Weekly Hallucinations: GPT-5.4, MacBook M5 Max, and 630 Lines That Automate ML Research
Author: Aleksei Beltiukov
Another flagship model from OpenAI with a million-token context window, Claude doing code review, Google updating its speedy little model, a new MacBook for local inference. And what about Titov?
OpenAI released GPT-5.4 and GPT-5.4 Pro at the same time, which is unusual for them, as the Pro version normally arrives a couple of weeks later. This is the first model in the 5.x family that combines coding and reasoning tasks in one place. Context window up to 1M tokens, native computer use.
To enable the 1M context window in Codex, you need to add this to config.toml:
model = "gpt-5.4"
model_context_window = 1000000
model_auto_compact_token_limit = 900000
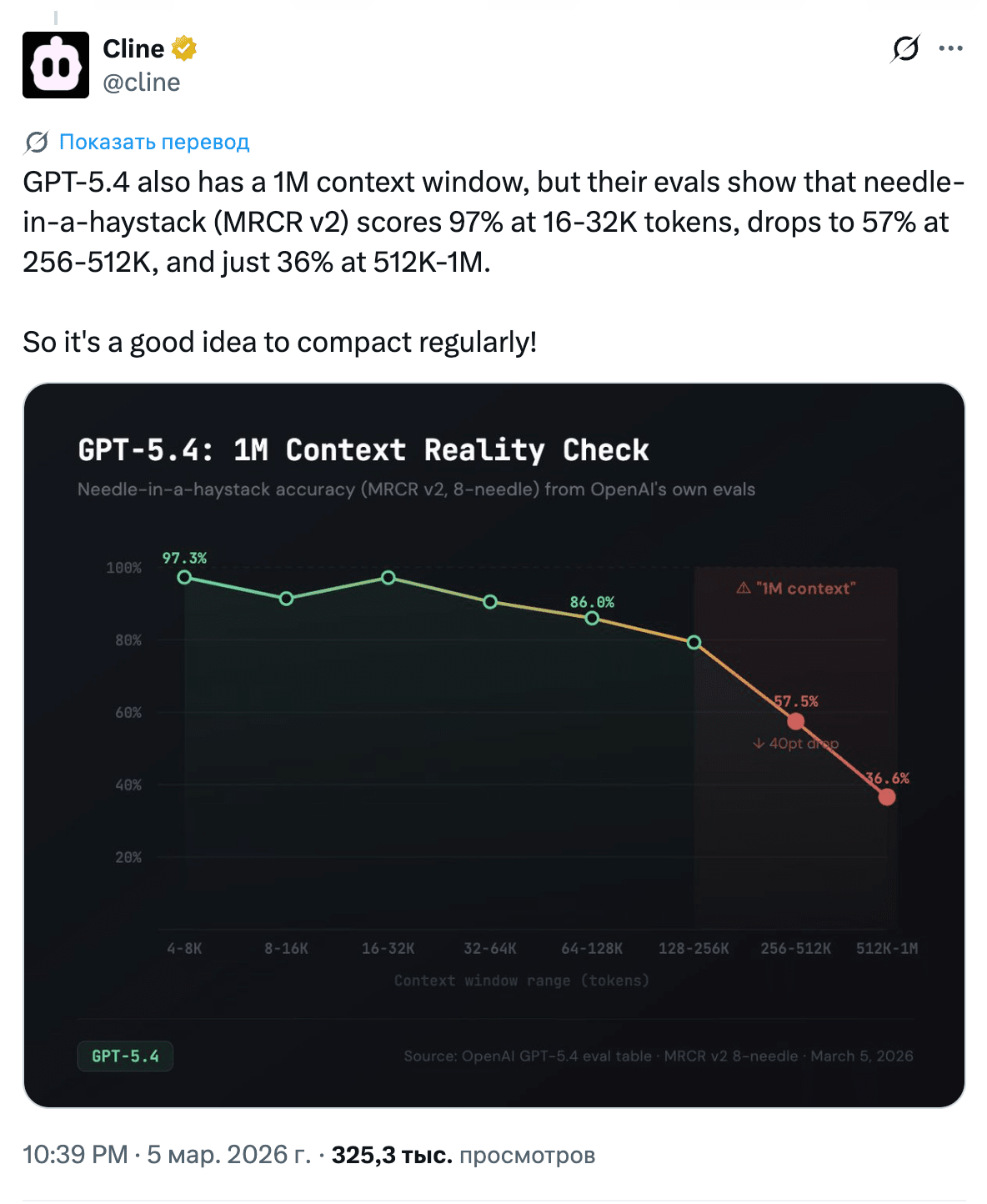
But there are caveats. A million-token context window does not mean a million useful tokens: at 16–32K, accuracy is ~97%; at 256–512K, it drops to 57%; and at 512K–1M, it is already 36% (source). On top of that, in Codex, after 272K, usage consumption doubles at 2x the normal rate. So the real ceiling still remains somewhere around 256K.
