Weekly Hallucinations: Claude Capybara, GigaChat-3.1, LiteLLM Key Theft, and CLI for Everything
Author: Aleksei Beltiukov

Anthropic is leaking in both directions: Capybara outward, and Claude Code users toward competitors. Meanwhile, Stripe is building a CLI, Intel is making cheap GPUs, and Sora is pretending it never existed.
It was a week of contrasts for Anthropic. Fortune reported a leak of a new tier, Capybara, which supposedly sits above Opus 4.6 in the model hierarchy. According to the leaked information, Capybara performs better in coding, academic reasoning, and cybersecurity. There’s no official confirmation, but on the same day someone found a page for "Claude Mythos" on the website, which was quickly taken down.
Against the backdrop of all these ambitions, Claude Code users staged a small revolt. Starting March 23, people on Max plans began burning through 80–100% of their limits in minutes instead of the usual 20–30%. One person wrote that the word "hey" cost them 22% of their usage. I’m on a Max plan myself and noticed the spike in consumption, and on Saturday the promotion with double off-peak limits ended. Anthropic stayed silent for two days, then on March 26 acknowledged: "we are adjusting our 5-hour limits for Free/Pro/Max subscriptions during peak hours." Yeah. At that point, all that’s left is to cry.
Figma opened the beta of its MCP server, and this is the first convincing example of tool-calling as a product feature rather than a wrapper around chat. Agents can now edit design directly on the canvas. Cursor plugged in immediately: generating components based on a team’s design system, straight from the IDE into Figma. GitHub showed that this also works through Copilot CLI. It looks like the future, where designers and developers communicate not through Jira tickets, but through an agent with access to both tools.
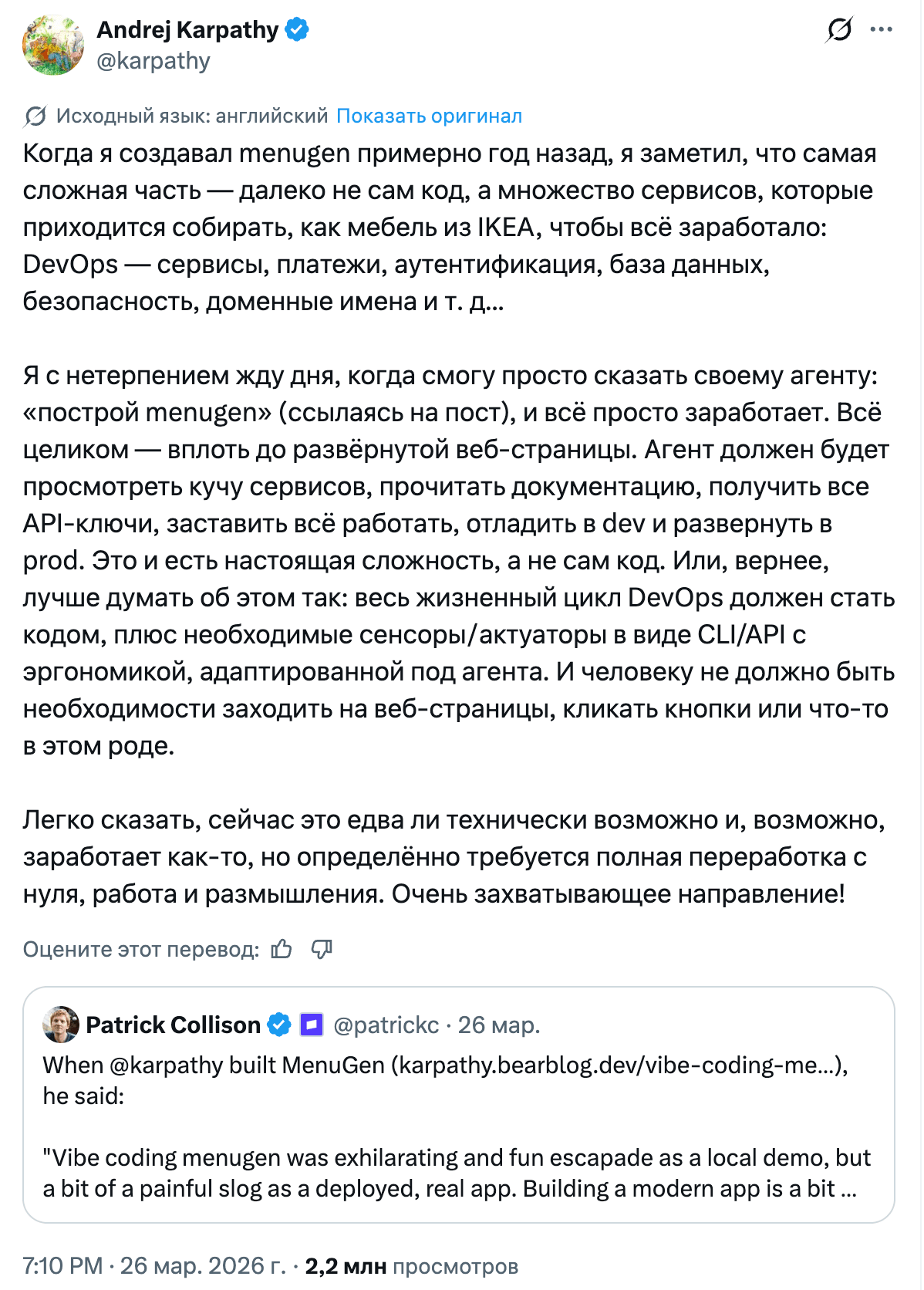
But the week’s most unexpected trend was probably CLI. Stripe launched Projects.dev: you type stripe projects add posthog/analytics, and it automatically creates a PostHog account, generates an API key, and sets up billing. Patrick Collison cited Andrej Karpathy as the inspiration: backend service provisioning is too hard for agents. And on the same day, CLIs from Ramp, Sendblue (iMessage), and ElevenLabs dropped, while Visa, Resend, and Google Workspace had released theirs a bit earlier. CLI is coming back, and this time not for humans, but for agents. The irony is that MCP, which was supposed to become the universal protocol for connecting tools, is losing to plain old stdin/stdout on simplicity and reliability. It also eats context.
For those already running multiple agents in parallel, Cline released Kanban, a free open-source tool for orchestrating coding agents. Each agent runs in an isolated git worktree, tasks are arranged by dependency, and diffs can be reviewed from a single board. It supports Claude Code, Codex, and Cline. Developers who tried it say it solves the two main pains of multi-agent workflows: waiting on inference and merge conflicts.
