Prompt Caching: The Optimization That Fails Silently
Author: Aleksei Beltiukov
TL;DR: Prompt caching reuses the already processed beginning of a prompt: the provider stores internal computations (KV tensors), repeated input tokens cost roughly 10 times less, and the response arrives faster. The cache works only when the prefix matches exactly, so the main rule is: stable content at the beginning, changing content at the end. A cache breakage does not produce errors; you can see it only in the API usage fields.
Of all the ways to save money when working with LLMs, prompt caching is the most treacherous. It is not difficult; the issue is different: it is silent. Almost any optimization, if you break it, makes itself known: a test fails, a log turns red, a metric collapses. Cache does not do that. It does not fail with an error; it simply stops working silently. And the only things that change are the bill at the end of the month and a couple of extra seconds for every response.

I am building my own agent on top of OpenAI models, and for quite a long time I did not think about cache at all. OpenAI enables it automatically, without a single flag, and does not charge for writes. Perfect conditions for relaxing. It seems there is nothing to think about; the provider will do everything for you. The trap is exactly in that convenience: automatic cache removes the work from you until the moment when you, with the best intentions, add a couple of useful lines to the prompt and silently break it. Nobody will tell you about it.
The good news: the entire discipline of caching comes down to one simple rule: stable content at the beginning, changing content at the end. The bad news: the rule is fragile, easy to violate, and in agents the cost of the mistake is higher than it seems. Next, we will unpack what prompt caching really is, how the three providers differ, what a correctly assembled prompt looks like, and how to make sure the cache is actually working rather than merely existing in the documentation.
Why cache is oxygen for agents, not a bonus
To understand why cache is critical for an agent, you need to remember how an agent is structured. The model itself remembers nothing; it is stateless. Memory is maintained by the wrapper. On every turn, it reassembles system instructions, descriptions of all tools, the full history of previous actions, and the fresh input into a single request. Even when the provider stores state itself, as OpenAI’s Responses API does with its previous_response_id, the model does not gain memory: the dialogue lives in the service, but the context is still reread on every turn. This mode saves network traffic, but not prefill, so it does not replace cache. Most of this context, as Lance Martin puts it, is the same from turn to turn, and without cache you pay for it in full over and over again. I covered why this kind of “memory” is expensive computation rather than passive storage in my piece on the anatomy of LLM memory and context engineering.

The imbalance is best illustrated by Manus: for their agent, the ratio of input tokens to output tokens stays around 100 to 1. A short response is preceded by tens of thousands of context tokens, and almost all of them are repeated turn after turn. For an ordinary chat, this is minor. For an agent like mine, which runs in a loop for twenty or thirty turns, it is the main cost item.
This is exactly where cache strikes. For all three major providers, reading from cache costs roughly ten times less than a regular input token. As of June 2026, input for GPT-5.4 at OpenAI costs $2.50 per million tokens, while the same token from cache costs $0.25; at Anthropic, Opus 4.8 is $5.00 versus $0.50; at Google, Gemini 3.1 Pro is $2.00 versus $0.20. And flagship models are getting more expensive: OpenAI’s new GPT-5.5 rose to $5.00 per million input tokens, matching Opus and twice the price of GPT-5.4. But whatever the absolute number is, cache cuts that exact number, and when there are one hundred input tokens for every output token, this discount on the repeated hundred changes the economics of the entire product.
Cache also sharply reduces latency: Anthropic claims response-time reductions of up to 85% on long repeated prefixes, OpenAI around 80%. That is the difference between an agent that responds instantly and one that thinks for ten seconds before every turn, rereading the entire context from scratch.
And all of this overspending, if the cache does not hit, leaks away silently: the agent answers correctly, tests are green, there are no errors, each turn simply costs several times more and takes longer. That is why, for a product built on agents, cache hit rate — the share of input tokens read from cache — stops being a vanity dashboard number and becomes a metric that determines whether the unit economics work. I have a separate breakdown of how the economics of AI-agent products are calculated in general.
Let me show this using my own bills. My agent runs on gpt-5.5, and over the past few weeks it has been spending around $50–70 per day on average. That is with cache working: OpenAI enables it by default.
The agent is stateless, so on every turn the harness sends the entire context again: the system prompt, tools, full history, and fresh input. The request does not shrink; it grows from turn to turn. Cache here means that everything the model already saw on the previous turn is read from cache at one tenth of the price, while I pay full price only for the new tokens of the turn, around ten to twenty thousand.
