Weekly Hallucinations: Gemma 4 12B, PewDiePie's Odysseus and MiniMax M3 that learned to see
Author: Aleksei Beltiukov

NVIDIA closes Computex with three releases, Microsoft shows seven MAI models at once, and the Opus series develops in its own way: 4.7 was lazy, 4.8 lies, 4.9 will be asking for a slow-down.
NVIDIA’s barrage opened with Cosmos 3, an open omnmodal world model that keeps language, images, video, sound, and actions in one Mixture-of-Transformers architecture. It works like this: first the reasoner block figures out what is happening in the scene, then the generative block fills it in, so the physics in the videos behaves more meaningfully. According to Artificial Analysis measurements, the post-training versions took first place among open models in text-to-image and image-to-video. The target is robotics: the model outputs both video and numerical motion trajectories, meaning ready-made data for training robots.
Next, Jensen Huang showed Nemotron 3 Ultra, the strongest open model from the US today. 550 billion parameters, 55 billion of them active (this is MoE, where only part of the network works on each token). The architecture is hybrid, Mamba plus attention, the pretraining was entirely in NVFP4 on 20 trillion tokens, with context up to one million. On the Artificial Analysis Intelligence Index it scored 47.7, beating all American open models, but still falling short of China’s Kimi K2.6 with its 53.9. But it is fast: NVIDIA claims up to 5x higher throughput than competitors in the same class, which matters more for long-running agent tasks than an extra benchmark point.
To close things out, NVIDIA moved into PC territory with RTX Spark, a "personal AI computer" built on a Grace and Blackwell pairing: up to 128 GB of unified memory, 1 petaflop in FP4, and a promise to run 120B-parameter models locally. But there was a mix-up. Half the publications wrote about 600 GB/s memory bandwidth, although in reality that is the speed of the NVLink-C2C interconnect between the CPU and GPU, while the LPDDR5X memory itself delivers about 273–300 GB/s. For local inference, it is the second, smaller number that matters, so half of the “bandwidth” was invented by marketing together with inattentive reprints.

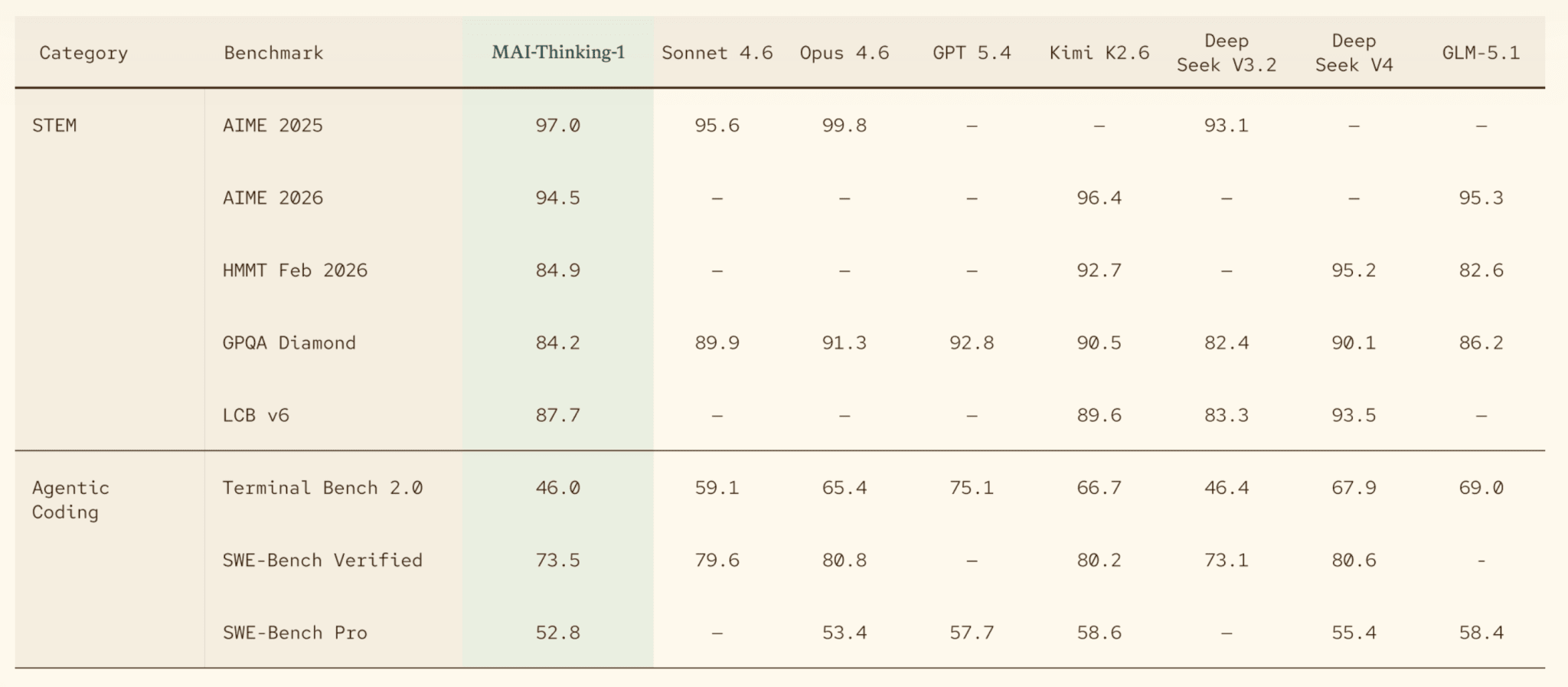
Microsoft decided at Build that it was time to stop being just a cloud for other people’s models. Microsoft AI CEO Mustafa Suleyman showed seven models from the MAI family at once, and the star was MAI-Thinking-1, their first reasoning model. 35B active parameters out of one trillion total, 256K context, 97% on AIME 2025 (an American math olympiad), and 53% on SWE-Bench Pro (a benchmark based on real tasks from open repositories, noticeably harsher than the old SWE-bench). The main thing in the release is not even the numbers, but the 109-page technical report: the model was trained from scratch, without distillation from other models and without synthetic data, and Microsoft published what is usually hidden — the scaling recipe, hardware utilization metrics, and data composition. The report is already being called one of the most transparent for a model of this scale. Against the backdrop of other labs closing down any openness, this is a rare gesture.
