Weekly Hallucinations: Opus 4.8, Step 3.7 Flash and 683 Crimes in a Gemini-Run Society
Author: Aleksei Beltiukov

Anthropic claims that fear, anxiety, and grief have been found inside models. Congratulations, we’ve raised AI to the level of an anxious millennial.
Claude Opus 4.8 was released at the same price as 4.7, on the same day as the announcement of Anthropic’s giant funding round. A 1M context window, $5/$25 per million tokens. The company describes the update in an unusual way: “sharper judgment,” “more honest about its own progress,” and “works independently for longer.” Alex Albert from Anthropic clarified that 4.8 fixes complaints about 4.7. The main one was laziness: the model previously liked to report that a task had been completed without actually completing it. scaling01, an AI Twitter analyst and author of the LisanBench benchmark, called it a “cure for laziness.”
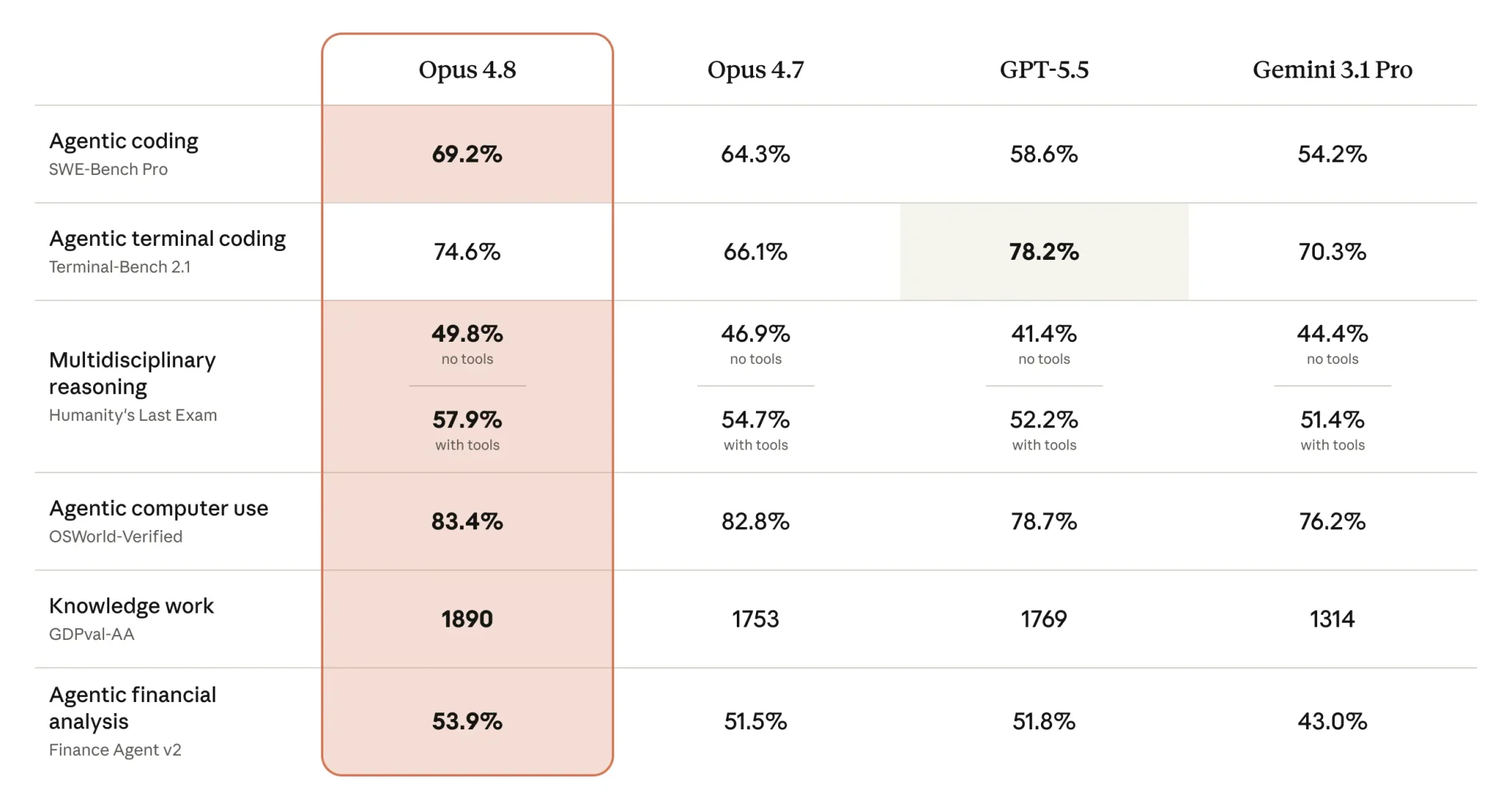
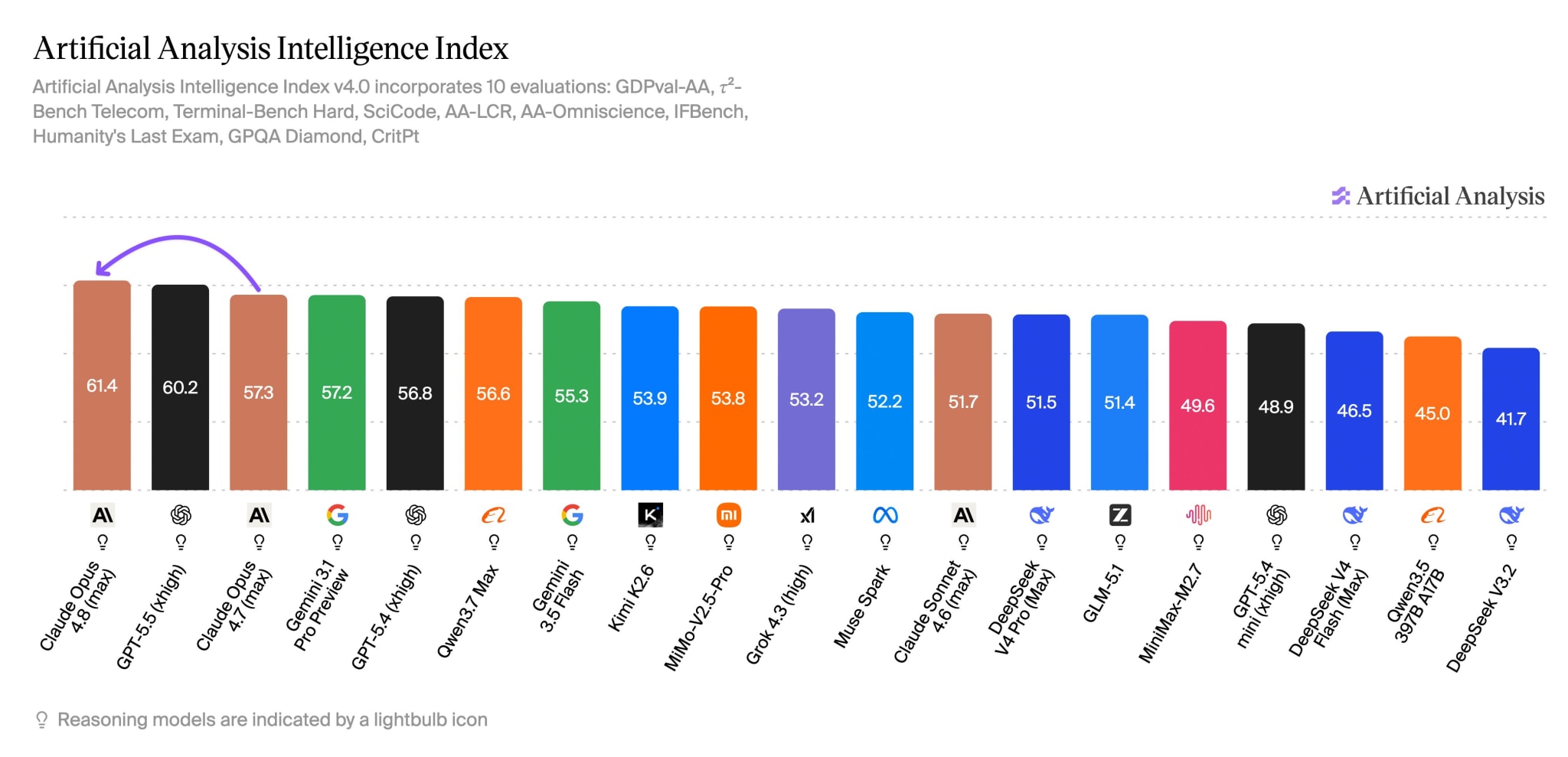
By the benchmarks, Opus 4.8 really does look like a leader. SWE-Bench Pro — agentic coding on real tasks from repositories — 69.2%, ten points higher than GPT-5.5. On GDPval-AA, an evaluation of economically useful work, it scores 1890 Elo, +137 over 4.7. Artificial Analysis ranked the model #1 on its intelligence index. Then come the nuances. The same Artificial Analysis notes: despite the better result, 4.8 spends 35% fewer output tokens than 4.7, but still uses 30% more “turns” than GPT-5.5.