LiteLLM versions 1.82.7 and 1.82.8 on PyPI turned out to be compromised. The malicious code was hidden in a .pth file, which Python executes automatically when the interpreter starts. No import litellm needed. The payload collects SSH keys, AWS/GCP/Azure credentials, Kubernetes configs, crypto wallets, and shell history, encrypts everything with AES-256 + RSA-4096, and sends it to models.litellm.cloud (not to be confused with the real litellm.ai). No social engineering required. As a bonus, if the machine has a Kubernetes service account, the malware tries to create a privileged pod on every node in the cluster.
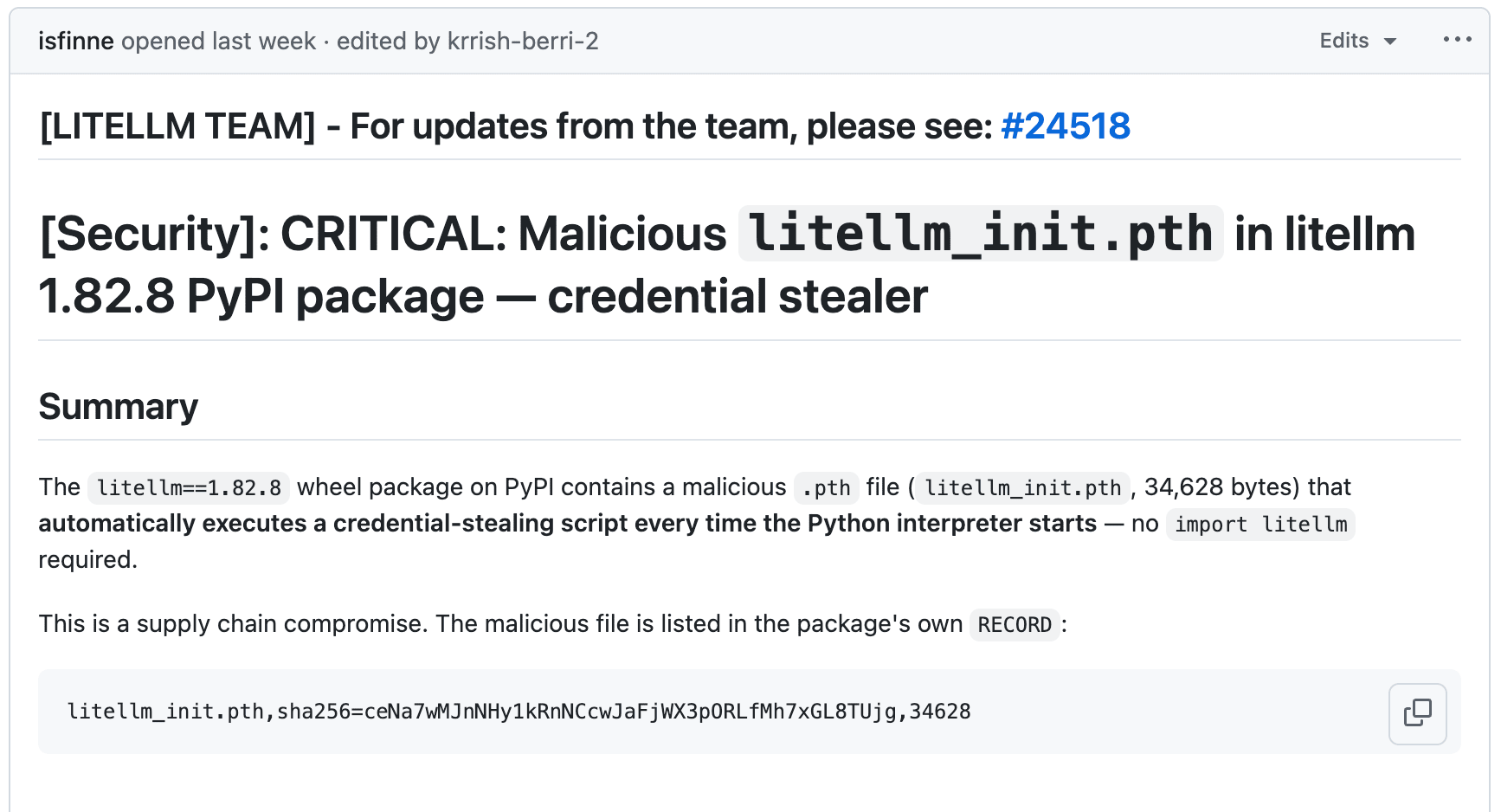
Andrej Karpathy gave the most detailed breakdown: in an agentic world, the entire filesystem becomes part of the attack surface. FutureSearch uncovered an attack where LiteLLM was pulled in as a transitive dependency through an MCP plugin in Cursor. A bug in the malicious code itself — a fork bomb caused by recursive .pth execution — crashed the machine and drew attention to it. The versions were revoked, the PyPI quarantine was lifted, but everyone who updated on March 24 should rotate their credentials.
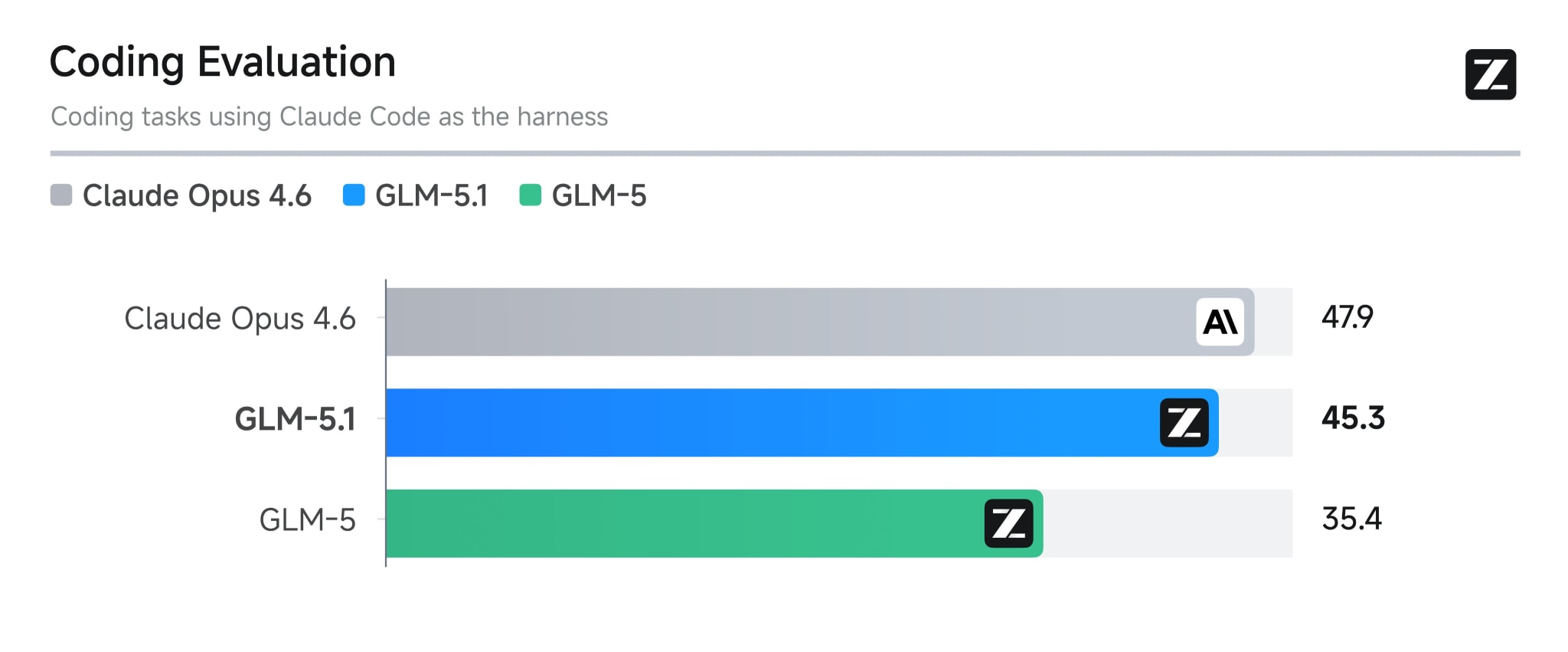
Zhipu released GLM-5.1, yet another Opus killer, for all users on the GLM Coding Plan. It scores 45.3 on a coding eval (for comparison, Opus 4.6 gets 47.9). The gap between open and closed coding models is shrinking literally every week, and GLM-5.1 is another confirmation of that. Maybe someone here is already using coding plans from Chinese providers — if so, I’d be curious to hear what your experience has been like.