You can see how much cache carries the bill directly in billing. If you divide the daily bill by all tokens for the day, my average token on gpt-5.5 comes out to about $0.78 per million. Cache reads cost $0.50, regular input costs $5, and the fact that the average is almost pressed up against the cache price means one thing: the lion’s share of tokens goes through as cheap prefix reads. Turn cache off, and that mass goes at $5, while the bill grows by roughly seven times. An ordinary fifty-dollar day would become a day costing several hundred, with the exact same agent behavior: the same answers, green tests, zero errors in the logs.
The same applies to everyday coding on Claude. On Opus, the average token costs around $0.88 per million with the same cache-read price of $0.50 and input price of $5, even though Anthropic also charges for writes. Different provider, different tool, same conclusion: the bill is held together by cache.
| Price per million tokens | gpt-5.4 (OpenAI) | gpt-5.5 (OpenAI) | Opus 4.7/4.8 (Anthropic) |
|---|---|---|---|
| Regular input | $2.50 | $5.00 | $5.00 |
| Cache read | $0.25 | $0.50 | $0.50 |
| My average token (actual billing data) | ~$0.39 | ~$0.78 | ~$0.88 |
What is actually cached, and why one character breaks everything
The first thing that breaks intuition: what gets cached is not the prompt text and not the model’s finished answer. It may seem like a dictionary where a ready-made answer is stored for a request text. That picture is wrong, and because of it, it later becomes unclear why everything is so fragile.
In reality, before producing the first word of the answer, the model reads the prompt, and this reading is not a quick glance but expensive computation: it runs every token through its layers and turns it into a mountain of intermediate numbers. These draft computations are what get stored. They have a technical name: key/value tensors, or KV cache — the internal representation of what has been read. The stage of reading the prompt itself is called prefill, and for long context it is exactly this stage that is expensive and slow; generation of the response token by token happens afterward and is billed separately. Cache allows the model to skip prefill for the part of the prompt it has already seen: the tensors for it have already been computed and are ready. I covered the whole path from tokenization to the first word of the answer in detail in my article on the journey of a prompt under the hood of an LLM.