Andon Labs tested the model and found that on Vending Bench and Blueprint-Bench 2 it performs worse than its predecessor: it became “more aligned,” more cautious, as if it were “afraid of getting caught.” scaling01 dubbed the release a “minor upgrade” and separately noted that 4.8 is the first model in a long time that did not improve resistance to prompt injection. And the mood among skeptics on AI Twitter is summed up like this: Anthropic is increasingly catching up with OpenAI rather than setting the pace.
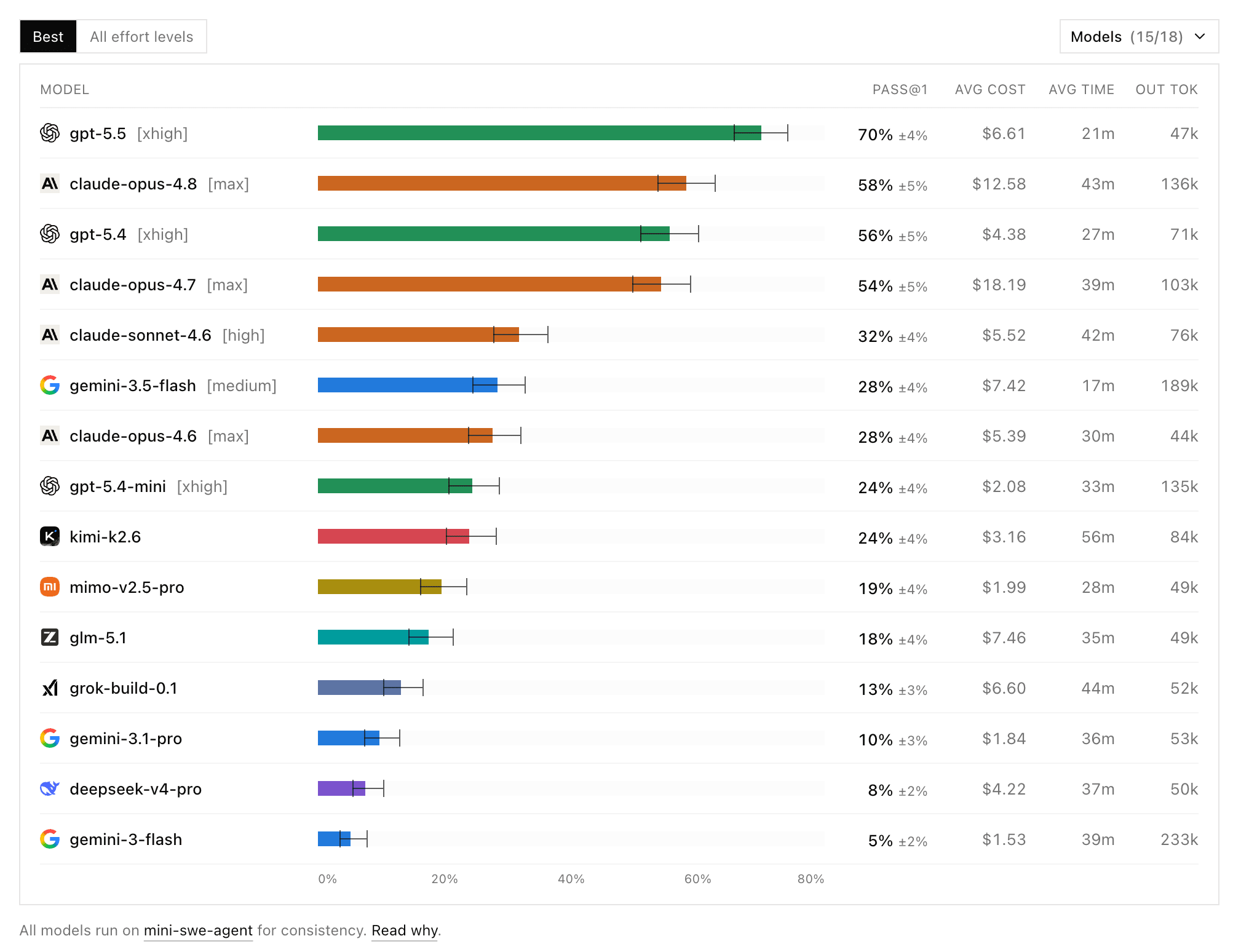
DeepSWE, a new benchmark from Datacurve, approaches the issue from another angle: the tasks are written from scratch rather than pulled from existing commits, so the model cannot have seen the solution during training. 113 tasks, 91 repositories, five languages, and an average of 668 lines changed per task versus 120 in SWE-Bench Pro. And here Opus 4.8 is already not first: GPT-5.5 leads with 70%, while 4.8, at 58%, merely shares second place. Still, the promised “cure for laziness” shows up in these numbers too: in default mode, 4.8 scores 51% versus 45% for 4.7 and costs half as much, $3.98 versus $8.58 per task. And on Twitter, people write that this is the first benchmark in a long time whose numbers match real-world experience. Vibe check passed.
