Why one character breaks the cache: prompt caching under the hood
Author: Aleksei Beltiukov

TL;DR: What gets cached is not the prompt text and not the finished answer, but the key/value tensors of each token, its internal representation inside the model. Each such tensor depends on everything to its left; this is causal attention. That is why only a shared prefix can be reused, and this is an invariant, not a detail of a particular engine. vLLM stores tensors in blocks of 16 tokens and indexes them with a git-style hash chain: a block hash includes the parent hash, so editing one token at the beginning rewrites all hashes after it and breaks the chain. From this follow both properties of the cache at once: fragility (one character kills the hit) and power (the entire prefill of the shared beginning is skipped). SGLang does the same through a radix tree, vLLM uses a separate handler for sliding window, but the dependency on the shared prefix does not disappear anywhere.
In the first part, I derived one rule and suggested living by it: stable things at the beginning, changing things at the tail; one character in the system prompt invalidates the entire cache. The rule works; I am building an agent around it myself. But living under a law you do not understand is uncomfortable. Why exactly one character? Why does an “almost the same” prompt not count as a hit? What is the physical reason that makes the cache work either entirely on the shared beginning, or not work at all?
I have not written vLLM or paged attention by hand. But the source code is open, and I went into it for exactly this: to see the byte-level reason behind the rule I used to believe blindly. What follows is a report from the rabbit hole. What physically sits on the GPU at the moment of a hit, how the engine manages that memory, and why one character is enough to make everything fall apart. All names and numbers below have been checked against the source code of vLLM 0.23.0, so the code in the article is real.
What actually gets cached
Before emitting the first word of the answer, the model reads the entire prompt. This reading has a name, prefill, and it is the most expensive part. All input tokens are passed through the layers at once, in one large matrix pass. Such a pass is limited by compute (compute-bound): it saturates the GPU with matrix multiplications, and the longer the prompt, the longer it takes.
Then the second phase begins: decode. The model generates the answer one token at a time, autoregressively, and here the bottleneck is different. Each new token forces the model to pull the entire accumulated cache of previous tokens from memory again, so decode is limited by memory bandwidth (memory-bandwidth-bound), not arithmetic.
An analogy that helped me: prefill is when you read a book and leave notes in the margins on every page. Decode is when, after reading, you write a summary, and instead of rereading the book from scratch for every word, you look at your notes. It is those notes that are cached. If someone before you has already read the book and made notes, you do not need to reread those pages: you take the ready-made notes and write your summary.
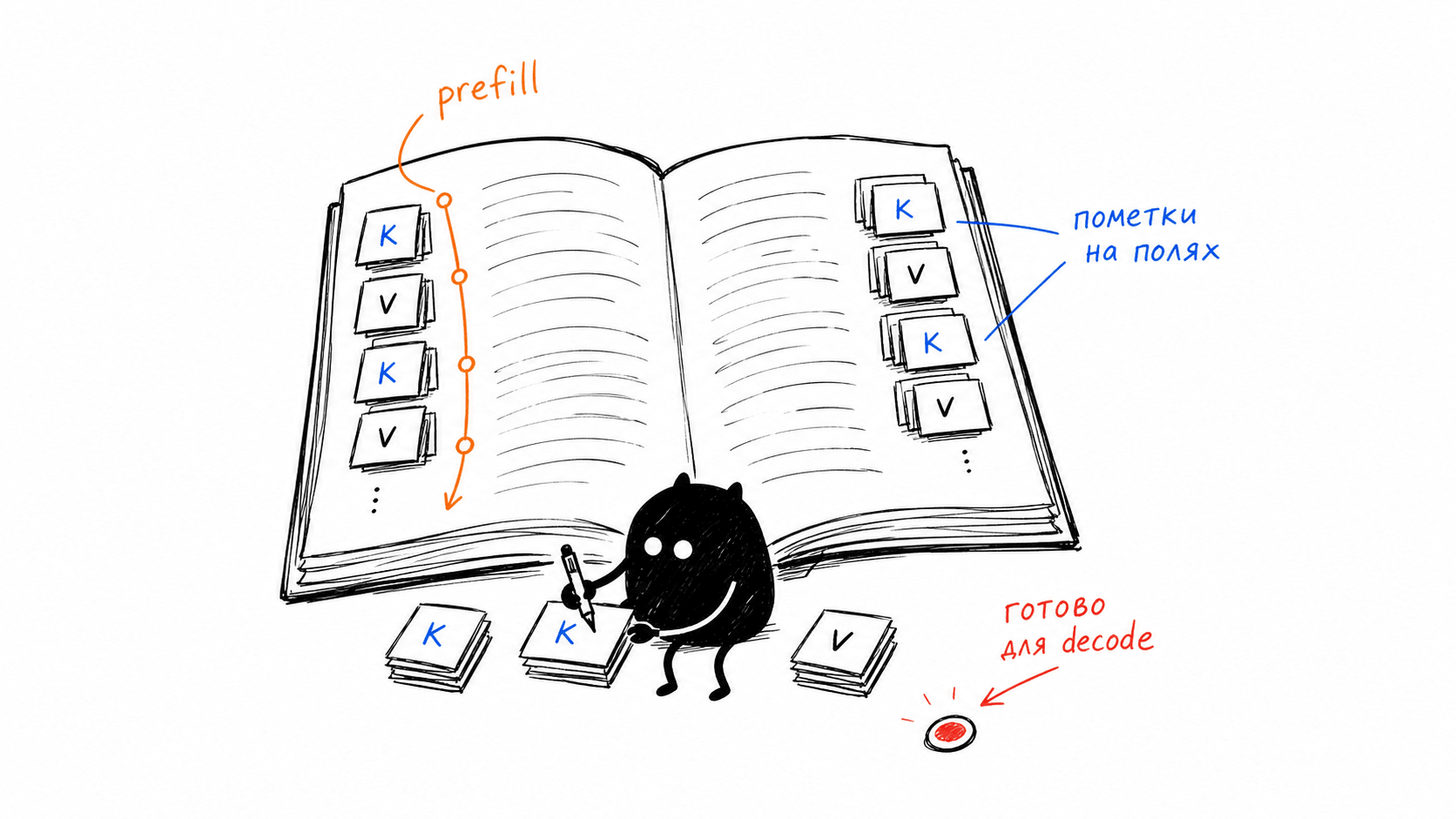
Now, what these notes physically are. In causal attention, every token computes three tensors through the layers: Query, Key, and Value. Roughly speaking: Query is “what the current token is asking about”, while Key and Value are “what previous tokens can offer to the others”. To process a new token, the model needs the Key and Value of all tokens to its left. These are what get saved; this is the KV-cache. There is no point in storing Query: each step has its own, and there is nothing to reuse it for.