Each such tensor depends on all the text before it, from the first character of the prompt up to that point. Not on similar text, but on exactly that text, down to the character. Therefore, only the shared beginning of a request — its prefix — can be reused. As soon as something changes at the beginning, all tensors after the point of change are different, and the cache for them is invalid.
The closest analogy is a bookmark in a book that works only if all the text before it has not changed. You can open page 200 and continue from the bookmarked place, but only if pages 1 through 199 remain word-for-word the same. Change one word on page 1, and the bookmark on page 200 is useless: from there on, it is already a different book, and you have to read from the beginning. Cache works exactly the same way. Prefix matching is checked using a cryptographic hash, and a one-character difference produces a different hash and a full miss. This is not a figure of speech and not “well, it almost matched.”
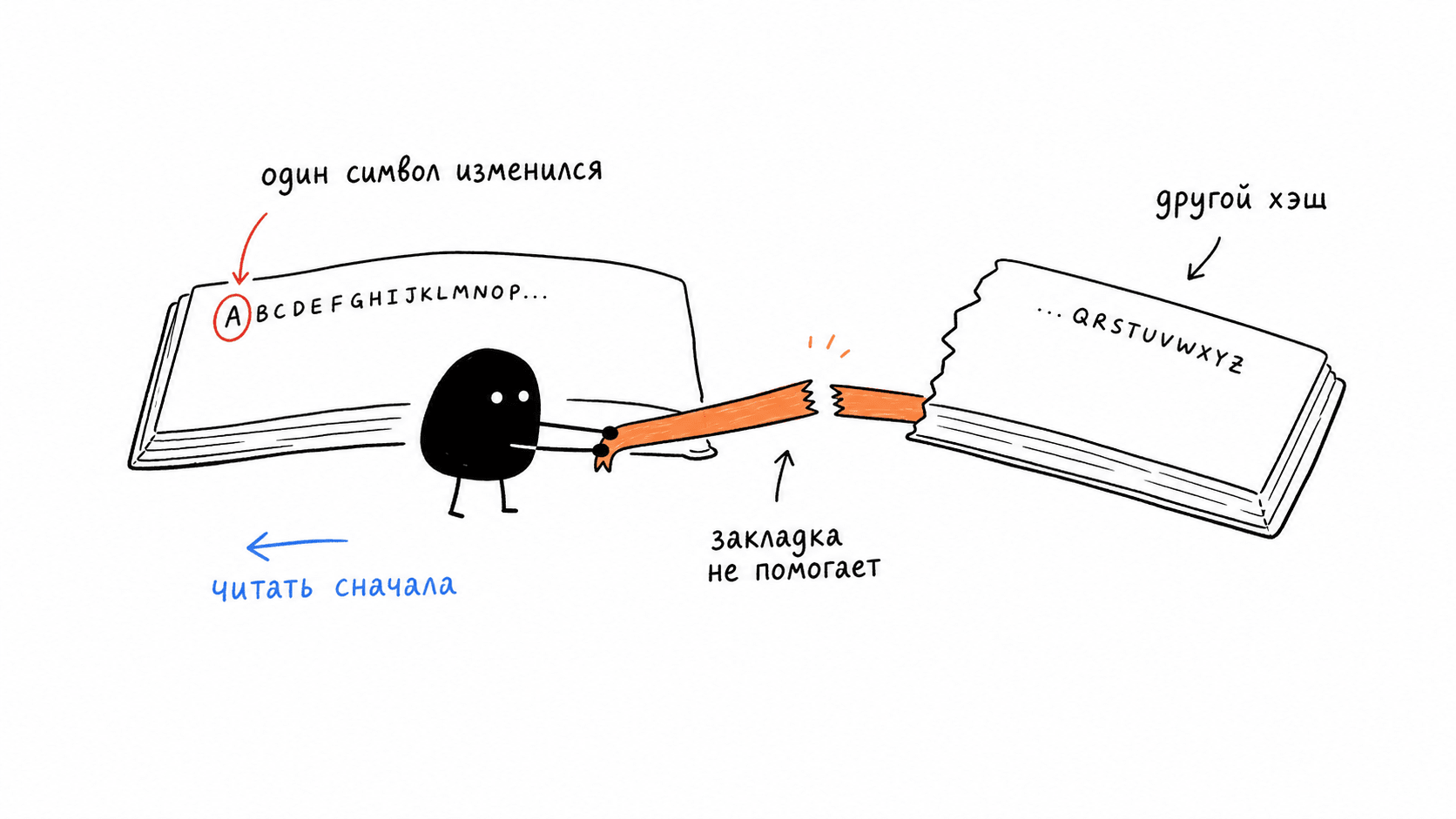
Temperature does not affect cache, although intuition suggests the opposite. It feels as if, when you ask the model to answer a little differently every time, there should be no cache to hit. But temperature adjusts token selection after the tensors have been computed, at the very last step, so you can change it however you want and the cache will not move.
Prompt caching at OpenAI, Anthropic, and Gemini: how much each one thinks for you
The underlying mechanics are the same everywhere, the same prefix matching, but the three providers wrapped it very differently. It is useful to view this as a scale: how much the provider decides for you and how many controls it leaves in your hands.
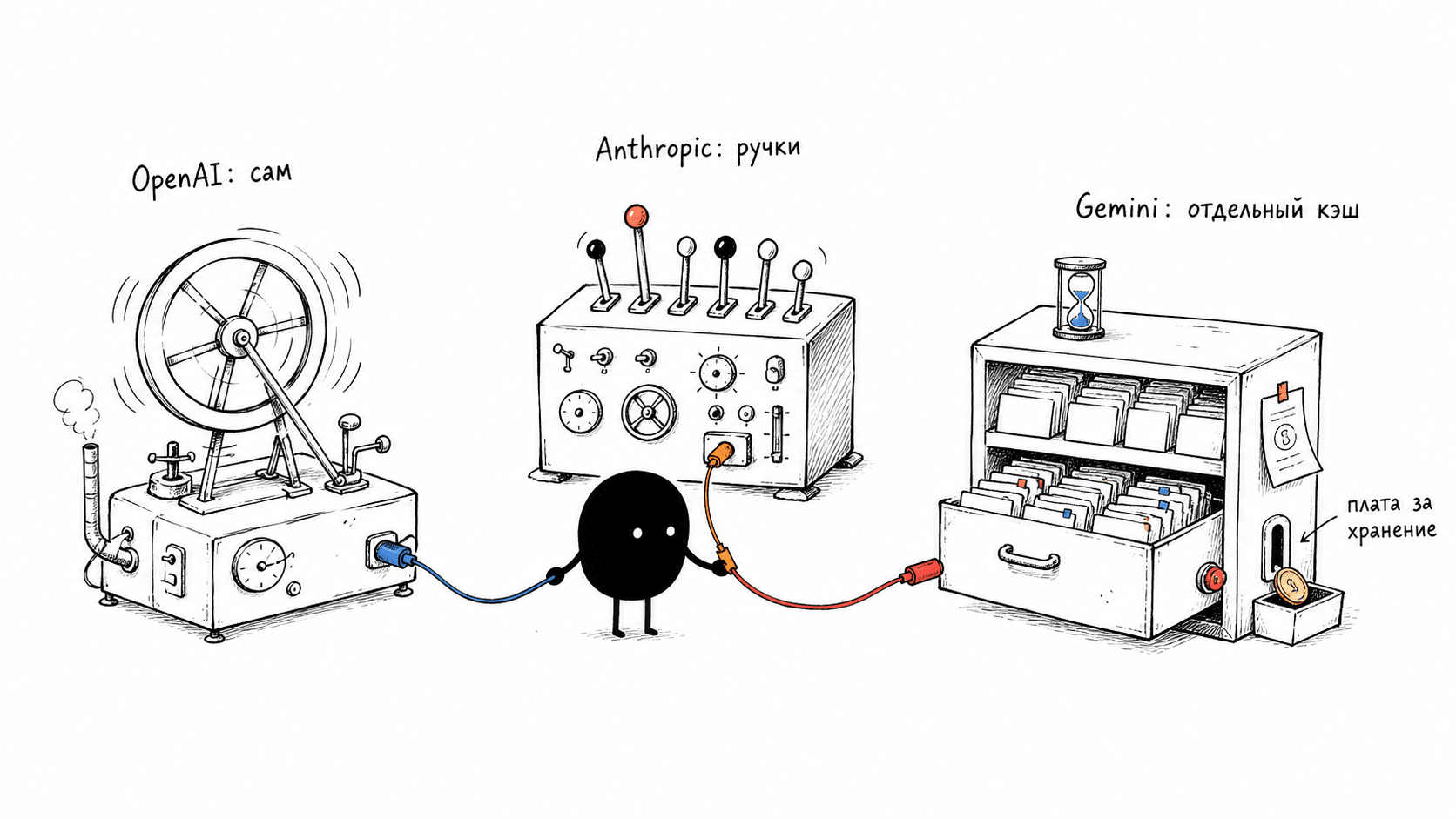
OpenAI does everything for you. Cache is enabled automatically, without flags. A prefix longer than 1024 tokens is cached automatically, and writes are free. You pay for convenience with control: you can barely help or repair the cache manually; what remains is to arrange the prompt correctly. The only control, prompt_cache_key, is deceptive: it is not a breakpoint and not cache control at all, but a routing hint — a hint to the load balancer about which machine to send the request to in order to land where your cache already lives. I am on OpenAI myself, and this automation helps me: one less thing to worry about. But there is almost nothing I can do manually with the cache, and nobody has removed the responsibility for a stable prefix from me.