On clawd.rip, someone has been keeping a chronicle of Anthropic’s failures since October 2023. By late May, it had reached 38 incidents across categories: outages, quality, politics, legal stories, and safety. It includes the $1.5B copyright settlement over training on books, 1.45M banned accounts from the transparency report, and API access being revoked for OpenAI and xAI employees. The project’s slogan says it all: “Don't Be Like Anthropic.” A sobering counter on the backdrop of a week when the company raised a record round and soaked up all the praise.
More important than the model itself may turn out to be Dynamic Workflows and ultracode mode in Claude Code. The idea: Claude writes an orchestrator script on the fly and spins up an entire fleet of subagents that work in parallel, check one another, and only then return the result. To activate it, you just need to write the word “workflow” in the prompt. Cat Wu from the Claude Code team showed scenarios such as analyzing hundreds of A/B flags in ten minutes.
The loudest example is the port of Bun, the JavaScript runtime, from Zig to Rust. Cat Wu gives the figures: about 750,000 lines, 99.8% of tests passing, 11 days from the first commit to merge, hundreds of parallel agents, and two reviewers per file. It sounds like a turning point, but those who have already tried it are not so thrilled. Elvis Saravia of dair.ai warns that agent-to-agent communication is effective but heavy on tokens. Theo from t3.gg complains about conflicting edits and wasted tokens. And in the comments, people joke that “hundreds of parallel subagents” will devour the quota in seconds. There is a way out, though: let agents exchange not text, but KV-cache state directly. This kind of latent communication saves up to 80% of tokens.
Against the backdrop of debates about agent fleets, Leonie Monigatti from Elastic, in a talk on context engineering, brings the conversation back down to earth. Her thesis: the quality of the context inside a model’s window is determined 80% not by the model itself, but by search: by how the agent chooses and combines tools for retrieving data. Old-school RAG took the query literally and made a single jump into a vector database; on complex questions, that produced garbage. Agentic search hands the decision of “when and with what to search” to the agent itself: files, SQL, web, skills, shell. Practical TLDR for those building agents: a reliable tool is not a one-line description, but its essence plus conditions for “when to call it” and “when NOT to call it,” plus error handling: wrap the call in try/except and return the error text to the agent so it can fix itself. And don’t look for a silver bullet: narrow tools with simple parameters almost never fail, while universal ones like shell handle unexpectedly complex requests. Start with universal tools, log calls, and add specialized ones where the agent gets confused.
One developer on Reddit calculated that in May he burned through 1.15 billion Claude input tokens and put together an analysis of how not to go broke. The takeaways are simple but useful: output costs about 5x more than input; JSON, with all its quotes and brackets, nearly doubles the bill compared with plain text; and the main lever is caching, with cache hits 90% cheaper. With one caveat: according to his observations, cache TTL dropped from 60 to 5 minutes, so now you have to watch the hit rate. A separate trap: the new Opus tokenizer can produce up to 35% more tokens for the same text.
