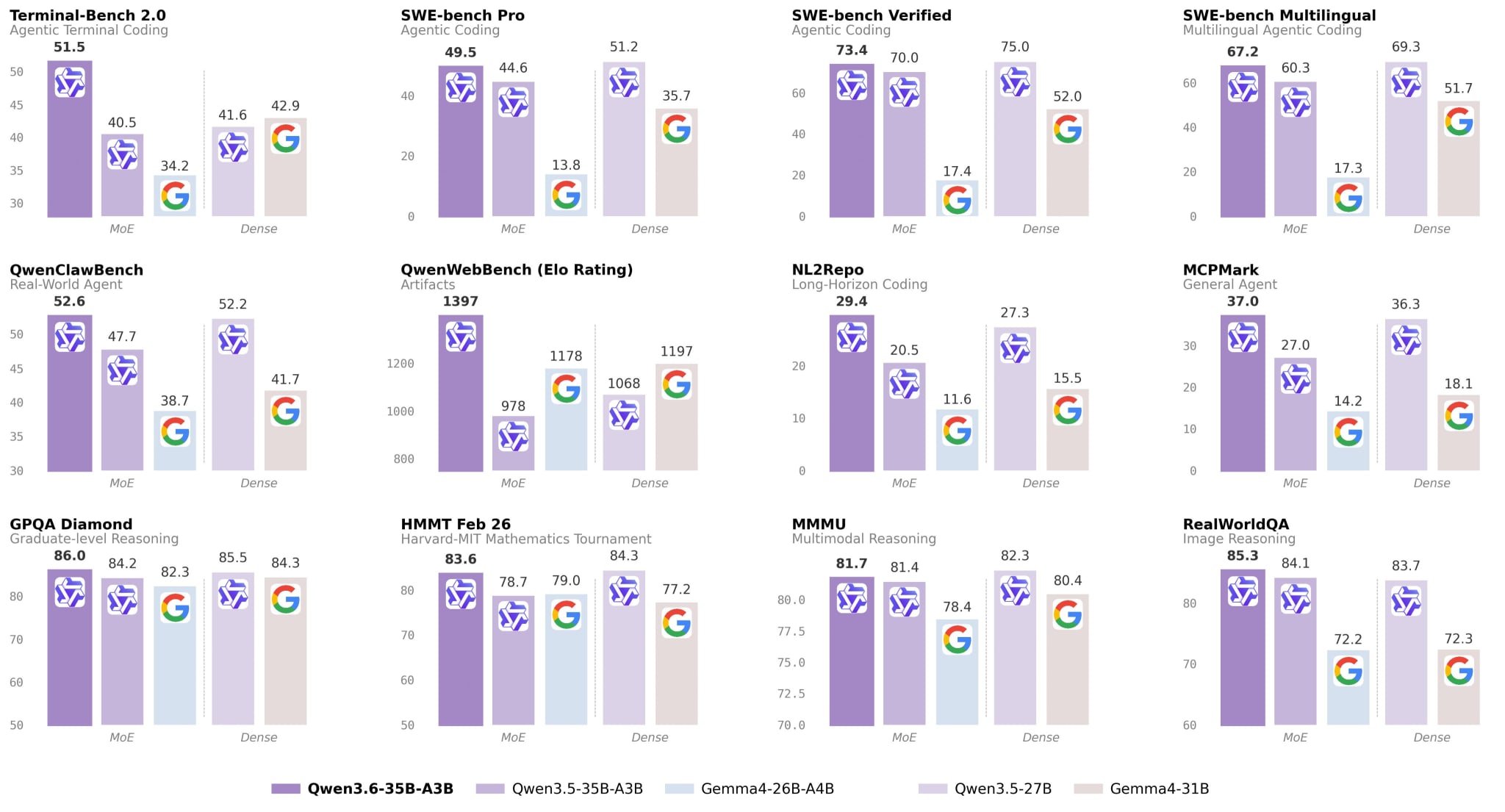
Alibaba released Qwen3.6-35B-A3B — a sparse MoE with 35B total and 3B active parameters, Apache 2.0, with native multimodality. SWE-bench Verified 73.4, Terminal-Bench 2.0 51.5, RefCOCO 92.0. Unsloth showed that the GGUF version runs in 23GB RAM, and a 2-bit variant in 13GB, and in that form it fixes bugs in repos. vLLM and Ollama got support on release day. For the local stack, this is a very important event: a model that used to require a server rack now fits into a laptop and is breathing down the neck of the older kids on agent tasks. GGUF, guide.