Anthropic gives you controls. There are two modes. You can set an explicit breakpoint, explicitly marking the block up to and including which everything is cached. But that point is static: the dialogue grows, while the same marked beginning is cached, and everything accumulated after it goes at full price on every turn. That is why there is a second mode, auto-caching: one cache_control parameter, and the cache point itself moves to the last suitable block as the dialogue grows, removing the old pain of multi-turn agents where the breakpoint would otherwise have to be moved manually every turn. Unlike OpenAI, Anthropic charges for writes, and there is a nuance here. Five minutes and one hour of storage are not two different caches, but two pricing modes for one cache: writing a token to a 5-minute cache costs 25% more than regular input; writing to a one-hour cache costs twice as much; reads are equally cheap in both cases. The prefix is assembled in a fixed order: first tools, then system, then messages.
Google turns cache into a resource. If, at OpenAI, cache is default behavior, and at Anthropic it is a marker in the request, then at Google it is a separate object that you create yourself and pay to store, like disk space. In the documentation, the feature is called context caching. Gemini has implicit cache, enabled by default on models 2.5 and newer, but it does not guarantee savings. Explicit caching, on the other hand, is a full object lifecycle: you can create a cache, update its TTL, list it, and delete it, like any other API entity, and by default it lives for one hour. In code, it looks like this:
from google import genai
from google.genai import types
client = genai.Client()
# The stable prefix goes into a separate object
cache = client.caches.create(
model="gemini-3.1-pro-preview",
config=types.CreateCachedContentConfig(
system_instruction=system_prompt,
contents=[tools_and_docs], # everything that is repeated from request to request
ttl="3600s",
),
)
cache.name # "cachedContents/abc123", a reference to the cache
# Each request refers to the object by name
response = client.models.generate_content(
model="gemini-3.1-pro-preview",
contents="fresh user input",
config=types.GenerateContentConfig(cached_content=cache.name),
)
client.caches.update(name=cache.name, config={"ttl": "7200s"}) # extend the TTL
client.caches.delete(name=cache.name) # delete it and stop paying for storage
And Google is the only one of the three that also charges for storage, hourly, around $4.50 per million tokens per hour. The model name is easy to mix up, though. In the current lineup, it is gemini-3.1-pro-preview, while the old gemini-3-pro-preview was shut down back on March 9, 2026.