Over the last month, I’ve written 80% of my code with 5.3-Codex, and 5.4 feels like a logical continuation. Instruction following has improved noticeably, and the code reads more naturally. I expect it also got better at design/frontend work, but I usually delegate those tasks to Opus 4.6. Codex also got a /fast mode, giving up to 1.5x faster generation in exchange for double usage consumption.
They finally released Codex for Windows with native OS-level sandboxing (ACLs, restricted tokens, dedicated users). Support includes PowerShell, CMD, Git Bash, and WSL. They also launched the Codex for Open Source program: maintainers of major projects get six months of ChatGPT Pro with Codex, access to Codex Security, and API credits for automating reviews and releases. Anthropic has an analogous program as well: 6 months of Claude Max 20x for maintainers of repositories with 5,000+ stars or 1M+ downloads on NPM.
And a bonus: over the course of a week, OpenAI reset Codex limits 3–4 times, each time explaining it as a newly discovered bug. It has already become a meme in the community.

Anthropic launched Claude Code Review, a multi-agent system where parallel agents look for issues, verify findings, and rank them by severity. Internal metrics: the share of PRs with meaningful comments rose from 16% to 54%, while less than 1% of findings turned out to be incorrect. And right in the thread, Anthropic wrote that one review costs about $15–25.
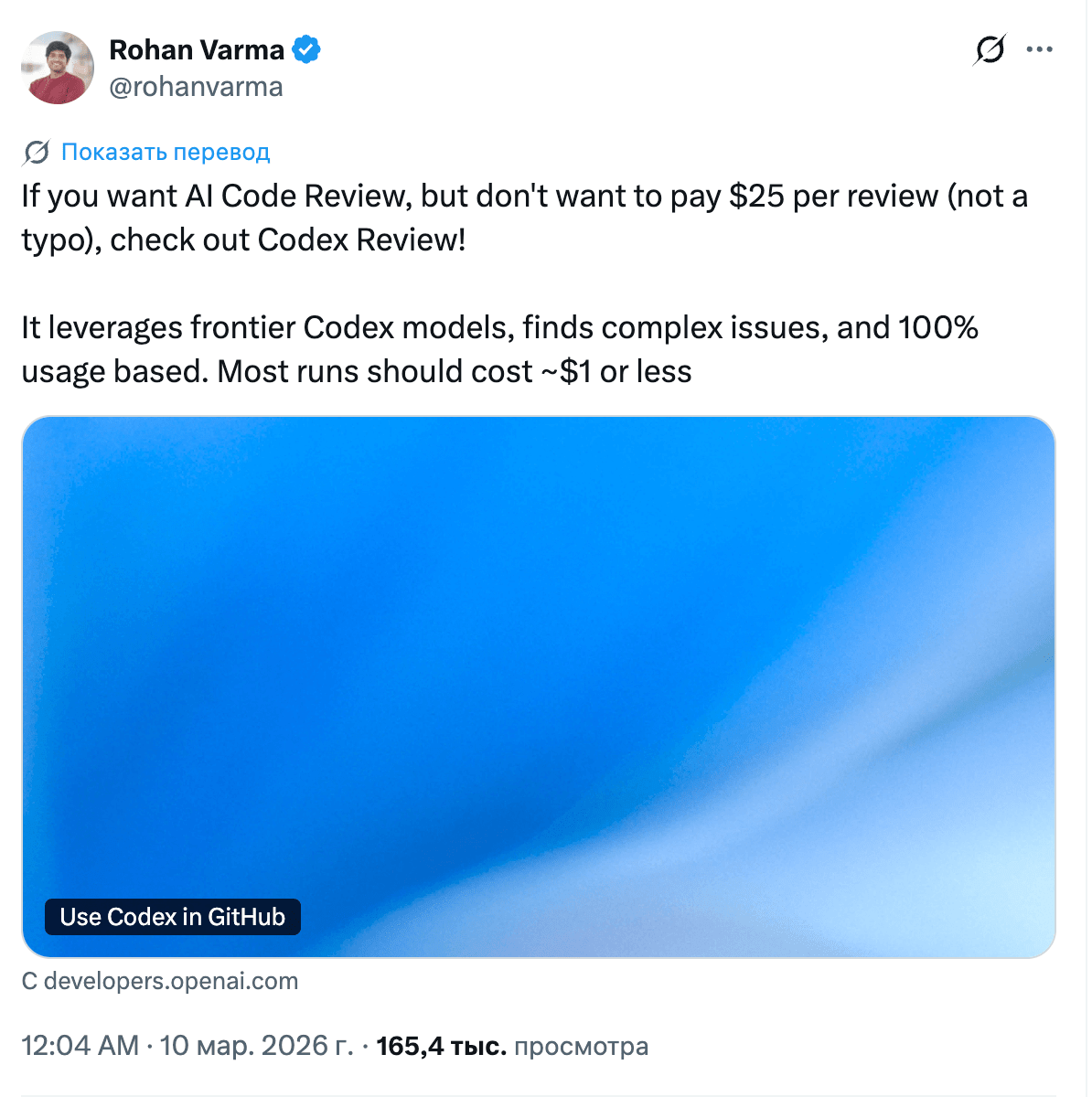
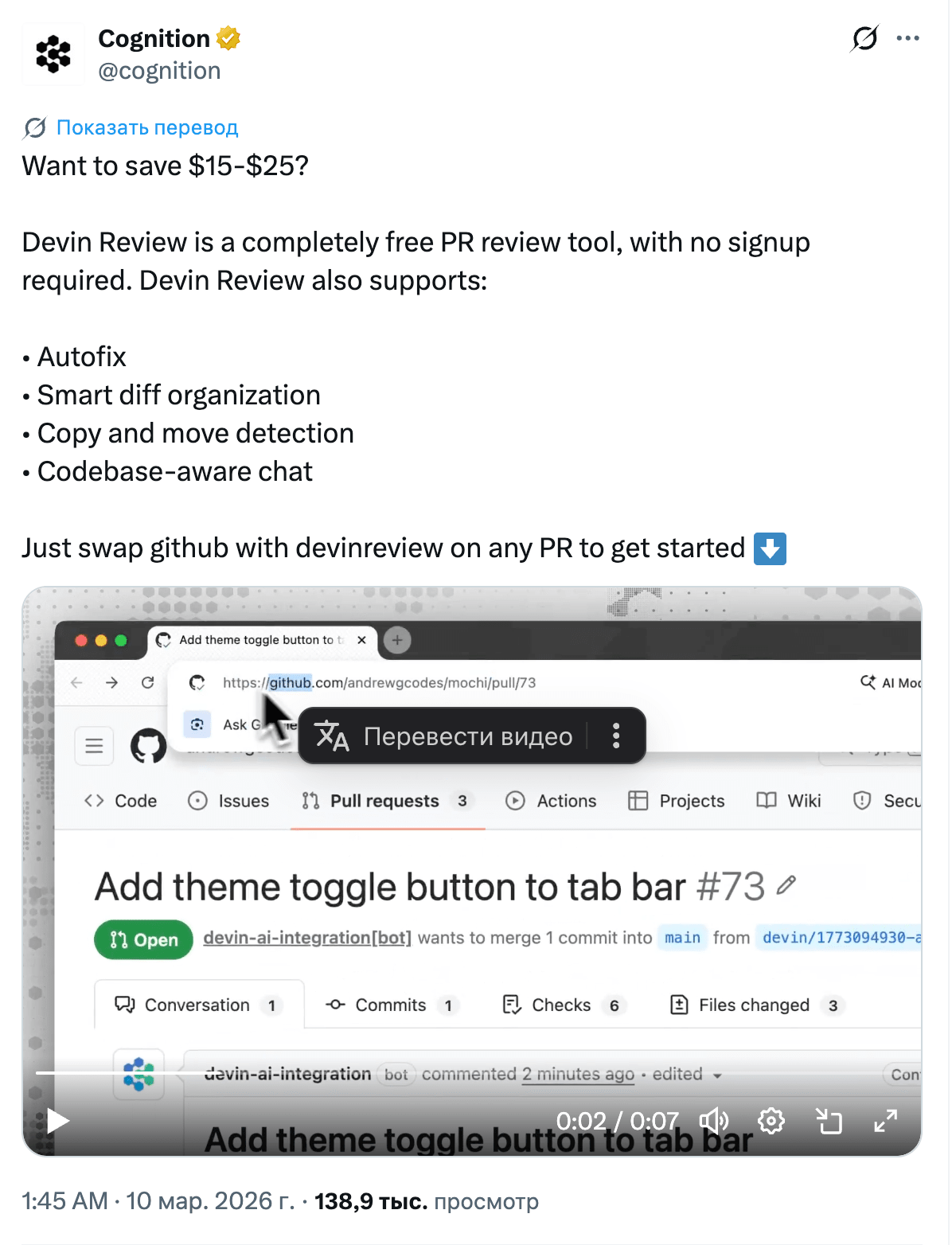
The industry has reached a consensus: the code generation problem is solved; the bottleneck is now verification. A two-agent architecture of "generator + reviewer" is becoming the standard, much like unit tests once did.
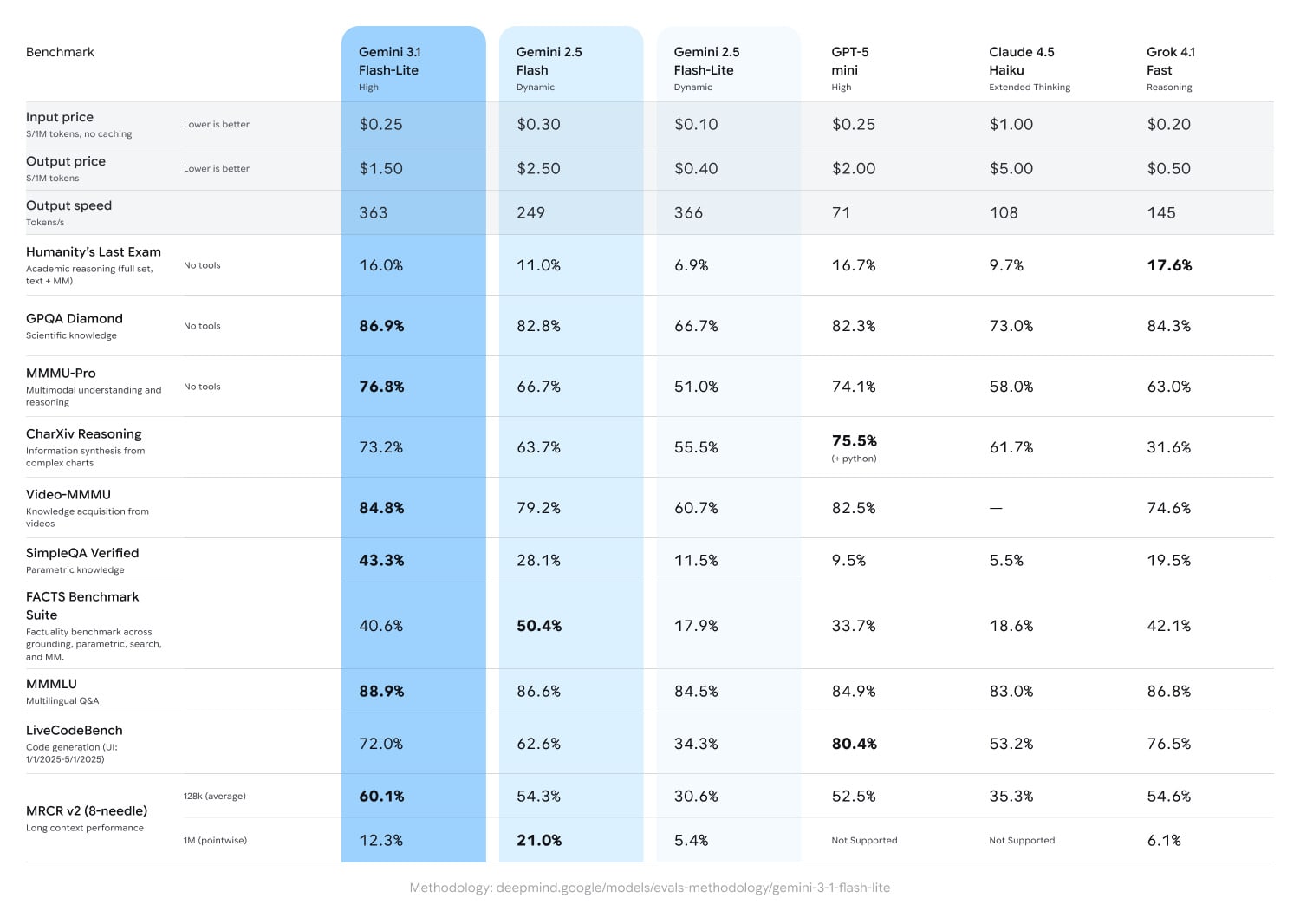
Google rolled out Gemini 3.1 Flash-Lite. It has an adjustable thinking level, where you choose the balance between intelligence and speed yourself. More than 360 tok/sec and a million-token