AI Sage published GigaChat-3.1 on Hugging Face: Ultra at 702B (MoE) and Lightning at 10B with 1.8B active parameters. They’re optimized for Russian and English. Lightning looks interesting for local inference; if the benchmarks are to be believed, it scores 0.76 on BFCLv3. The comments on Hugging Face are still cautious: the geopolitical context and questions about the training data haven’t gone away. Also, I was put off by the fact that in its benchmarks, GigaChat-3.1 is compared to last year’s models (Qwen3, gemma-3, DeepSeek V3).
Google rolled out Gemini 3.1 Flash Live, a model for real-time voice and visual agents. 70 languages, 128k context, SynthID watermarking. It scores 95.9% on Big Bench Audio at a high reasoning setting (time-to-first-audio 2.98s) and 70.5% at a minimal reasoning setting (0.96s). It’s available in Gemini Live, Search Live, and AI Studio.
Speech models in general are getting denser by the week: in the same period, Mistral released Voxtral TTS (3B parameters, 9 languages, ~90ms first audio, outperforming ElevenLabs Flash v2.5 in preference tests), while Cohere published Cohere Transcribe under Apache 2.0, with the best English WER (5.42) among open models.
OpenAI, meanwhile, is shutting down Sora. The official account thanked users and promised "details on the timeline." On Reddit, people say the product was financially unsustainable, and creators had long since moved to Runway and Kling. Resources are being redirected toward coding and enterprise. Sora lasted less than a year. Disney invested $1B and licensed 200+ characters, and even that didn’t help. For the open-source community, the takeaway is simple: local solutions don’t get shut down by a board decision.
Google Research introduced TurboQuant at ICLR 2026: 6x KV-cache compression with no accuracy loss, and inference speedups of up to 8x on H100. It works through a combination of PolarQuant (mapping to polar coordinates to eliminate normalization overhead) and QJL (1-bit error correction via Johnson-Lindenstrauss). There are already forks for vLLM and llama.cpp, and people are running Qwen 3.5-9B with a 20K-token context on a 16GB MacBook Air M4. But the methodology is being challenged: the authors of RaBitQ accuse Google of unfair benchmarks, including CPU-vs-GPU comparisons. Here’s an interesting write-up.
Intel released the Arc Pro B70: 32GB GDDR6, $949, 602 GB/s bandwidth, 290W. For context, the NVIDIA RTX 4000 PRO costs more and only gives you 24GB. Intel had support from vLLM lined up from day one. Four cards for $4,000 gets you 128GB of GPU memory, enough for local inference on 70B models. Of course, there are caveats: the B70’s int8 TOPS (367) trails the RTX 4000 PRO (1290) by a lot, there’s no CUDA, and Intel’s driver support has historically raised questions. But in terms of price per gigabyte of VRAM, this is one of the best deals available right now if you want to run large models locally. I’d keep an eye on it if they start shipping these to Russia.

ARC Prize launched ARC-AGI-3, a benchmark where humans solve 100% of tasks, while frontier models still fail to reach 1%. Interactive environments, scoring based on efficiency relative to humans, and a prize pool of $2M+. The creator emphasizes: the benchmark measures zero-preparation generalization, not the ability to build a specialized harness. Critics point to the strictness of the scoring protocol and the unclear comparability with previous ARC versions, but even skeptics agree: current LLM agents perform poorly in interactive environments with minimal feedback.
An interesting question: if a .pth file executes every time the Python interpreter starts, and your agent launches Python 50 times an hour, how many times a day will your credentials get sent to someone else’s server? The correct answer is: once is enough.
Stay curious.