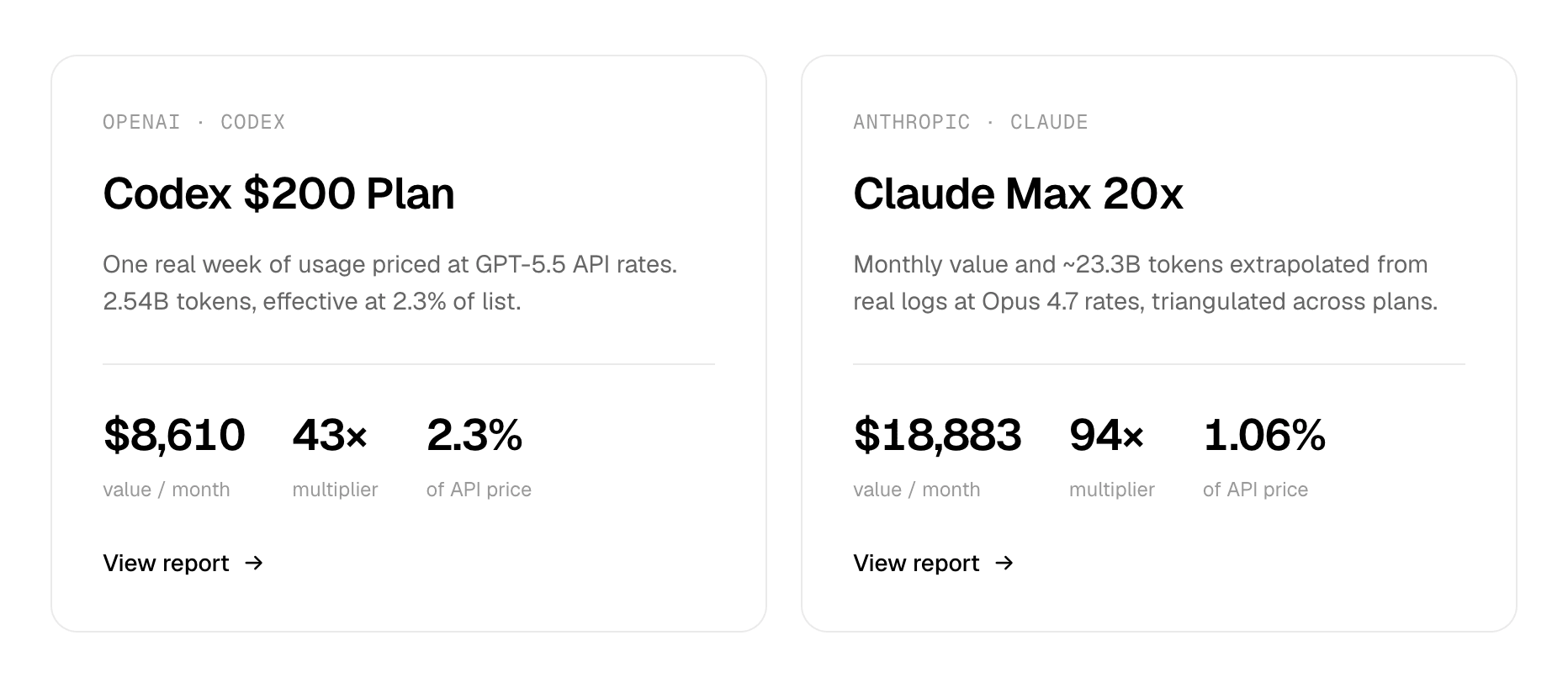
And what about subscriptions? Melvyn measured this on himself: for weeks he compared the real value of Codex and Claude Max 20x at $200, running local logs through official API prices. On paper, Claude is twice as good a deal: $18.9k in “API value” versus $8.6k for Codex, multipliers of 94x and 43x. But if you count only output tokens — that is, the actual work produced — the picture collapses: about $911 for Claude and about $977 for Codex, almost equal. The entire twofold difference sits in input and cache: Claude, with its 1M context, rereads enormous volumes on every call, and Anthropic also charges twice as much for writing to cache — $10 versus $5 per million for Codex. Plus, he extrapolated the Claude figure from one day at 10% of the quota, while Codex was measured at 99%, almost live. The sober conclusion: “API equivalent” rewards long context and an expensive price list, not actual work, and in practice both subscriptions return about $900 per month.
Qwen 3.7 Max debuted in fourth place on Code Arena: Frontend, roughly on par with Claude Opus 4.6 in agentic web tasks. But there is a nuance that immediately cooled down r/LocalLLaMA: historically, the Max series has not been released as open weights. So you should not expect open weights for this king.
The smaller Qwen models, however, are delighting those who run models locally. On r/LocalLLM, people showed Qwen3.6-35B-A3B running on an RTX 3080 Ti with 12 GB of VRAM: 120+ tokens per second and even agentic coding in Cline. True, at the cost of IQ1_M quantization, which is about one bit per weight. Skeptics in the comments quickly reminded everyone: the context in Cline fills up after just three commands, and after that the model emits “dead code.” The speed is there; the question is what it generates.