A token’s Key and Value are not computed from the token alone in a vacuum, but with regard to everything on the left: causal attention allows a token to see only the past, and that past is embedded into its representation. The KV tensor of the 50th token depends on tokens 0 through 49. Therefore, these computed tensors are suitable for reuse under one condition: the entire preceding prefix must match verbatim. Not “similar”, but identical down to the character. For now, I am saying this calmly, as a mechanical fact. Everything that follows grows out of this one property.
But if the prefix does match, the gain is enormous by simple arithmetic. Appending one new token to the cache during decode is O(1): compute its Key and Value, put them next to the rest. But recomputing KV for the entire prefix from scratch is work linear in its length, and that is exactly the work a cache hit lets you skip. For coding agents, the input context is orders of magnitude longer than the answer (I gave concrete numbers for this imbalance in the first part), so the savings on prefill of the shared beginning hit exactly where it hurts.
Why this cache is so expensive to store
Since the cache is computed tensors, they have a weight in bytes. The KV-cache size per token is:
2 (K and V) × n_layers × n_kv_heads × head_dim × bytes_per_value
The formula is exact, not a rough estimate. The two stands for the two entities, Key and Value. Then come the number of layers, the number of KV heads, the head dimension, and how many bytes one value occupies. The familiar variant 2 × n_layers × d_model × bytes is correct, but only for classic multi-head attention, where d_model = n_heads × head_dim. With GQA or MQA, where there are fewer KV heads than attention heads, this shorter notation systematically overestimates the result, sometimes by a factor of several. You have to calculate through n_kv_heads.
Let us plug in numbers for a model like Llama-2-7B (32 layers, 32 KV heads, head_dim 128, fp16, that is 2 bytes):
2 × 32 × 32 × 128 × 2 = 524,288 bytes ≈ 512 KiB per token
Half a megabyte for one token. A context of one thousand tokens is already about 500 MiB, and one hundred simultaneous requests with one thousand tokens each is on the order of 50 GiB just for the cache. And all of this is margin notes, not the answer itself. At this point it is tempting to write down “half a megabyte per token” as a universal fact about 7B models, but that would be a mistake. Take Qwen3.6-27B: the model is almost four times larger, has twice as many layers (64 versus 32), and even wider heads (head_dim 256 versus 128), but only 4 KV heads instead of 32. The result is 256 KiB per token, twice less than our MHA 7B. And Qwen3.6-35B-A3B, with only two KV heads per layer, fits into just 80 KiB. There is no single magic number; the number lives with the architecture, not with the parameter count.