context window are claimed. Yes, it became more expensive compared to its predecessor Gemini 2.5 Flash-Lite: $0.25/$1.50 per million tokens. Google is not trying to compete with flagship models; in its own benchmarks, the model is compared to GPT-5 mini and Claude Haiku, not Opus or GPT-5.4. This is a workhorse for pipelines: multimodal input (text, images, video, audio, PDF) at high speed instead of custom parsers. I happily switched both my summarizer and translator to the new model.
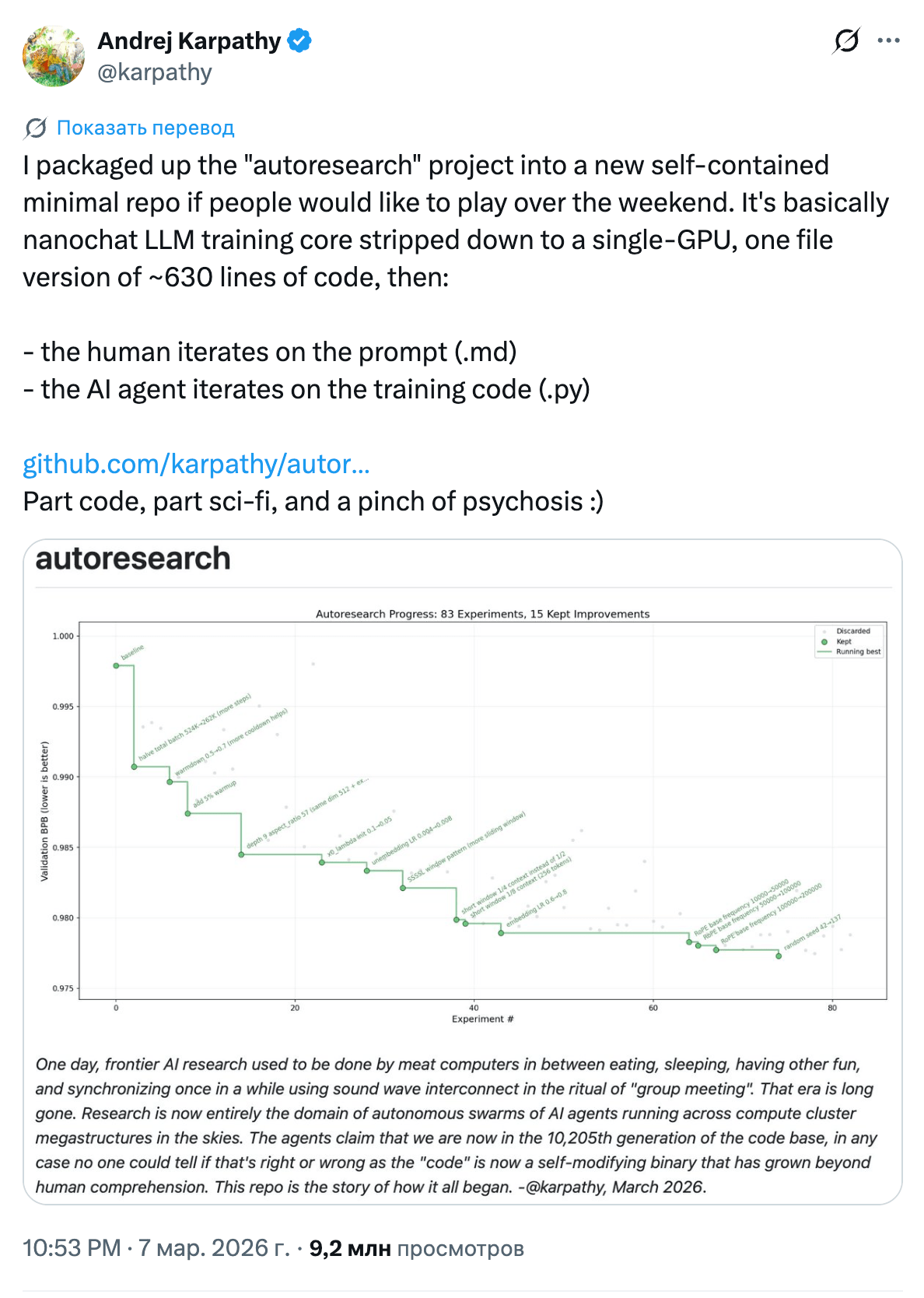
Andrej Karpathy released autoresearch, a repository of about 630 lines. The idea is simple: an AI agent in a loop changes parameters on its own, runs an experiment, looks at the result, and tries again, without human involvement. Across ~700 such iterations, the agent found 20 improvements that reduced GPT-2 training time by 11%. And the improvements transfer to larger models as well. Back in December 2025, Yi Tay coined the term vibe training for this