The Anatomy of LLM Memory: Why Context Engineering, Not Prompts, is the Future
Author: Aleksei Beltiukov

When working with large language model APIs, I've grown accustomed to a certain predictability. For my research tasks, code experiments, and daily routine, the daily API costs usually hover in a predictable and comfortable range of 3-4 euros. It became a kind of background noise, a constant I stopped paying attention to.
But in late July, I saw a picture in Google API billing that made me stop and think. Instead of the usual figure, an anomaly stood out — €51.
My first reaction was, of course, bewilderment. What did I do to generate expenses more than ten times the norm? This wasn't just the result of a particularly productive day or a prolonged generation session. The answer lay deeper. That day, I deep-dived into refactoring my blog's code, and to get the highest quality and context-dependent recommendations from the model, I fed it entire modules and accompanying documentation. At some point, the context size I was providing to the model in a single dialogue, for the first time, crossed the critical threshold of 200 thousand tokens. And it was at this very moment that I, unknowingly, crossed an invisible line. It turned out that LLM 'memory' has its price, and it grows quite non-linearly.
This situation is very similar to the pricing logic in freight transportation. As long as your cargo fits into a standard shipping container, its delivery is a smooth, predictable, and relatively inexpensive process. Logistics companies operate with standard rates, and you pay a clear price for volume and weight. But if you try to ship a part that exceeds the dimensions of that container by even a centimeter, you enter a completely different league. Your cargo instantly receives "oversized" status. And you pay not just for the extra centimeter, but at a completely different rate — for special permits, the development of a special route, perhaps even for escort. The price increases not by percentages, but by multiples. You pay for complexity.
The same thing happens with LLM context. As long as it remains within a certain 'standard' window, the price is predictable. But as soon as you exceed it, you start paying for 'oversized' computational cargo.
And this surge in my billing is neither an error nor a bug. It's a documented, fundamental feature of the system's operation, an economic reality dictated by the laws of mathematics that underpin modern LLMs. To understand why it exists, how to work with it, and, most importantly, how to control it, we need to look under the hood and dissect the LLM 'memory' mechanism itself.

The Magic and Math of the "Attention" Mechanism
So, we've encountered the 'oversized rate' for context. To understand its nature, we need to abandon the intuitive, human notion of memory. We tend to think of memory as a passive warehouse where we simply add new facts. But for a large language model, 'memory' is not a storage facility, but a continuous, active, and incredibly expensive computational process. The name of this process is the Attention mechanism.
When we give the model a long text, it doesn't 'read' it sequentially, like a human, from beginning to end, accumulating information in some buffer. Instead, something far more complex happens. To generate each new word or token, the model 'looks back' at the entire context provided to it — from the very first to the last word — and tries to understand which parts of the preceding text are most important for the next step. It literally weighs the importance of each word in relation to every other word to construct the most probable continuation.
How does this look in practice?
To illustrate this beyond a mere statement, let's look at how it's implemented in most modern SDKs, using google-genai as an example. When we use the convenient chat object, we intuitively feel that the model "remembers" the dialogue. But how?
from google import genai
# Initialize the client
client = genai.Client()
# Create a chat session. The SDK will manage the state for us.
chat = client.chats.create(model="gemini-2.5-flash")
# 1. Send the first message
response = chat.send_message("I have 2 dogs at home.")
print(response.text)
# > Excellent! Dogs are wonderful companions. How can I help?
# 2. Send the second message
response = chat.send_message("How many paws are there in my house?")
print(response.text)
# > You have 8 paws in your house (4 from each of the two dogs).
# 3. Let's see what the SDK actually "remembers"
for message in chat.get_history():
print(f' роль: {message.role}, текст: "{message.parts[0].text}"')
# History output:
# > role: user, text: "I have 2 dogs at home."
# > role: model, text: "Excellent! Dogs are wonderful companions. How can I help?"
# > role: user, text: "How many paws are there in my house?"
# > role: model, text: "You have 8 paws in your house (4 from each of the two dogs)."The SDK elegantly abstracts this complexity from us, but under the hood, exactly what we're talking about is happening. When we call chat.send_message() a second time with the question "How many paws are there in my house?", it's not just this new question that's sent over the network. The entire accumulated dialogue history is sent, which we see in the output of chat.get_history(). The model receives the full context to provide the correct answer "8".