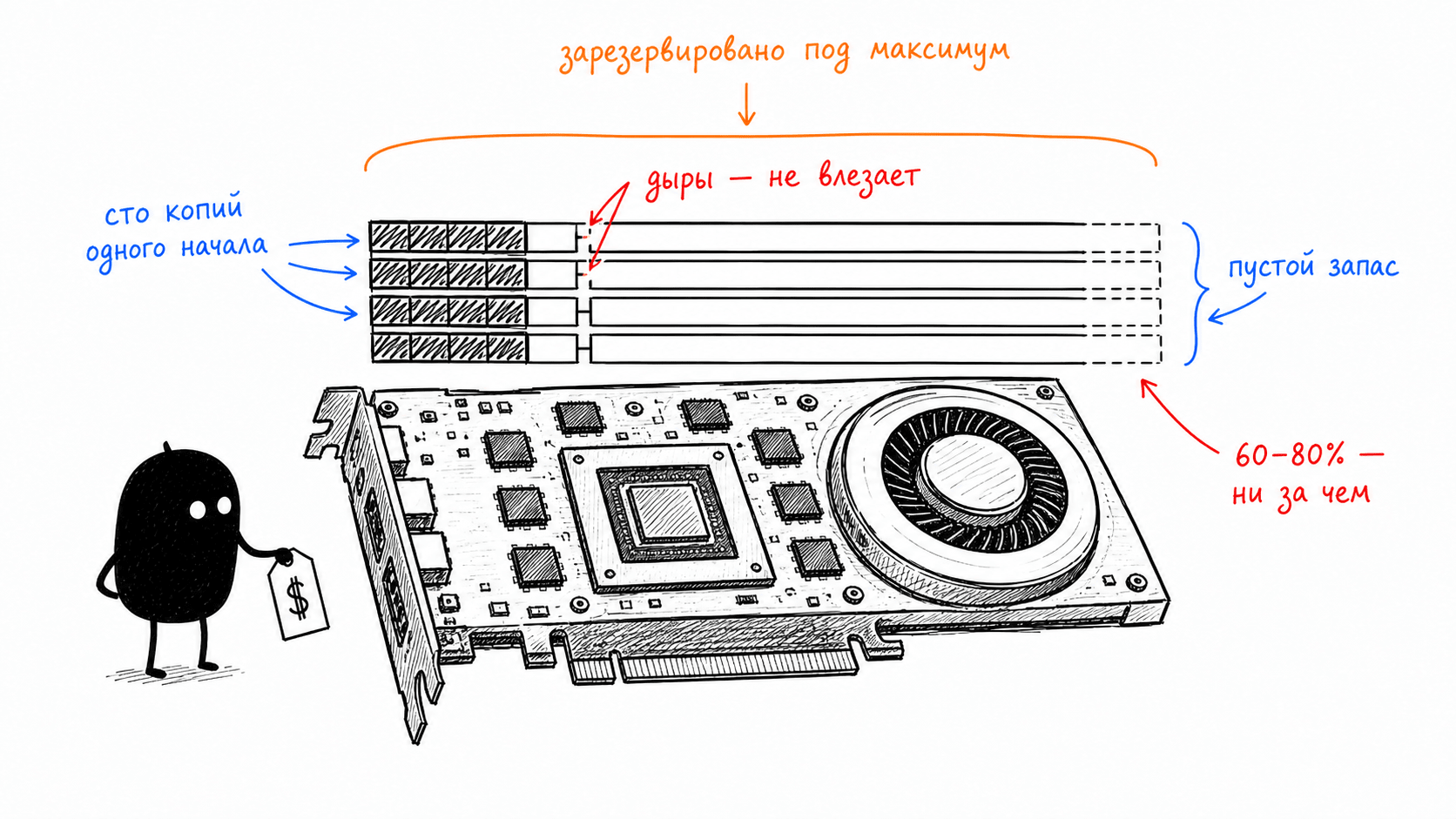
Dozens of gigabytes for the cache are only half the trouble. Worse is how easy it is to waste that memory. The naive storage method, one contiguous chunk of VRAM per request allocated immediately for the maximum length, inherits all the classic memory-management diseases from operating systems. You reserve space for the maximum, but the request turns out short: internal fragmentation, holes inside the allocation. Requests arrive and leave with different lengths; gaps remain between them that a new request cannot fit into: external fragmentation. And there is a separate pain point for agents: one hundred requests with the same system prompt are one hundred independent copies of the same KV-cache, because a traditional cache lives inside the request and is simply thrown away after generation. It is not shared between requests at all.
The original PagedAttention paper measured how wasteful this is: in systems current at the time it was published, only 20.4–38.2% of allocated KV memory went to real tokens. The rest was spent on slots reserved in advance and fragmentation. The engine was holding 60–80% of expensive video memory, essentially, for nothing.
PagedAttention: virtual memory for the GPU
Berkeley looked at the problem “memory is allocated as one contiguous chunk, which causes fragmentation and waste” and recognized in it a task that operating systems solved half a century ago. They describe their PagedAttention as an algorithm inspired by classic virtual memory and paging in operating systems.
The idea transfers one-to-one. The KV-cache is cut into fixed-size blocks, pages. Logically, a request’s tensors run consecutively as a single tape, while physically the blocks are scattered through VRAM however they happen to be. A block table connects one to the other: for each logical block, it stores the real physical address. This is exactly a page table from an operating system, except the pages here are not four kilobytes of RAM, but several KV tensors on the GPU. I went into the code looking for some clever GPU magic, and found what you learn in sophomore year. Logical continuity is separated from physical placement, and fragmentation as a problem simply evaporates: the blocks are uniform, so there are no holes between them.