kind of approach: you do not look at what the agent changes, you just check the metrics. Autoresearch is essentially the first working implementation of that idea.
Autoresearch is already being used not only for training: the CEO of Shopify adapted the framework for his project qmd, ran 37 experiments overnight, and got a 19% improvement on a 0.8B model. Karpathy himself talks about the next step: distributed research in the style of SETI@home. By the way, GPT-5.4 xhigh loses to Opus 4.6, which calmly runs 118 experiments over 12+ hours. The problem has been confirmed by the author.
I wrote about the Qwen 3.5 models last week, and 9B is still working away on my machine. But this week, something else matters more: the team’s technical leader left, followed by several other key people, including Hui Binyuan (lead of Qwen Code), who moved to Meta. As a replacement, Alibaba hired Zhou Hao from Google DeepMind. The CEO of Alibaba Cloud promised to continue the open-source strategy, but when people leave, promises are worth less than code.
Apple introduced new MacBooks based on M5 Pro and M5 Max. M5 Pro: up to 64GB of unified memory, 307GB/s memory bandwidth. M5 Max: up to 128GB, 614GB/s. SSD up to 14.5GB/s (twice as fast as M4). The key number for us: LLM prompt processing up to 4x faster than M4. For those running models locally, this is the most significant update of the year.
Tri Dao released FlashAttention-4, which reaches matmul-level attention speed on Blackwell. It is written in CuTeDSL (embedded in Python) and compiles in seconds instead of minutes. PyTorch integrated FA4 into FlexAttention, with a 1.2x–3.2x speedup on compute-bound workloads. Here is the link for those who like digging into papers.
And vLLM rolled out v0.17 with support for FA4, Qwen3.5 GDN, a 5.8x attention speedup on MI300 thanks to a new Triton backend, and, interestingly, operation on NVIDIA Jetson without cloud APIs. Local inference without the cloud is no longer fantasy.