It's as if you were to retell the entire previous conversation from the beginning to your interlocutor every time before asking a new question. And it is this constantly growing 'snowball' of context that falls under the roller of quadratic complexity.
I've already thoroughly discussed this superpower, which allows models to maintain narrative coherence even in very long dialogues and generate remarkably coherent text, in my article "What actually happens under the hood of LLMs?". But for us now, what's important is not the fact of its existence, but its computational cost.
And here lies the root of exponential cost. The complexity of these computations grows non-linearly, or more precisely, almost quadratically (O(n²)) with respect to the context length (n). Simply put: if you double the number of tokens in a prompt, you roughly quadruple the amount of computation required to generate the next token. Increase the context tenfold — you get a hundredfold increase in computational load.
To make this clearer, let's use an analogy. Imagine the model is not just a reader, but a brilliant conductor of a giant orchestra, where each musician is one token in your context.
- With an orchestra of 10 musicians (10 tokens), the conductor handles it effortlessly. Before each new note, he can easily look at everyone, consider each part, and create perfect harmony.
- Now, his orchestra has 100 musicians. The task has become more complex. For the next note to sound harmonious, he needs to consider what the violins are playing, how the brass instruments respond, what rhythm the percussion sets. This already requires serious concentration.
- And now, imagine our case — an orchestra of 200,000 token-musicians. Before giving the cue for each new note, the conductor must instantly assess the contribution of each of the two hundred thousand performers, analyze their interrelationships, and decide who should play louder and who quieter. This titanic, almost impossible work is the 'Attention' mechanism. And it is for this colossal computational work that we pay the 'oversized rate'.
Every new token we add to the context doesn't just take up space — it exponentially complicates the work of the conductor-model, making each subsequent step more expensive and complex.

Context at Scale. The Triple Challenge: Cost, Quality, and Speed
Now that we understand that behind every token in a large context lies a quadratically increasing computational load, the race for million-token context windows we observe in the market no longer looks like a simple marketing ploy. It's no longer a 'who has more' competition, but a complex engineering compromise. Each provider seeks its own balance between three competing forces: cost, quality, and speed.
To see this clearly, one simply needs to look at the landscape of modern flagship models. I've compiled the key parameters into a single table, which, in essence, is not a price list, but a snapshot of different companies' engineering solutions.
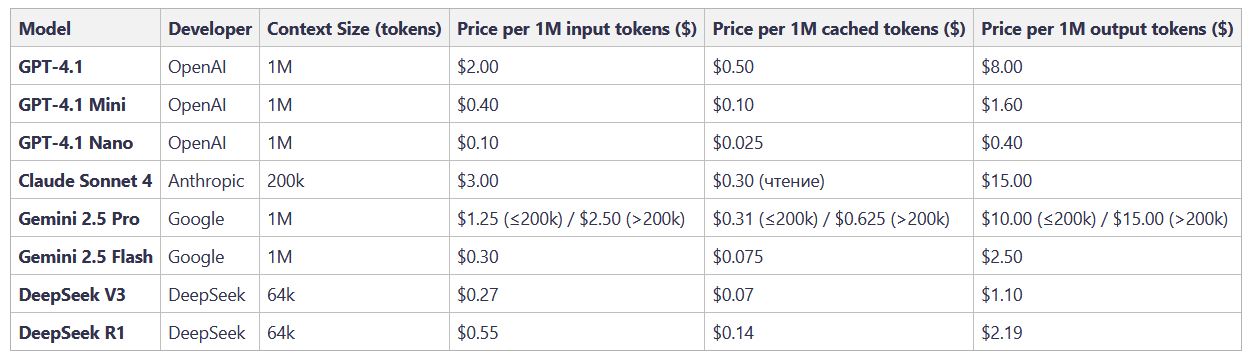
Before we proceed with the analysis, take a look at the column — cached tokens. Providers also understand that forcing users to pay the full price for re-processing the same giant context repeatedly is a dead end. That's why almost all of them have implemented a Context Caching (or Prompt Caching) mechanism. Its idea is ingenious in its simplicity. If you send the model the same system prompt or a large document repeatedly, only changing the last part of the request, caching allows you to pay the full cost for processing this unchanging 'prefix' only once. The model retains its internal representation (the computed states of the Attention mechanism), and in subsequent calls, you pay for it at a discounted rate, which can be 75-80% lower than the base price.