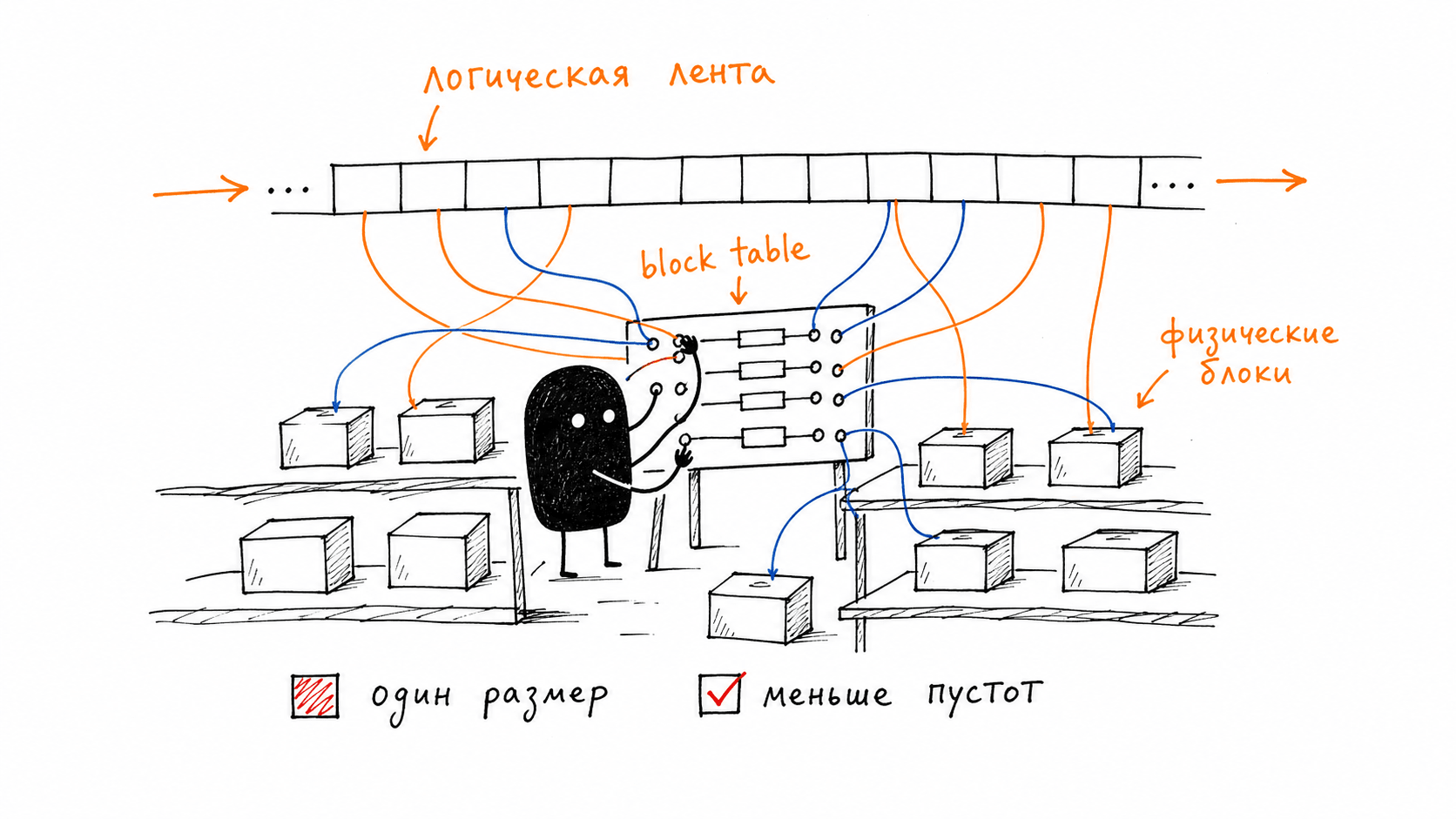
Memory waste collapses to almost zero: the only thing wasted now is the tail of the last incomplete block of a request, and the loss is limited to one block. Because freed memory can be given to real requests, vLLM increases throughput by 2–4× compared with the then-current FasterTransformer and Orca at the same latency. The very video memory that used to sit idle by two thirds under reservations now works.
Since blocks are separate addressable pages, one physical block can be attached to several logical ones at once. The engine keeps a reference counter, ref_cnt, showing how many requests currently hold this block. If one of them needs to change something in the block, copy-on-write triggers at the block level: a trick straight from operating systems. The paper’s authors describe the shared prefix as a shared library loaded into memory once and connected to many processes. One system prompt, computed once, physically sits in a single copy and serves a pile of requests. But for this to work, the engine must be able to quickly recognize “oh, I have already computed this block”. Exactly how it recognizes that is the most interesting part.
A git-style hash chain
The byte-level answer to the title’s question lies precisely in how these hashes are arranged.
At startup, vLLM cuts the block pool into fixed-size blocks. The default size is 16 tokens: in vllm/config/cache.py, this is DEFAULT_BLOCK_SIZE, and the value is configurable. The number was not pulled out of thin air. The original paper separately justifies it as a balance between GPU utilization and internal fragmentation. Each filled block can compute its hash, and here is what the block itself looks like (fields shortened, file vllm/v1/core/kv_cache_utils.py):
@dataclass(slots=True)
class KVCacheBlock:
block_id: int
ref_cnt: int # how many requests currently hold the block
_block_hash: ... # block hash; exists only when the block is filled and cached
prev_free_block: ... # block links in the LRU queue of free blocks
next_free_block: ...
The block hash is computed by the hash_block_tokens function. Its essence is in one line:
def hash_block_tokens(hash_function, parent_block_hash,
curr_block_token_ids, extra_keys):
return BlockHash(
hash_function((parent_block_hash, curr_block_token_ids, extra_keys))
)
Look at what goes into a block hash. The tokens of the block itself, curr_block_token_ids, are expected. Some extra_keys; we will return to them in the section on security. And most importantly, parent_block_hash, the hash of the previous block. The hash of block N includes the hash of block N−1, which includes the hash of block N−2, and so on back to the very beginning, whose parent is the starting seed NONE_HASH. You get a chain where every link has captured the whole history before it.