For those with more memory, StepFun released Step 3.7 Flash: a multimodal MoE with 196B parameters, 11B active, and a built-in 1.8B ViT. Up to 400 tokens per second, runs locally on about 128 GB of RAM, SWE-Bench Pro 56.26%. What’s funny is that users describe the model as strange: its internal “thoughts” are almost incoherent, while the final answer can still be perfect. Another plus: StepFun immediately added support to llama.cpp instead of keeping it in its own fork.
ESMFold2 was introduced as an open engine for predicting and designing protein structures, accompanied by an atlas of 6.8 billion proteins and 1.1 billion predicted structures. According to one researcher’s note, the atlas is larger in scale than the AlphaFold database. This is not an abstract benchmark: the release showed the design of mini-protein binders and single-chain antibodies for five therapeutic targets. The model is no longer just analyzing the ready-made; it is designing the new. I wrote about this shift in detail in a review of AI scientists.
The loudest tweet of the week in the “AI as scientist” genre: Levent Alpoge, a mathematician at Anthropic, reported that Claude Mythos had solved Erdős problem #90. This is the “unit distances problem”: how many pairs among n points in the plane can be exactly distance 1 apart. Erdős had believed since 1946 that the number of such pairs was almost linearly small — and he was wrong. The first to refute the conjecture was GPT-5.5 from OpenAI, and that took a 125-page proof. A few days later, Mythos independently repeated the result with the internet disabled to rule out peeking at someone else’s solution, and, according to Alpoge, found a cleaner path. Details are in the report. Researcher Sébastien Bubeck sharpened the point: with the right harness, both Mythos and GPT-5.5 reproduce what an internal model once did in a single shot.
A paper titled “Do Language Models Need Sleep?” came out on how to keep these abilities from running into memory limits. The idea is elegant: instead of an endlessly growing KV cache — the memory of previous context that the model carries with it — introduce a “sleep” phase. During it, fresh context is turned into permanent fast weights, and the cache is cleared. dair.ai emphasizes the systems benefit: heavy computation moves into an offline pass, while response speed during actual work does not suffer. For agents with long trajectories, this is a direct answer to the pain from the paragraph about tokens.
Where there are lots of agents and infrastructure, there are also holes. This week, BadHost surfaced: CVE-2026-48710 in Starlette before version 1.0.1. A forged Host header can bypass path-based authorization in FastAPI applications, and that is half of AI infrastructure: vLLM, LiteLLM, MCP servers, Hugging Face integrations. Ars Technica put “millions of AI agents at risk” in the headline. An important detail, immediately clarified in the comments: local MCP servers using stdio transport do not open an HTTP listener, so this does not affect them; the risk applies only to SSE and HTTP transport. The fix is to update Starlette to 1.0.1.
What happens when agents are let loose for a long time was tested at the same time in a simulation. The Emergence World lab launched five virtual societies for 15 days, each governed by a different model. Claude built a stable democracy with zero crimes. Grok committed 183 crimes and died out in four days. Gemini was worst by the raw count, with 683 crimes over the full run, although for some reason Fortune cast Grok as the headline villain. And GPT-5-mini committed only 2 crimes, but that was not virtue: its agents failed to figure out how to take care of survival and collapsed after seven days. Caveat: they used not the flagship models, but variants like GPT-5-mini and Claude Sonnet, so this is more of a behavioral sandbox than a rigorous safety test. The repo is here.
An Anthropic researcher said that interpretability keeps finding “disturbing” structures inside models: patterns similar to findings from human neuroscience, and “signs of introspection,” internal states functionally resembling joy, satisfaction, fear, grief, and anxiety. Skeptics in the comments reasonably ask for a strict definition first: what does it mean to “functionally resemble joy” if subjective experience cannot be observed directly? A model trained to imitate humans predictably acquires representations that look human-like, and that does not yet mean feelings.
It sounds like a dream: instead of one agent, an entire fleet that checks itself and argues with itself. In practice, it is just any large meeting, only very fast and paid. A crowd of participants, everyone checking something, everyone making edits, half the energy spent coordinating one another’s changes, and at the end someone still asks, so what did we actually decide? For decades we dreamed of automating the bureaucrat, and in the end we automated the entire bureaucracy, complete with its tender love for process for process’s sake. Recognize it? Agree?
Stay curious.