It's as if our conductor-model, having once learned a complex score for its orchestra of 200,000 musicians, saved all its notes. The next time it's asked to perform the same score, but with a different coda, it doesn't need to re-analyze the entire symphony — it simply opens the ready, 'cached' score and finishes the ending. This dramatically reduces the cost for scenarios where most of the context is static: for example, RAG systems, chatbots with long histories, or data analysis based on the same document.
Now, let's return to the Gemini 2.5 Pro row. Here it is, the very technical explanation for my 'oversized rate' from the first act, embodied in the official pricing policy. Google explicitly states: even with caching, as soon as your new, uncached context exceeds 200 thousand tokens, your price doubles. This is not a marketing trick; it's an honest acknowledgment of physical limitations. It's the cost for the exponentially increased computational complexity of the Attention mechanism, which we discussed in the second part of the article.
But cost is just the tip of the iceberg. Two other compromises are even more insidious.
Quality: Research and practice show that as context grows, models begin to suffer from a problem known as 'needle in a haystack'. If one important fact is placed in the middle of a huge document, the model is highly likely to ignore it. Its attention exhibits a so-called U-shaped curve: it remembers information very well at the beginning and at the very end of the prompt, but 'fails' in the middle. Returning to our conductor analogy, this is easily explainable. When there are 200,000 musicians in an orchestra, the conductor physically cannot give equal attention to each. He focuses on the front rows (beginning of context) and on soloists who are about to enter (end of context), while somewhere in the middle of the huge hall, individual instruments simply get lost in the general hum.
Speed: This is the most obvious compromise. More computations mean more time for a response. For simple queries, this might be unnoticeable, but in interactive applications or complex call chains, the delay caused by processing giant contexts can become critical.
To be fair, it must be said that the industry is not standing still and is actively looking for ways to circumvent the 'curse of quadratic complexity'. Alternative architectures are appearing on the horizon, attempting to break this vicious link between context size and computational volume. As I noted in my analysis of the MiniMax-M1 architecture, some developers are experimenting with hybrid approaches, combining standard attention with techniques like Mixture-of-Experts (MoE), where only a portion of its 'experts' are activated for a response, or linear attention, which attempts to approximate the result with fewer resources. But until these solutions become mainstream and prove their effectiveness at scale, we, as users and engineers, are forced to work with the reality dictated by the classical Attention mechanism.

Architect's Tools. Five Hacks for Context Management
So, we've diagnosed the problem: large context is expensive, slow, and potentially inaccurate. We face a triple engineering challenge. But instead of passively accepting these limitations as given, we can take control. Before we move on to a fundamental, architectural shift, let's arm ourselves with a set of tactical approaches. I call this 'context hygiene' — a set of simple yet powerful habits that help keep the model in top shape.
Here are five specific techniques I actively use:
1. "The Last Word"
This is the simplest and surprisingly effective technique. Its essence is that at the end of a very long prompt, after thousands of tokens of descriptions, examples, and data, you briefly and clearly repeat the most important instruction. This hack is a direct antidote to the U-shaped attention curve we discussed. Knowing that the model 'hears' best what is at the very end of the context, we deliberately place the most important command there. For example, after ten pages of technical specifications for module development, your prompt might end like this: "...thus, the system must be fault-tolerant. Key task: Based on all of the above, write an API specification for the authentication service in OpenAPI 3.0 format." This last phrase acts as a powerful focus for the model's 'attention'.