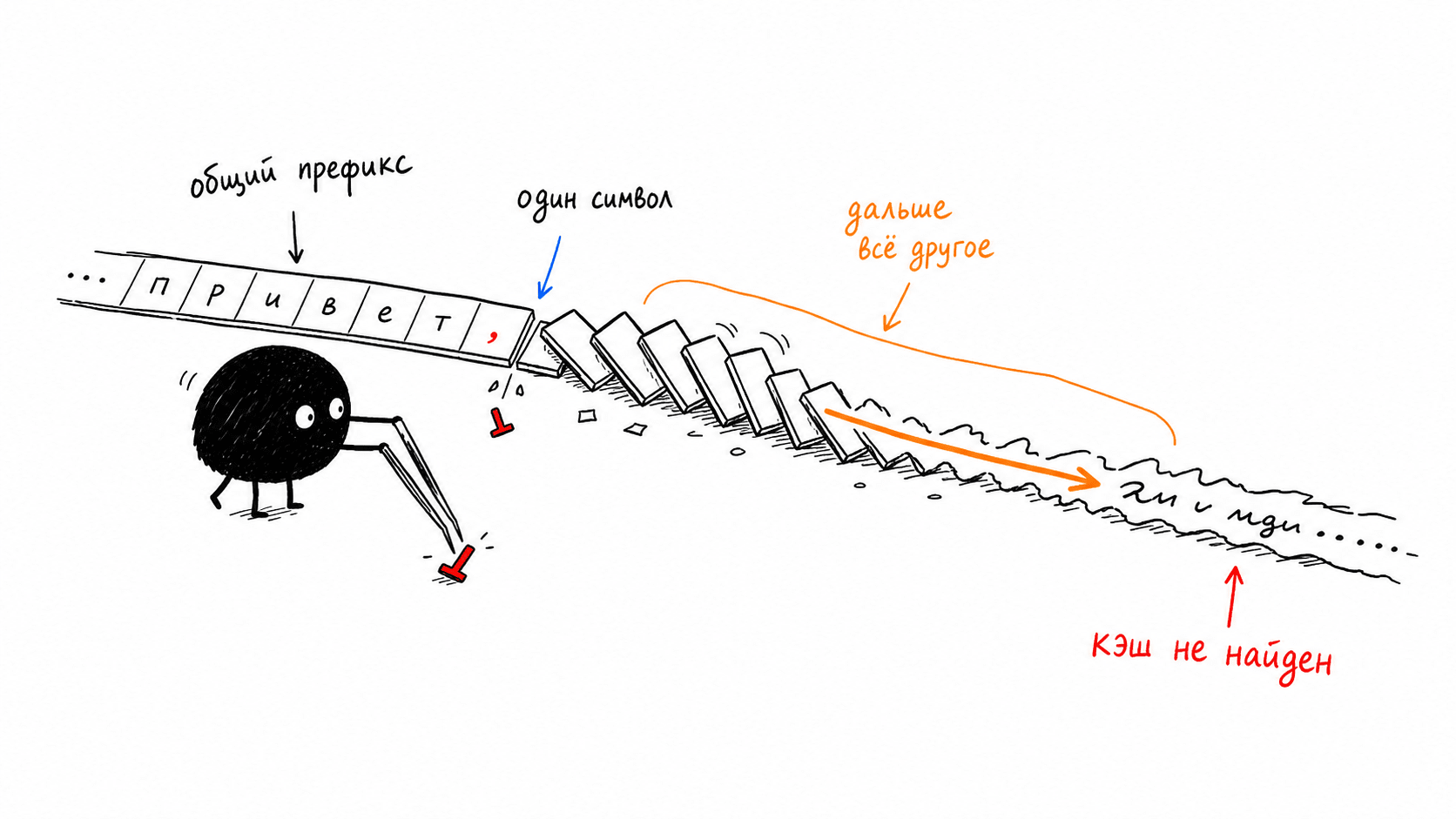
If this mechanism looks familiar, that is no accident. Git and blockchains are built this way. A commit ID in git is the hash of its contents plus the parent hash, so editing one old commit rewrites the identifiers of all commits after it. A block in a blockchain is chained to the previous block in exactly the same way. KV blocks in vLLM are chained by the same principle. If the hash of block N matches, then all blocks from zero through N−1 are guaranteed to match too: one check validates the entire prefix. No character-by-character comparison of thousands of tokens, just one hash comparison.
Change one token at the beginning of the prompt, and its block already has different curr_block_token_ids, which means a different hash. This hash was the parent_block_hash for the next block, so the next block’s hash shifts too. And so on to the end of the chain. One character at the beginning does not “slightly damage” the cache; it rewrites the identifiers of all blocks after it, and none of them can be found anymore. The fragility from the rule in the first part is not an engine whim or excessive caution; it is the arithmetic of the hash chain.