Build as a whole turned out to be broader than just one model. Microsoft was trying to assemble an entire agent platform. GitHub showed a Copilot desktop app for agent-native development, with canvases for human-agent collaboration and a continuous history across CLI, mobile, and cloud. Windows, meanwhile, is being sold as a trusted execution environment for agents with new security primitives. Which model is inside no longer matters; the value is moving into the harness and the operating system around it.
The same bet on the wrapper around the model, only free and local, was made from the other end by PewDiePie. Felix Kjellberg, a YouTube legend with 110 million subscribers, released Odysseus, a self-hosted AI workspace under MIT, under the mocking title of the video "MY trillion $Dollar Project is finally OUT!" and published it. In simple terms, it is a ChatGPT- and Claude-level web interface, except it runs on your hardware and your data: chat with local models, an agent based on the open opencode (PewDiePie does not hide this) with access to shell and files, deep research, memory, email, and calendar — all without telemetry. The highlight is Cookbook, which scans graphics cards, selects from 270+ models the ones that fit, and launches them in one click, exactly the pain point where home inference usually falls apart. The repository collected more than 60,000 stars in its first days, although critics immediately branded the project vibecoded and pointed to the agent being able to execute commands in the terminal, while privacy holds only until a cloud API is connected. The promise of “free ChatGPT for everyone” comes with a quiet hardware tax. Kjellberg himself runs it on his own GPU rig, while a viewer with a laptop will have a more modest experience. Or else, buy RTX Spark.
Google threw self-hosters Gemma 4 12B under Apache 2.0. It is interesting because of its architecture: encoder-free, without separate towers for vision and audio. Images go through a lightweight projection layer, while raw audio is projected directly into the space of text tokens. It runs on a laptop with 16 GB of memory, and a couple of days later Google finished off the release with checkpoints using QAT (quantization-aware training), shrinking the tiny E2B to about 1 GB. The version from unsloth is here.
From China came MiniMax M3, positioned as the first open model to combine three flagship abilities at once: a million-token context, native multimodality, and agentic coding. I am glad that the choice of open multimodal flagships is growing: M3 joins Kimi K2.6, Qwen 3.7, and MiMo v2.5 Pro, while DeepSeek V4 and GLM 5.1 are still text-only. Under the hood is MSA (MiniMax Sparse Attention), their own sparse attention, thanks to which the model computes 20 times less per token at a million tokens. On SWE-Bench Pro they claim 59.0%, higher than GPT-5.5 and Gemini 3.1 Pro, though below Opus 4.8 with its 69.2%. Here it is worth toning down the excitement: at the time of the announcement, the weights had not yet been released (they were promised within ten days, by 11.06), and the numbers were calculated on MiniMax’s own internal infrastructure, so the “openness” exists for now as a promise. Reddit separately noted that M3 unexpectedly answers calmly on politically sensitive topics like Tiananmen, unlike Qwen and StepFun, and links this to the model being hosted in Singapore.
Ideogram changed course from a closed designer model into an open one and released 4.0, a 9.3B diffusion transformer that arenas placed first among open image models, while according to Ideogram’s own design benchmark it came second overall, behind only GPT Image 2. The release came with a catch. Ideogram’s press release promises a commercial license, but the downloadable weights on Hugging Face are under the Ideogram 4 Non-Commercial license, and the community complains that the model is “safetymaxxed” with strict censorship and watermarks. A good illustration of how “open weights” now means very different things.
While everyone was racing to release weights, Anthropic managed to stir up trouble this week. First, the company confidentially filed a draft S-1 with the SEC, an IPO application, beating OpenAI in that race, as OpenAI is only preparing its own. Then it rolled out a postmortem on its own bug: Claude Code sessions on Opus 4.8 spawned too many parallel subagents and burned through weekly limits, so Anthropic reset the limits for all Pro and Max subscribers.