If we put everything into one table:
| OpenAI | Anthropic | Google Gemini | |
|---|---|---|---|
| How it is enabled | automatically, without flags | auto cache_control or explicit breakpoint | implicit or explicit object |
| Prefix threshold | from 1024 tokens | from 2048 (Sonnet) / 4096 (Opus, Haiku) | from 1024 (Flash) / 4096 (Pro) |
| Write price | free | input +25% (5-minute cache) / input ×2 (one-hour cache) | hourly storage fee |
| Cache read | ~10% of input price | ~10% | ~10% |
| How to measure it | cached_tokens in usage | cache_read_input_tokens | usage_metadata |
Absolute prices change; here they are as of June 2026, and what matters is not the numbers themselves but the ratio. Caching itself is also not enabled everywhere: at OpenAI and Gemini it works automatically when the prefix crosses the threshold, while at Anthropic nothing happens without cache_control in the request. And the prefix rule does not change for anyone: OpenAI’s convenience does not cancel it; it only hides it from you.
The anatomy of a cache-friendly prompt and how people break it
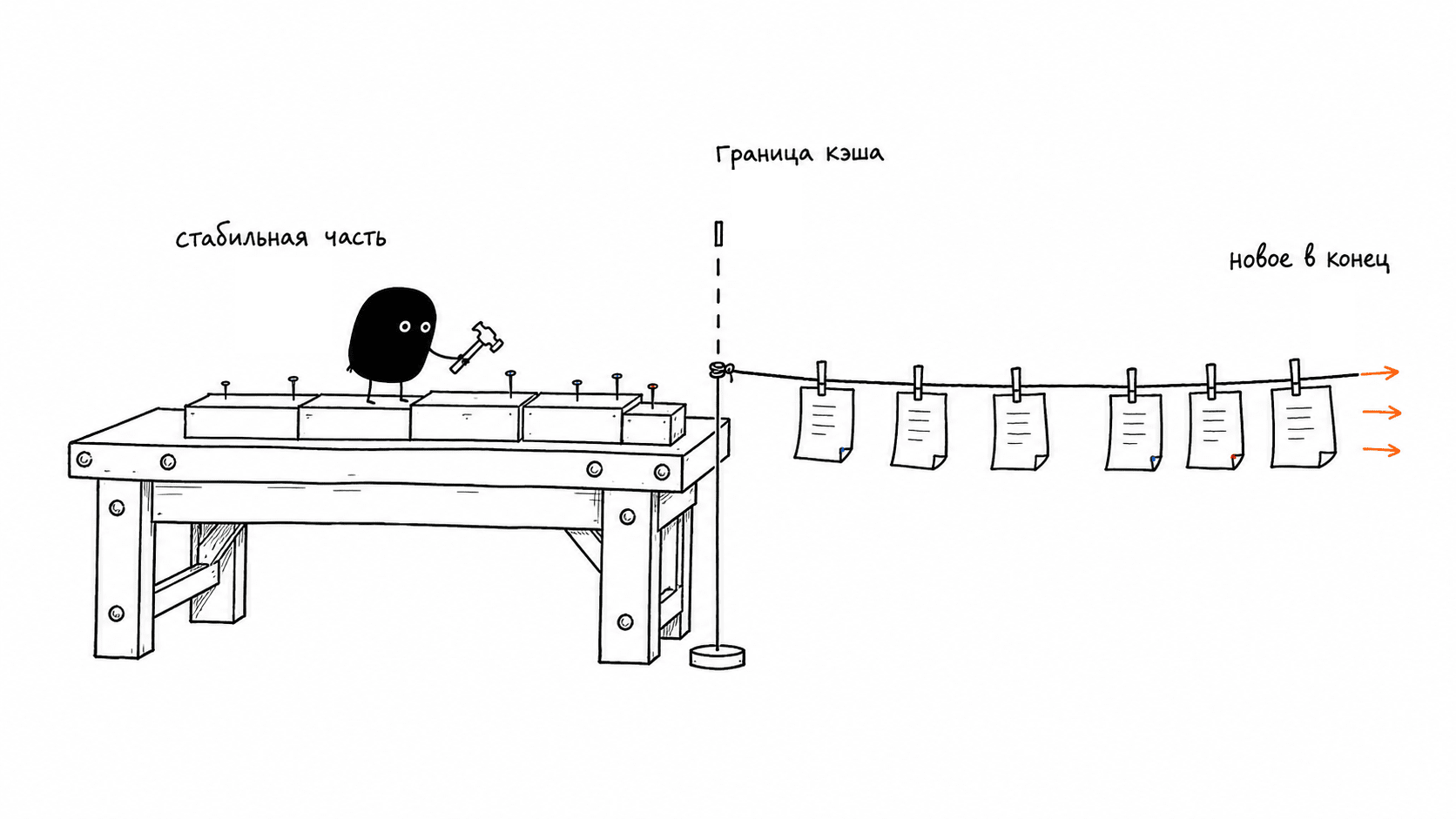
The prefix rule directly implies how the prompt should be arranged. From top to bottom, from the most stable to the most changeable, with an imaginary cache boundary somewhere in the middle.