It is not worth simplifying this to “it is always sha256 there”: in the code, hash_function is the first argument and is pluggable. By default, vLLM uses sha256 with CBOR serialization, but xxhash is available nearby, and BlockHash is declared as a NewType over ordinary bytes (32 bytes is already a sha256-specific detail). The match lookup function itself is extremely straightforward. FullAttentionManager.find_longest_cache_hit walks through block hashes from the beginning and accumulates hits until it encounters the first miss:
# essence of the find_longest_cache_hit loop
computed = []
for block_hash in islice(block_hashes, max_num_blocks):
block = block_pool.get_cached_block(block_hash, ...)
if block is None:
break # first miss: nothing after this has been computed either
computed.append(block)
return computed
The authors fixed the logic of stopping at the first miss directly in a code comment: if a block’s hash is not in the cache, then all subsequent blocks are certainly not computed yet. This follows automatically from the chain, so looking further is pointless. The entry point here, KVCacheManager.get_computed_blocks, also passes this search a limit, max_cache_hit_length = num_tokens − 1. A small but honest detail: even if the entire prefix matches verbatim, at least the last token will have to be computed again; otherwise the model has nothing to feed as the Query for generation.
Under the hood, all of this is orchestrated by BlockPool. Hashes and blocks live in BlockHashToBlockMap with O(1) lookup, free blocks live in FreeKVCacheBlockQueue, a doubly linked list from which any block can be removed in O(1), and the head holds the LRU eviction candidate. When someone else’s request hits your block, touch raises the reference count and removes the block from the free queue. When a request ends, free_blocks decreases ref_cnt, and when it falls to zero, the block returns to the queue, from which _maybe_evict_cached_block will sooner or later evict it. Allocation, sharing, eviction: the whole life of a block in one class. And notice the words “someone else’s”: blocks here calmly move between different requests. That is not a slip of the tongue.
This cache is not yours
This thought changed my mental picture more than anything else.
Intuition suggests that the cache lives inside my conversation: I send turns, the engine remembers the beginning of my chat, and saves me tokens and dollars. That picture is wrong. Prefix caching works by content, not by conversation. Blocks are indexed by token hashes, and the hash does not care at all whose request it is. If another user arrives with a request whose beginning matches yours (the same system prompt, the same instruction header), their request will hit the blocks you computed and skip prefill for them entirely. And vice versa.
In other words, the shared system prompt of a public service is computed with all the expensive prefill work exactly once for everyone. After that, it simply sits as ready-made tensors in a shared pool and is handed out to everyone who starts with the same tokens. The very “shared library” from the paper, except different people connect to it. For a loaded service, this is an enormous saving, and it is what makes cheap caching possible in the first place.
But turn this thought half a step. If my request sped up because someone before me had already computed the shared beginning, then the speed of my request can be used to infer what was in the cache before it.
So the cache can be peeked into