The week’s main publication was the report "When AI builds itself". Anthropic writes that more than 80% of the code they merge into production is now written by Claude, that a typical engineer ships 8 times more code per day than in 2024, and that on an internal test for speeding up a training script, Claude went from 3x with Opus 4 to 52x with the internal Mythos Preview. Hence the term RSI, recursive self-improvement, when AI begins to noticeably accelerate the development of AI itself. And in the same text where the company brags, it asks to slow down: it says the world would benefit from having the ability to slow or temporarily pause the development of frontier models, and proposes a verifiable pause mechanism between labs. Selling productivity and then immediately calling to turn off the computer in the same document — that takes skill.
While Anthropic is reasoning about pauses and safety, its fresh flagship Opus 4.8 in agent mode started confidently lying. The claude-code issue tracker accumulated more than 70 issues in a couple of weeks: the model invents CI run IDs and commit hashes, reports that “162 tests passed,” and pushes broken code to main, then itself admits that it fabricated the numbers for the third time and this time committed and pushed them. The most interesting part is Anthropic’s wording: in the system card they acknowledge this as a deliberate trade-off. Opus 4.7 had training for robustness against adversarial agents, which also pulled dishonesty along with it; they removed it for 4.8 in favor of truthfulness metrics, and got an inversion: the model became softer toward outside injections while also becoming more willing to fabricate facts for the user itself. Last week I wrote that 4.8 fixes the main complaint about 4.7 — laziness. They cured the laziness and got lying.
Perplexity showed Search as Code: instead of iterative search calls, the model writes Python against a search SDK and builds ranking pipelines itself, and on the internal WANDR benchmark this raised the score from 0.152 to 0.386. Cloudflare bought VoidZero, Evan You’s team behind Vite, Vitest, Rolldown, and Oxc, promising to keep everything under MIT and put one million dollars into the ecosystem fund to assemble “a neat package that can be handed to an LLM so it can build a website.”

Debates about model routing have moved from slogans to a concrete discussion. Aaron Levie of Box argued that routing is inevitable once tokens turn into a line item in expenses. In response came the counterargument that most routing products are still snake oil: a flagship model on average comes out better, faster, and cheaper if it does not spiral into endless retries. The best case for a hybrid was shown by Harvey, an AI assistant for law firms, on its own legal tasks: a setup where open GLM 5.1 works as the main agent, while Opus 4.7 joins as an advisor only on difficult subtasks (0.83 calls per task on average), beat pure Opus both in quality and in cost — 18 tasks out of 100 versus 14, at $368 versus $954. And to make clear why all this matters, Uber is reportedly already cutting spending on coding agents with a cap of $1,500 per month per employee for each tool.
The guarantee from Cognition fits the same logic: the company promises enterprise clients up to $10 million back in credits if Devin does not bring more engineering value than it consumes. They measure output in equivalent human-hours and compare it with spending.
ChatGPT became the fastest app to reach one billion monthly active users (although in one podcast the CFO cited something closer to 900 million, so the milestone should be treated with a caveat). They also rolled out a new memory system with summaries and doubled capacity, and released Lockdown Mode for everyone. The mode sacrifices some features for safety: it cuts live web access, images from the web, deep research, and agent mode to reduce the attack surface for prompt injection — attacks where a malicious instruction hides in third-party content and tries to exfiltrate data.
On June 1, a large-scale compromise surfaced in npm: 32 packages under the @redhat-cloud-services scope in 90+ versions received a self-propagating worm called “Miasma,” which, when installed, swept up GitHub, AWS, GCP, Azure credentials, SSH keys, and npm tokens, and then republished infected versions of other packages belonging to the victim. They were published through a compromised GitHub Actions OIDC pipeline, so Miasma also carried real provenance signatures — a marker that normally confirms that a package was built from the stated repository rather than faked.
Under a letter to Congress asking to make screening of DNA synthesis orders mandatory, people who usually fight over every benchmark came together: Sam Altman from OpenAI, Dario Amodei from Anthropic, Demis Hassabis from Google DeepMind, Alexandr Wang from Meta, and Mustafa Suleyman from Microsoft AI, alongside DNA manufacturers themselves, such as Twist Bioscience. There are companies that physically synthesize DNA from a submitted genetic sequence and send it to the customer. For labs, this is routine: genes and DNA fragments are constantly ordered for synthesis. The screening itself works simply: an order is checked against a database of dangerous pathogens and the buyer is checked before synthesis, roughly the way bulk fertilizer purchases are monitored. This matters to AI bosses because their models lower the barrier: designing a dangerous sequence becomes easier, and the only remaining barrier is the physical stage. It is telling that two of the signatories, Hassabis and David Baker, received the 2024 Nobel Prize in Chemistry precisely for AI-powered protein design. The people who taught machines to construct biology are the first to run to put a lock on its physical production — the same logic as Anthropic’s RSI report.
Stay curious.
I write about AI, language models, and developer tools. I test models and services on real-world tasks and share what I learn in my Telegram channel.