2. "Forced Injection"
During a long, multi-stage dialogue, the model inevitably starts to lose focus. Early but important details can 'drown' in the middle of the context. To 'refresh' the model's memory, you can use the forced injection technique. You simply insert a message into the dialogue from your side (as the user) that doesn't ask for anything to be generated, but merely summarizes key facts. For example: "Before we continue, let's confirm: 1. We use a PostgreSQL database. 2. Authentication is via JWT tokens. 3. The main priority is response speed. Now, considering this, propose a caching scheme." This is like a director stopping a rehearsal and loudly reminding the actors of their characters' key motivations. You manually create a new, high-priority 'memory island' at the end of the context.
3. "Structural Anchor"
One reason models might 'hallucinate' or wander off-topic is too much freedom. By limiting this freedom, we can direct its computational resources to the right path. Instead of asking 'analyze the text and provide conclusions,' give it a 'template' to fill. This could be a Markdown structure, a JSON object skeleton, or any other format. For example: "Analyze the error report and populate the following JSON structure: {"summary": "", "root_cause_hypothesis": "", "suggested_fix": "", "required_tests": []}". This approach not only ensures you receive the answer in the desired format but also serves as an 'anchor' for the model's attention, forcing it to look for specific entities in the text.
4. "Manual Summarization"
This technique is similar to 'forced injection', but here we delegate the work to the model itself. When a dialogue becomes too long and convoluted, ask the model to summarize it. "Great, we've discussed a lot. Please provide a brief summary of our dialogue, highlighting 3-5 key decisions we've made." Once you receive this condensed summary, you can copy it and start a new dialogue, pasting it at the beginning. You are effectively manually compressing the context, discarding the 'fluff' and leaving only the concentrated information.
5. Principle of Power Division
Up until now, we've focused on how to manage context for a single, usually flagship, model. But what if the biggest lever for optimization lies not within the dialogue, but in the choice of the interlocutor itself? This hack is based on a simple yet powerful idea: stop using one expensive model for all tasks.
This is like having a toolbox but grabbing the heaviest sledgehammer for any job — from tightening a tiny screw in glasses to demolishing a wall. It's inefficient and ruinous. For simple text classification, fact extraction, or brief summarization, a fast and cheap model like Qwen3, which can be deployed locally on your hardware, would be ideal. But when it comes to complex logical reasoning or code generation based on a comprehensive specification — that's when we call in the 'heavy artillery' in the form of a reasoning model like Gemini 2.5 Pro.
In practice, this is implemented by creating a simple 'model router' at the entry point of your system. A first, very inexpensive call to a fast model can analyze the user's query and determine its complexity. 'Is this a simple question? Send it to the 'Flash' model. Does it require code generation? Switch to the 'Pro'.' This approach is particularly powerful, considering that different models have different specializations. As I noted in my previous analysis, some models might be better at API usage tasks, while others excel in creative writing. Using a cascade of specialized models not only drastically reduces costs but also improves overall quality.
These tactical techniques will help you in your daily work. They are first aid, allowing you to quickly and effectively solve problems here and now. But to move from patching holes to building robust systems, we need to rise to a higher level. We need to stop thinking about prompts and start thinking about context.

Paradigm Shift. Welcome to the Era of Context Engineering
Everything we've discussed so far — tactical tricks — was just first aid. But even a powerful architectural approach like RAG (Retrieval-Augmented Generation), which many today consider a panacea, is actually just one component of a broader phenomenon. We've approached the edge of a new discipline that is only now gaining its name — Context Engineering. First crystallized in the community around projects like the Context Engineering repository, this field is growing so rapidly today that fundamental review articles analyzing over 1400 works and aggregators of best practices are already emerging. Andrej Karpathy, one of the deepest thinkers in AI, recently articulated it thus: 'Context Engineering is the subtle art and science of populating the context window with only the necessary information for the next step.'
This definition is the key to everything. It shifts the focus from writing the perfect instruction to designing the perfect information environment. As aptly put in the community: if prompt engineering is what you tell the model, then context engineering is everything else the model sees. And this 'everything else' is far more important.