The stable part, also known as the cacheable prefix:
- System prompt: role, rules, tone.
- Tool descriptions: fixed set and order.
- Long instructions and few-shot examples.
Cache boundary.
The changing part, new on every turn:
- Dynamic state: what changed since the previous turn.
- Dialogue history, which we only append to.
- Fresh user input.
Claude Code is arranged exactly according to this scheme: static first and dynamic last. Thariq from their team describes the order this way: the static system prompt and tools are cached globally, the project’s CLAUDE.md file within the project, the session context within the session, and only then the dialogue messages. Cache does not live inside the dialogue at all; it lives on the provider’s side, and the key is the prefix content itself: two different dialogues with a byte-for-byte identical beginning hit the same cache. The more sessions share a common prefix, the more often it works.
Two rules keep all of this standing. First: keep history append-only — only append to the tail, never rewrite retrospectively. Any edit to an earlier message shifts the prefix, and all cache after it dies. Second: serialize data structures deterministically — the same object into the same bytes, JSON keys in the same order. Shuffle the keys, and for the hash it is already a different text and a different cache.
Breaking this arrangement is easy, and there are exactly four ways to do it.
Dynamic content at the beginning of the prompt. The classic case is the current date and time in the system prompt. Both Thariq and Manus cite it as the first example because almost everyone falls into it: it is too logical to let the agent know what time it is. But time changes every minute, and with it the prefix changes, and the cache does not survive. The solution is elegant. Do not touch the system prompt; pass such updates through messages. Claude Code inserts a tag like “it is Wednesday now” into the next message, at the tail, not at the beginning, and the prefix remains intact.
Tools in the middle of a session. It seems reasonable to give the model only the tools it needs right now and swap the set along the way. According to Thariq, this is one of the most common ways to kill cache. Tools live at the beginning of the prefix, and as soon as you add, remove, or reorder even one, the cache for the entire dialogue is reset.
Fresh data thrown to the top. It is tempting to put a search result, a user profile, or a chunk pulled in via RAG higher up so the model definitely notices it. But fresh data changes by definition from request to request, and at the beginning of the prompt it acts like a cache self-destruct timer. Fresh data always belongs at the tail.
Changing models in the middle of a session. Cache is tied to a specific model; each model has its own. Spend a hundred thousand tokens on one model, switch to another, and the cache has to be built from scratch. The classic trap here is a router that sorts requests into simple and difficult ones on every turn. Difficult goes to the smart model, simple goes to the cheap one, so you do not run Opus for the weather. The savings look obvious, but if the dialogue has already accumulated a large context on Opus, sending one simple question to Haiku becomes more expensive than letting Opus answer it. The cheap model has no cache of its own; it rereads the entire context at full price. I use one model, so these rakes personally miss me, but for systems with automatic routing the trap is real. Claude Code solves it through subagents: the main model prepares a handoff message, and an agent on a lighter model (for them, these are Explore agents on Haiku) performs the task without breaking the cache of the main session.