A cache hit is fast, a cache miss is slow, and this timing difference is measurable from the outside. From here comes a timing side-channel: an attacker sends probe requests and determines by latency whether such a prefix has already been cached, meaning whether someone with the same beginning has passed through the service. For shared system prompts, this is harmless. But if something sensitive appears at the beginning of a request, the threat becomes tangible. This is not a hypothesis I made up: there is a separate paper, InputSnatch, precisely about stealing other people’s input through cache timings.
Remember the extra_keys in the hash formula that we passed over? This is their job. vLLM can mix a salt into the hash, cache_salt. The request parameter ends up in extra_keys, and only for the first block (in the code, the salt is added when start_token_idx == 0). Through the chain, the hash of the first block affects all subsequent blocks, so one point is enough. The effect is simple: only requests with the same salt share blocks. Give each tenant its own salt, and the cache is split into isolated namespaces; another user’s request physically cannot hit your blocks, even if the beginning matches verbatim. Isolation through one field in the request.
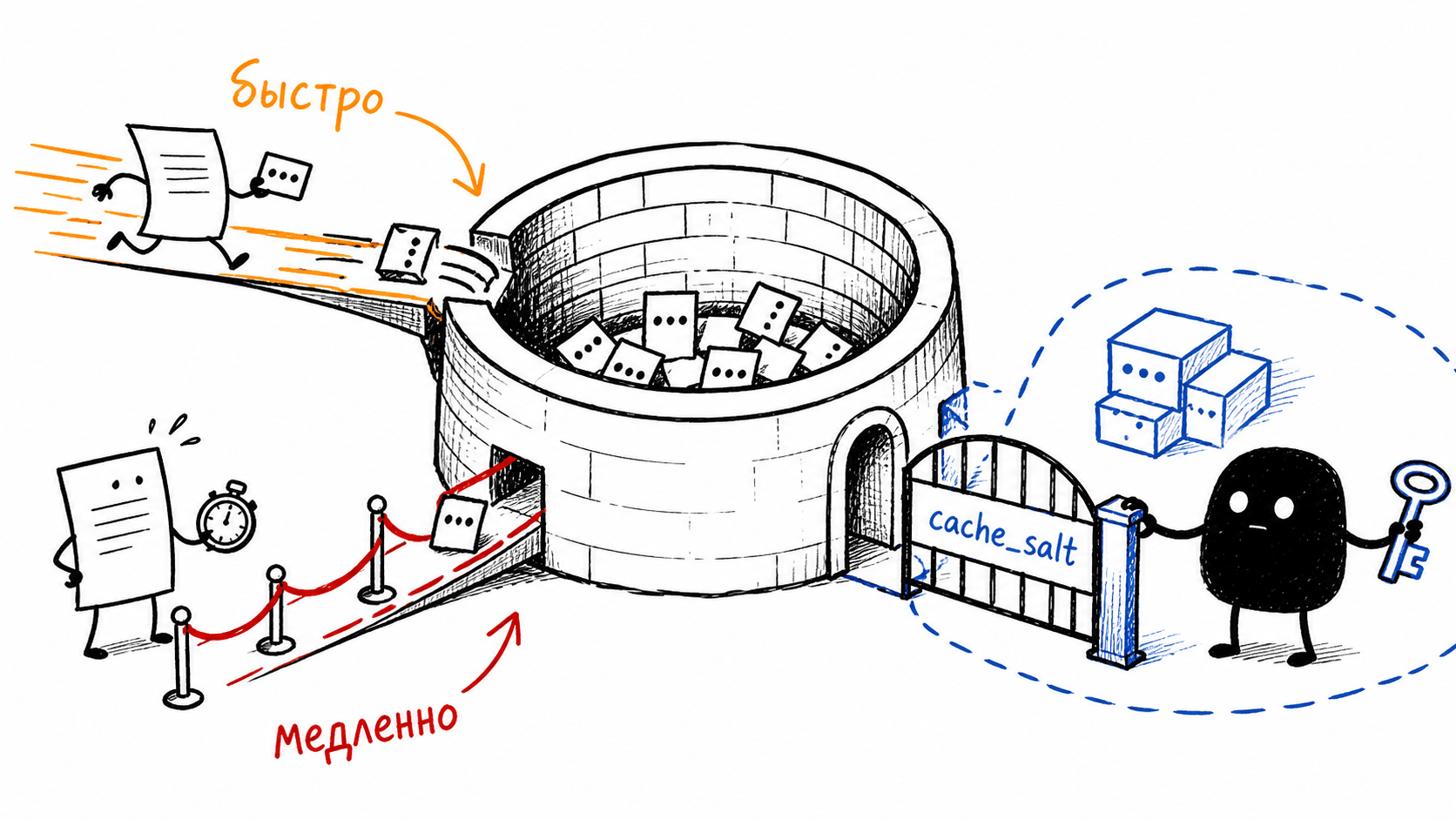
Provider caches live by a timer: OpenAI writes that a prefix is kept for 5–10 minutes of inactivity, up to an hour at the limit, and on newer models tensors are offloaded to GPU-local storage with retention of up to a day. This is provider behavior, not vLLM mechanics. vLLM itself has no time-based TTL; a block is evicted only by LRU and only when memory is needed for a new request. When you read about “cache lifetime”, keep in mind which layer is being discussed.
This is a law, not an implementation
After all this, it is easy to decide that prefix caching is simply “how vLLM implemented it”. A linear hash chain, blocks of 16, LRU. Change the engine, and you get a different cache. But the invariant and its embodiment here are not the same thing.
SGLang indexes reuse very differently. There, the KV-cache is not discarded but placed into a radix tree: keys are token sequences, values are their KV tensors. The tree can search for a shared prefix, insert a new path, and evict leaves by LRU on its own; it also gives branching out of the box: two sessions with a shared system prompt are two branches from one node. The data structure is different: not a hash chain, but a prefix tree. Moreover, different indexes coexist even inside one vLLM: for sliding window, it has its own SlidingWindowManager, which overrides that same find_longest_cache_hit for window logic.
A linear chain, a radix tree, a separate handler for a window. There are many index implementations, but what gets reused in all of them is the same thing: a matching token prefix. Why do all these different structures converge on the same thing? Because a token’s KV tensor has embedded into it everything to the left; causal attention leaves no alternatives. A shared prefix is the only thing that is physically valid to reuse, no matter what tree or chain you build over it. The invariant is dictated by the model mechanics, not by the taste of the engine authors.
This also gives the final symmetry that this rabbit hole showed me. Cache fragility and cache power are not two separate properties handled by different parts of the system. They are one property seen from two sides. The tensors are locked to the prefix, so the shared prefix can be skipped entirely (power), and for the same reason one changed token is enough to collapse everything after it (fragility). One cause, two consequences.