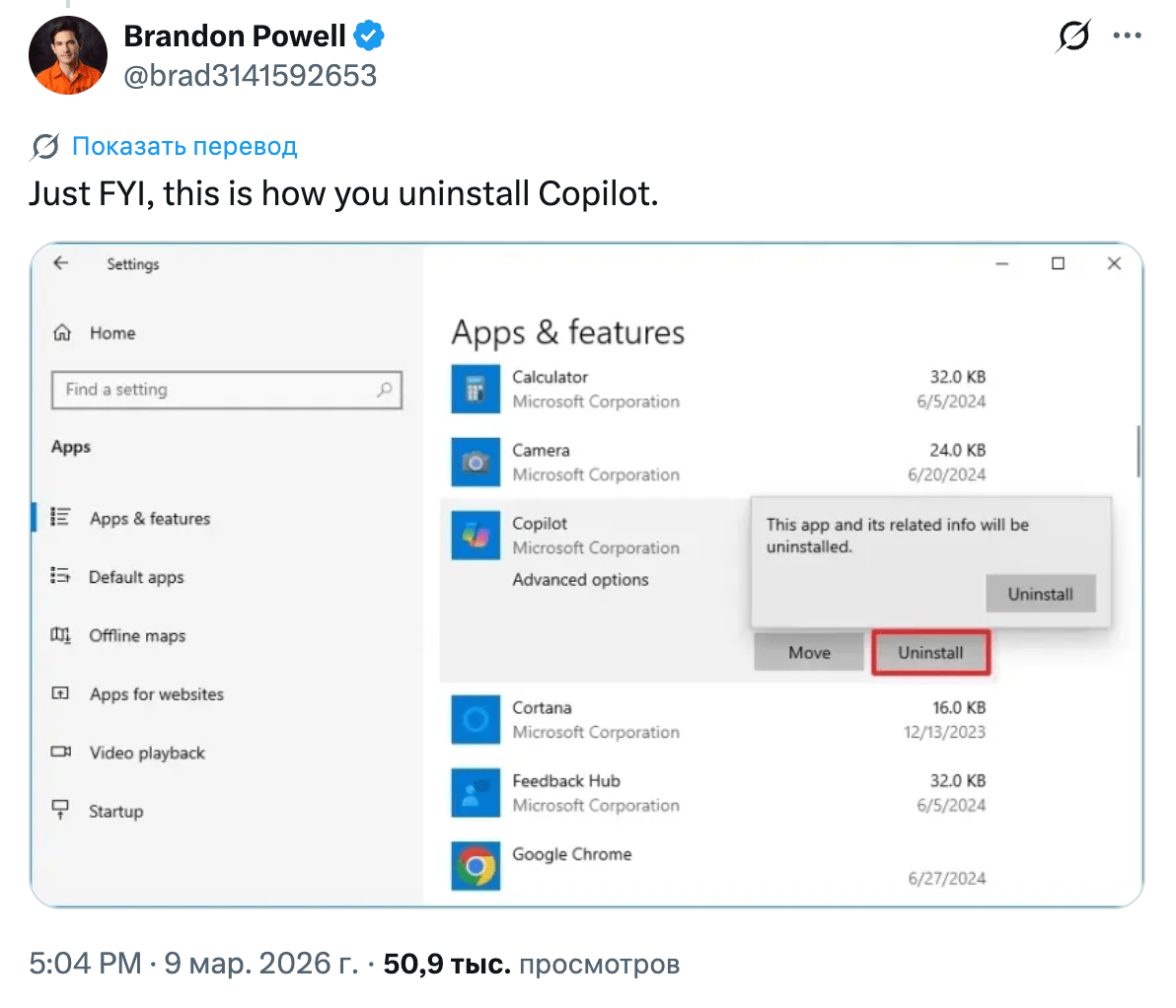
The release that stood out because of the community reaction: Microsoft Copilot Cowork. The website release says: "Working closely with Anthropic, we integrated Claude Cowork technology into Microsoft 365 Copilot." Weren’t you supposedly all over OpenAI?
In the announcement thread, you can immediately see how users feel about Copilot.
Some arithmetic for dessert. On the Codex page, you can see the 5-hour limits for GPT-5.4 (OpenAI does not disclose the weekly ones):
┌─────────┬─────────────────┬───────────┐
│ Option │ Message limit │ Cost │
├─────────┼─────────────────┼───────────┤
│ 1× Pro │ 223–1120 │ $200/mo │
├─────────┼─────────────────┼───────────┤
│ 7× Plus │ 231–1176 │ $140/mo │
└─────────┴─────────────────┴───────────┘
If you use Codex, you can save $60. Here is the link showing how to implement it.
Think. And stay curious.