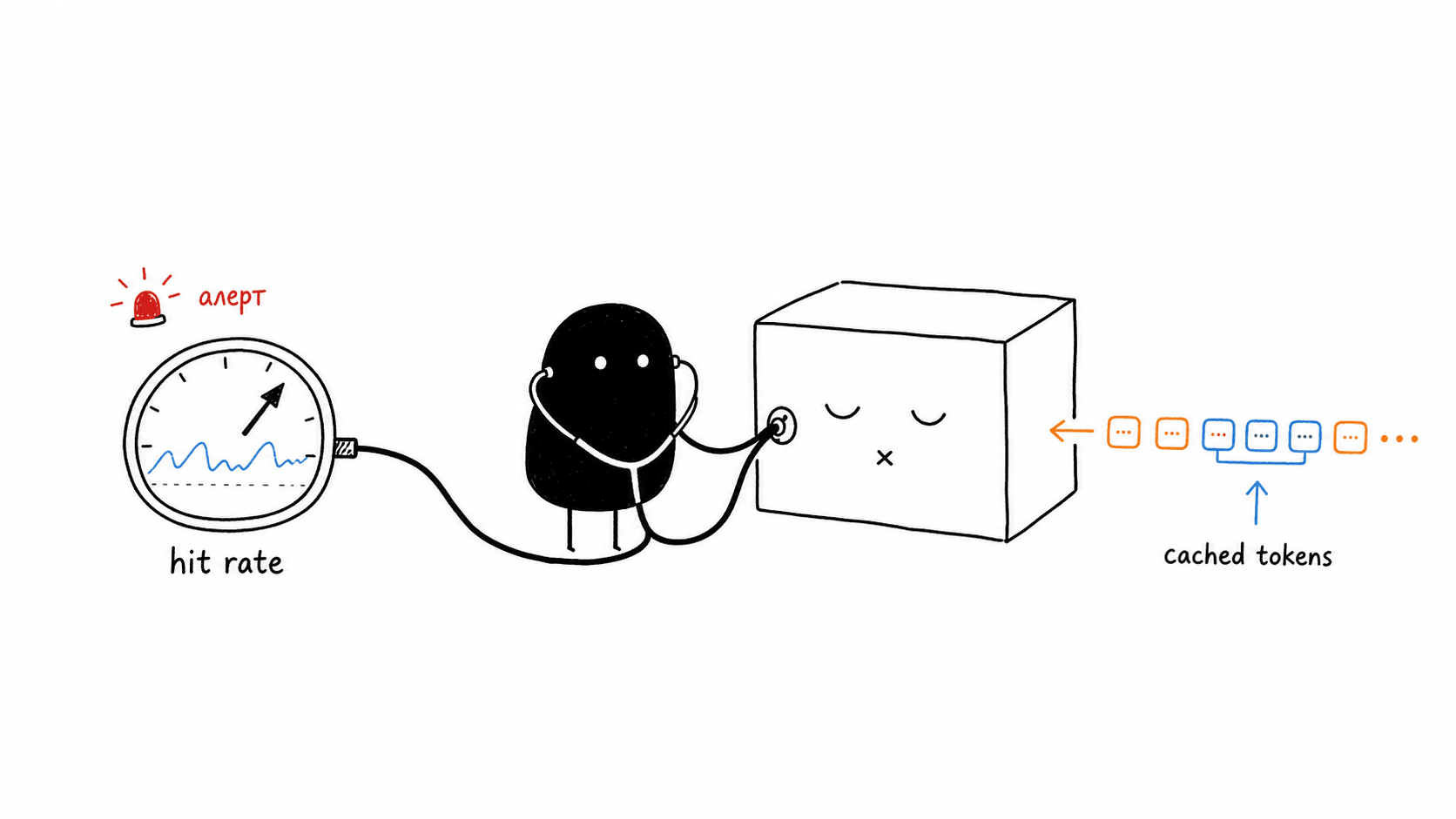
How to hear the silence: checking that cache works
Since a cache failure does not produce an error, the only way to notice it is to look at usage. All three providers return the breakdown directly in the API response: OpenAI puts the number of tokens read from cache in usage.prompt_tokens_details.cached_tokens, Anthropic returns cache_read_input_tokens and separately cache_creation_input_tokens for writes, and Gemini returns counters in usage_metadata. This is the operational interface to cache: not a promise from documentation, but concrete numbers on every request.
I do not parse these fields manually myself. All of my agent’s requests go through LiteLLM, and its logs show directly which request hit the cache and which went at full price. This is cheap to set up and immediately removes the main problem of silent failure: you begin to see it.
These numbers then compose into cache hit rate, and it is not a number for a pretty report. In Claude Code, Thariq says, they have alerts on it, and a drop is declared a SEV — an incident on par with uptime failure. A couple of percentage points of misses above the norm noticeably hit both cost and latency, which means they affect what limits the team can afford on subscriptions. The metric is the way to make a silent failure loud.
When cache starts designing the product
“Cache Rules Everything Around Me,” Thariq jokes, referencing Wu-Tang, and adds: for agents, this rule works literally. Claude Code, according to him, was built around cache from day one. And when you read how exactly, an interesting thing becomes visible. The cache rule repeatedly defeats the intuitive solution and rewrites the product feature around itself.
The cleanest example is plan mode, a mode where the agent first builds a plan and does not touch files. Intuition suggests: if editing is forbidden, swap the tool set for read-only. And that would break the cache, because tools live in the prefix. So Claude Code went against intuition: all tools are always in the request, while entering and exiting the mode are implemented as tools themselves, EnterPlanMode and ExitPlanMode. The set never changes, and the prefix remains intact. As a bonus, the model can enter plan mode itself for a difficult task, also without breaking the cache.