This week, OpenAI turned Codex into a full-fledged macOS operator. The update brought computer use on Mac, a built-in browser, gpt-image-1.5, 90+ plugins, multiple terminals, SSH into devboxes, long-running automations, and memory. OpenAI president Greg Brockman explicitly calls Codex an “agentic IDE.” OpenAI itself says it has 3M weekly active users, and nearly half of usage is already not about coding. In the community, people also emphasize that Codex Computer Use works quickly, including with Slack and old enterprise software.
Google rolled out a native Gemini app for Mac. Activation via Option + Space, access to the screen and local files, built in native Swift. On top of that, Personal Intelligence launched globally across Gemini and Chrome, with the ability to connect Gmail and Google Photos. Technically, the more interesting piece is Gemini 3.1 Flash TTS: Audio Tags, 70+ languages, nonverbal cues directly in the text, multi-speaker support, and SynthID watermarking. Artificial Analysis places it at #2 in Speech Arena, only 4 Elo behind the leader. If Anthropic moved onto Figma’s turf, then Google simultaneously moved into Notion, Apple Intelligence, and ElevenLabs territory.
Cloudflare introduced Project Think, a next-generation Agents SDK with durable execution, sub-agents, isolated code execution, and a built-in workspace file system. On top of that came Agent Lee, an agent directly inside the dashboard, which uses isolated TypeScript to replace manual tab navigation with prompt-driven operations. Cloudflare keeps selling the same thesis over and over: an agent in production grows out of the combination of a durable runtime, UI grounding, browser access, voice, and a sandbox.
On the same day, OpenAI opened its own Agents SDK and decoupled the harness from compute. The harness is now open-source, and execution can be handed off to a partner sandbox. Within hours, integrations were announced by Cloudflare, Modal, Daytona, e2b, and Vercel. The pattern is the same everywhere: a stateless orchestrator plus stateful isolated workspaces. In the same motion, LangChain rolled out deepagents 0.5 with asynchronous sub-agents, multimodal file handling, and improved prompt caching, while deepagents deploy is positioned as an open alternative to managed hosting for agents.
Hermes Agent keeps evolving. Nous released v0.9.0 with a web dashboard, fast mode, backup and import, strengthened security, iMessage/WeChat support, and Android support via tmux. hermes-lcm v0.2.0 added lossless context management with DAG summaries. Ollama added native support for Hermes via ollama launch hermes. On GitHub, the project already has 104k stars, even though the repo has only been riding the hype for a couple of months. Hermes’ key feature is that it turns a completed workflow into a reusable Skill. One interesting example from Twitter: the agent loaded a skill on its own, diagnosed NaN instability in Gemma 4, patched a library, ran benchmarks, and published the artifact on Hugging Face.
OpenClaw creator Peter Steinberger spoke at TED and AIE with two versions of the project’s story. For the public, he told the story of the fastest-growing open-source project in history. For engineers, he gave a more sober version: they have 60 times more security reports than curl, and at least 20% of contributions to skills were malicious. The project actually worked — and in doing so, turned into one of the most attacked supply chains in the industry. It is hard not to see the parallel with Hermes, where strengthened security appears as a separate item in the changelog: open-source agent stacks are becoming legitimate attack targets.
For the first time, GitHub allowed pull requests to be disabled in open-source repos, against the backdrop of Peter and several other prominent maintainers having pushed the idea of Prompt Requests instead of Pull Requests for the past couple of years. The logic is simple: no merge conflicts, it is easier for a maintainer to fix a prompt than someone else’s code, and there is less chance that malicious code sneaks in under an innocent-looking PR. In Building for Trillions of Agents, Box CEO Aaron Levie states the endgame plainly: "the path forward is to make software that agents want." Git was invented for humans, and if code starts being written and reviewed by non-humans, then the delivery format itself stops making sense. The question now sounds different: how much longer can git itself hold on?
When OpenAI says that half of Codex usage is not about code, I recognize myself in that number. For several months now, I have had tasks spinning inside Claude Code and Codex that I would usually never get around to, and that is exactly where the agent has been most useful. At some point, I catch myself realizing that an agent helps you most not where you are strong, but where your patience usually runs out.
Stay curious.