To understand this discipline, let's expand our definition of 'context.' It's not just a prompt. It's the complete information package that the model receives at the moment of invocation. Based on the best practices I've analyzed, it consists of numerous dynamically assembled components:
- Instructions / System Prompt: Global rules for model behavior.
- User Query: The immediate task.
- State / History: Short-term memory of the current dialogue.
- Long-term Memory: Persistent knowledge base about the user, their preferences, and past projects.
- Retrieved Information (RAG): External, up-to-date data from documents, databases, or APIs.
- Available Tools: Definitions of functions the model can call.
- Output Structure: Requirements for the response format (e.g., JSON schema).
This practical list of components is, in essence, a reflection of the formal taxonomy proposed in the 'A Survey of Context Engineering' research. It highlights three pillars: Context Retrieval and Generation (which includes RAG), Context Processing (structuring, self-improvement), and Context Management (memory, optimization). Our job as engineers is to build a system that manages all these elements.
Context Engineering is the discipline of designing dynamic systems that gather all these components in real-time to provide the model with everything it needs to solve a task. The importance of this approach cannot be overstated. As practice shows, most agent failures are not model failures, but context failures. The model cannot read our minds. 'Garbage in, garbage out.'
The difference between bad and good context is the difference between a useless demo and a 'magical' product. One commenter shared a brilliant example. Imagine an AI agent receives an email: "Hi, can we quickly connect tomorrow?"
- A "Cheap Demo" agent with poor context only sees this text. Its response will be robotic and useless: "Thank you for your message. Tomorrow works for me. What time would be convenient for you?"
- A "Magical" agent, operating on the principles of context engineering, will gather rich context before calling the LLM: your calendar (which shows you are busy), the correspondence history with this person (to understand the appropriate tone), your contact list (to identify them as an important partner), and access to the
send_invitetool. And only then will it generate a response: "Hi Jim! I'm fully booked tomorrow, back-to-back meetings. Thursday morning is free, how about that? I've already sent an invite, let me know if it works."
The magic is not in the model. The magic is in the context.
This approach is already supported by scientific research. We see how researchers from IBM Zurich, by providing the model with a set of 'cognitive tools' (essentially, well-structured context for reasoning), increase its effectiveness by 62%. And works from ICML Princeton explain why this works, showing that within LLMs, symbolic mechanisms spontaneously emerge for processing structured information.
Context engineering is not just a new buzzword. It's a fundamental shift from writing lines of code to designing systems. We stop being trainers and become architects of cognition.

The Sunset of the Prompt Engineer, The Dawn of the Context Architect
Our investigation, which began with an anomalous €51 bill, led us to an unexpected and fundamental conclusion. We journeyed from an economic symptom to its mathematical cause (quadratic complexity), from tactical 'context hygiene' techniques to understanding a new engineering paradigm.
It becomes obvious: the era in which the main skill was the ability to write a clever prompt is coming to an end. Prompt engineering doesn't disappear, but becomes just one, the most basic element — an 'atom' — in a much more complex and important discipline. We are entering the era of Context Engineering.
True mastery now lies not in writing an instruction, but in designing the ideal information environment for the model. This is the work of a Context Architect, and their tasks directly stem from the very formal components of Context Engineering that we discussed. It includes:
- Material Selection: Choosing the right models for each subtask.
- Logistics Design: Building RAG systems for timely delivery of relevant information.
- Tool Creation: Developing 'cognitive tools' and structured templates that guide the model's reasoning.
- Workspace Organization: Structuring the entire context (data, examples, schemas) in a language understandable to the model's internal symbolic mechanisms.
- Project Management: Orchestrating multi-step chains and multi-agent systems.
The main question today is no longer 'which model to choose?' Access to powerful LLMs is becoming a standard tool. The key question now sounds different: 'How do you become someone who can build systems in which these models can unleash their maximum potential?'
The goal is no longer just to avoid hallucinations. The goal is to control them — to create and design the very informational field in which meaningful and useful reasoning is born. We become architects of artificial cognition.
Stay curious.