The same logic applies to tool search. Claude Code can have dozens of MCP tools connected, and putting the full descriptions of all of them into every request is expensive, while removing unnecessary ones during the dialogue is impossible, because that again breaks the cache. Thariq calls the solution deferred loading: instead of full schemas, the prefix contains lightweight stubs — the tool name with a “load later” marker — while the full schema arrives only when the model itself chooses the tool through search. The prefix is stable; the stubs are always the same and in the same order. The technique is broader than tools and is not tied to a single harness: agent skills are loaded progressively in the same way — a short description and trigger condition in the prefix, full body on demand.
And the least obvious case is context compression. When a dialogue hits the context-window ceiling, it is compressed into a summary and continued from there. A naive implementation makes this a separate request, with a different system prompt and without tools, and the prefix does not match the main one by a single byte. You pay full price for all hundred thousand tokens being compressed. Claude Code compresses differently: with the same system prompt, context, and tools as the parent, while the compression prompt is added to the tail, so for the API the request is almost no different from the previous one; the prefix is reused, and only the compression prompt’s own tokens are new. The same principle as with changing models through subagents: do not break the main session’s prefix for a side task.
Cache is a billing detail, a line in the pricing table about cheap tokens. But once you start protecting it seriously, it stops being a detail: it dictates how plan mode is structured, how tools are loaded, how compression works, and how models are switched. A technical constraint turns into a principle by which the product is designed. My agent is much simpler than Claude Code, but the logic is exactly the same: once you start taking cache seriously, the prompt naturally divides into a stable head and a changing tail.
The optimization you cannot leave for later
All prompt caching rests on one principle, and it scales widely. At the small end, it is “do not put the current time in the system prompt.” At the large end, as in Claude Code, it is “redesign plan mode, tool search, and compression so the prefix does not move.” There is no difference; it is the same rule about a bookmark that works only if nothing before it is touched.
That is why, for me, cache is not an optimization you can bolt on later. It is a constraint that the prompt architecture and agent loop must adapt to from the start. If you want an agent to run cheaply and quickly, there is no “I’ll deal with this later” option: by the time that “later” arrives, it has already been overpaying by several times for a month.
And the whole trick is that prompt caching is the only optimization that does not scream when it breaks. Broken cache looks exactly like working cache. That is why it cannot be left on autopilot: you have to think about it in advance and watch it constantly. Otherwise it will do exactly what it does best: quietly stop working.
Stay curious.
Frequently asked questions about prompt caching
What is prompt caching?
It is a mechanism used by LLM providers that stores the internal representation of the already processed beginning of a prompt (the prefix) and reuses it in subsequent requests. What gets cached is not the text and not the model’s answer, but intermediate computations (KV tensors). Rereading a matching prefix costs roughly one tenth of the price of a regular input token and noticeably speeds up the response.
How much does prompt cache save?
Reading from cache costs about 10% of the price of a regular input token at OpenAI, Anthropic, and Google. For agents, where there may be around one hundred input tokens per output token, this changes the economics completely: based on my bills, turning cache off would increase daily costs by roughly seven times. Latency on long prefixes drops by up to 80–85%.
Why does cache not hit?
Cache lives as long as the beginning of the request matches byte for byte. Four things break it: dynamic content at the beginning of the prompt (for example, the current time in the system prompt), adding or reordering tools in the middle of a session, nondeterministic data serialization, and changing models in the middle of a dialogue. There will be no error: the request will simply go at full price.
Does temperature affect cache?
No. Temperature and top_p control token selection after the prompt has already been read and the tensors have been computed. What is cached is the prompt-reading stage (prefill), so you can change sampling parameters however you want: they do not affect cache hits. This is one of the most common mistaken intuitions about caching.
How can you check that cache is working?
Look at usage in the API response. OpenAI returns the number of tokens read from cache in usage.prompt_tokens_details.cached_tokens, Anthropic in cache_read_input_tokens, Gemini in usage_metadata. If you route requests through a proxy like LiteLLM, the breakdown is visible directly in the logs. These numbers produce cache hit rate, the main operational metric for cache.
How does caching differ between OpenAI, Anthropic, and Gemini?
At OpenAI, cache is enabled automatically for prefixes starting at 1024 tokens, and writes are free. Anthropic requires the cache_control parameter, charges for writes (+25% for a 5-minute cache, double for one hour), but gives more control. At Google, cache is a separate object with a TTL and hourly storage billing, plus implicit cache by default on newer models.