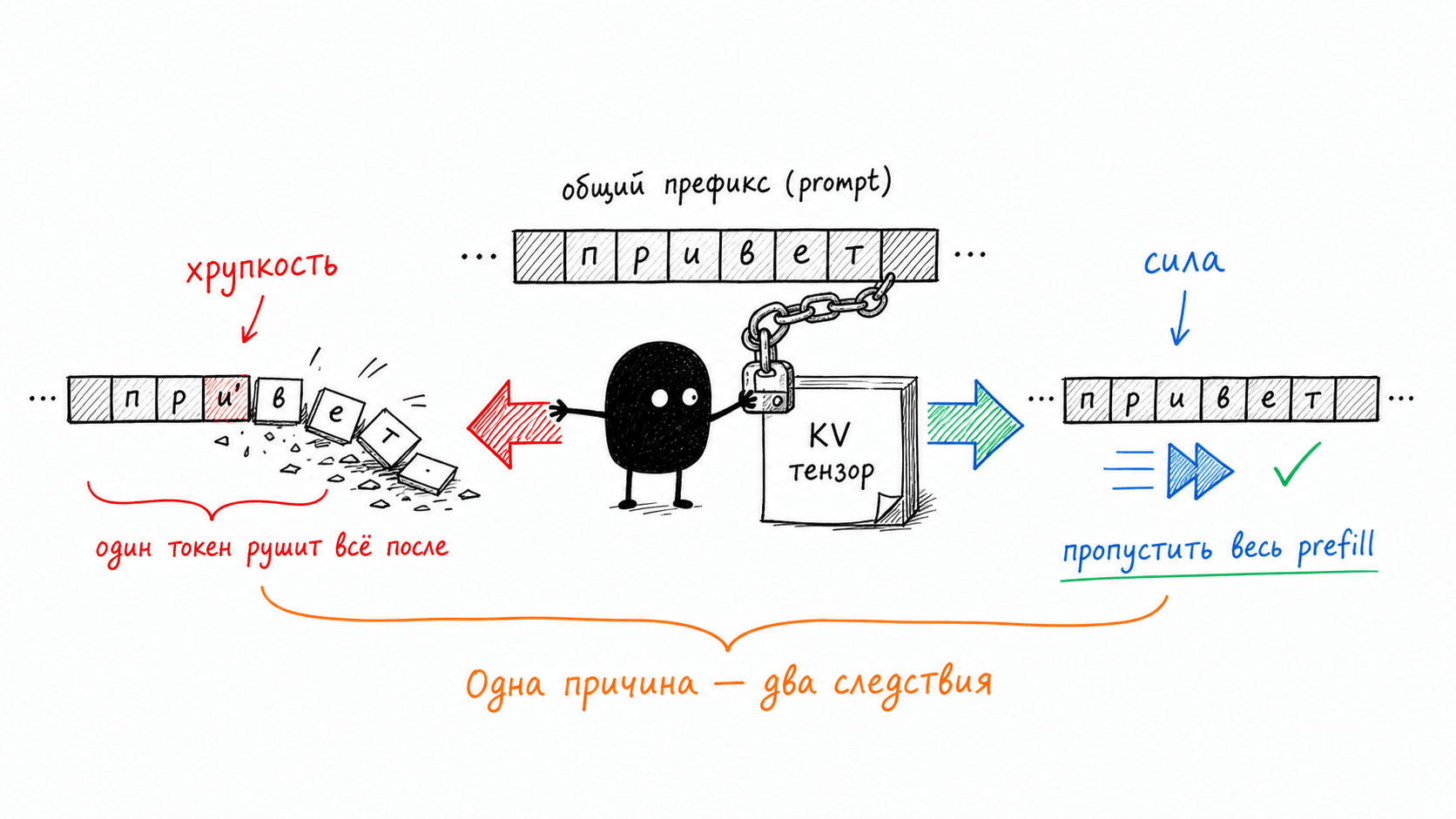
The rule from the first part, stable things at the beginning and changing things at the tail, has now become more transparent. Under it lies a hash chain in which an early token rewrites every link after it. The architectural tricks Claude Code uses to work around this fragility (Plan Mode instead of changing the tool set, deferred loading, careful compaction) were analyzed there, so I will not repeat myself. I will only say that their shared byte-level meaning is now visible: they are all about one thing, not touching the early prefix blocks so the hash chain does not shift. The rabbit hole ended in the same place as the rule from the first article, except now it is not an incantation, but a mechanism visible down to the last block.
Stay curious.
I write about artificial intelligence, language models, and tools for developers. I test models and services on real tasks, and share my conclusions in my Telegram channel.
Frequently asked questions about KV-cache and prompt caching
What is KV-cache?
KV-cache is the saved key/value tensors of each token, its internal representation inside the model. To process a new token, the model needs the Key and Value of all tokens to the left, so they are computed once and kept in memory to avoid recomputing the read prompt from scratch at every generation step. On a model like Llama-2-7B, such a cache weighs about 512 KiB per token.
Why does changing one token at the beginning of a prompt break the entire cache?
Because a token’s key/value tensor depends on the entire prefix to the left: this is causal attention. vLLM stores blocks and links them in a git-style hash chain: a block hash includes the parent hash. Change one token at the beginning, and its block gets a different hash; every block after it gets a different hash too. None of them can be found in the cache anymore, and prefill runs again.
What is PagedAttention?
PagedAttention is a vLLM technique that transfers the virtual-memory idea from operating systems to the KV-cache. The cache is cut into fixed-size blocks (16 tokens by default), and a block table connects the logical order of tensors with their physical address in VRAM. This removes fragmentation and allows several requests to share one physical block of a common prefix.
How much memory does KV-cache take per token?
It depends on the architecture: 2 × number of layers × number of KV heads × head dimension × bytes per value. For Llama-2-7B (fp16), this is about 512 KiB per token. With GQA or MQA, where there are fewer KV heads, cache per token drops by a factor of several. There is no universal number; the number lives with the architecture, not with the parameter count, and the short formula through d_model overestimates the result for GQA/MQA.
How does prefix caching in vLLM differ from SGLang?
The same thing is reused: a matching token prefix, but it is indexed differently. vLLM links blocks into a linear hash chain; SGLang puts KV tensors into a radix tree (prefix tree) and shares a common prefix between several branches out of the box. The index structure is an engine choice, while the dependency on the shared prefix is dictated by the mechanics of causal attention itself.
Can someone peek into another person’s cache through timings?
Yes, this is a timing side-channel. A cache hit is faster than a miss, and the difference is measurable from the outside: latency reveals whether a request with the same beginning has passed through the service before (the InputSnatch paper is about this). For shared system prompts this is harmless, but if sensitive data gets into the beginning, the threat is real. vLLM isolates caches by tenant through cache_salt: the salt is mixed into the hash of the first block.


