Галлюцинации недели: Claude Capybara, GigaChat-3.1, кража ключей через LiteLLM и CLI для всего на свете

Anthropic утекает в обе стороны: Capybara наружу, а пользователи Claude Code в сторону конкурентов. Stripe тем временем делает CLI, Intel делает дешёвые GPU, а Sora делает вид, что её не было.
У Anthropic неделя вышла контрастной. Fortune сообщил об утечке нового тира Capybara, который якобы стоит выше Opus 4.6 в иерархии моделей. По слитым данным, Capybara показывает лучшие результаты в кодинге, академическом reasoning и кибербезопасности. Официального подтверждения нет, но в тот же день кто-то нашёл страницу "Claude Mythos" на сайте, которую быстро удалили.
На фоне всех этих амбиций пользователи Claude Code устроили маленький бунт. С 23 марта люди на Max-планах начали сжигать 80-100% лимитов за минуты вместо привычных 20-30%. Один человек написал, что слово "hey" обошлось ему в 22% usage. Я сам на Max-плане и заметил скачок расхода, а в субботу закончилась акция с двойными лимитами в нерабочее время. Anthropic два дня молчал, потом 26 марта признал: "мы корректируем наши 5-часовые лимиты для бесплатных/Pro/Max подписок в часы пик". Мда, остается только плакать.
Figma открыл бету своего MCP-сервера, и это первый убедительный пример tool-calling как продуктовой фичи, а не обёртки над чатом. Агенты теперь могут редактировать дизайн прямо на канвасе. Cursor подключился моментально: генерация компонентов по дизайн-системе команды, прямо из IDE в Figma. GitHub показал, что это работает и через Copilot CLI. Выглядит как будущее, где дизайнер и разработчик общаются не через Jira-тикеты, а через агента с доступом к обоим инструментам.
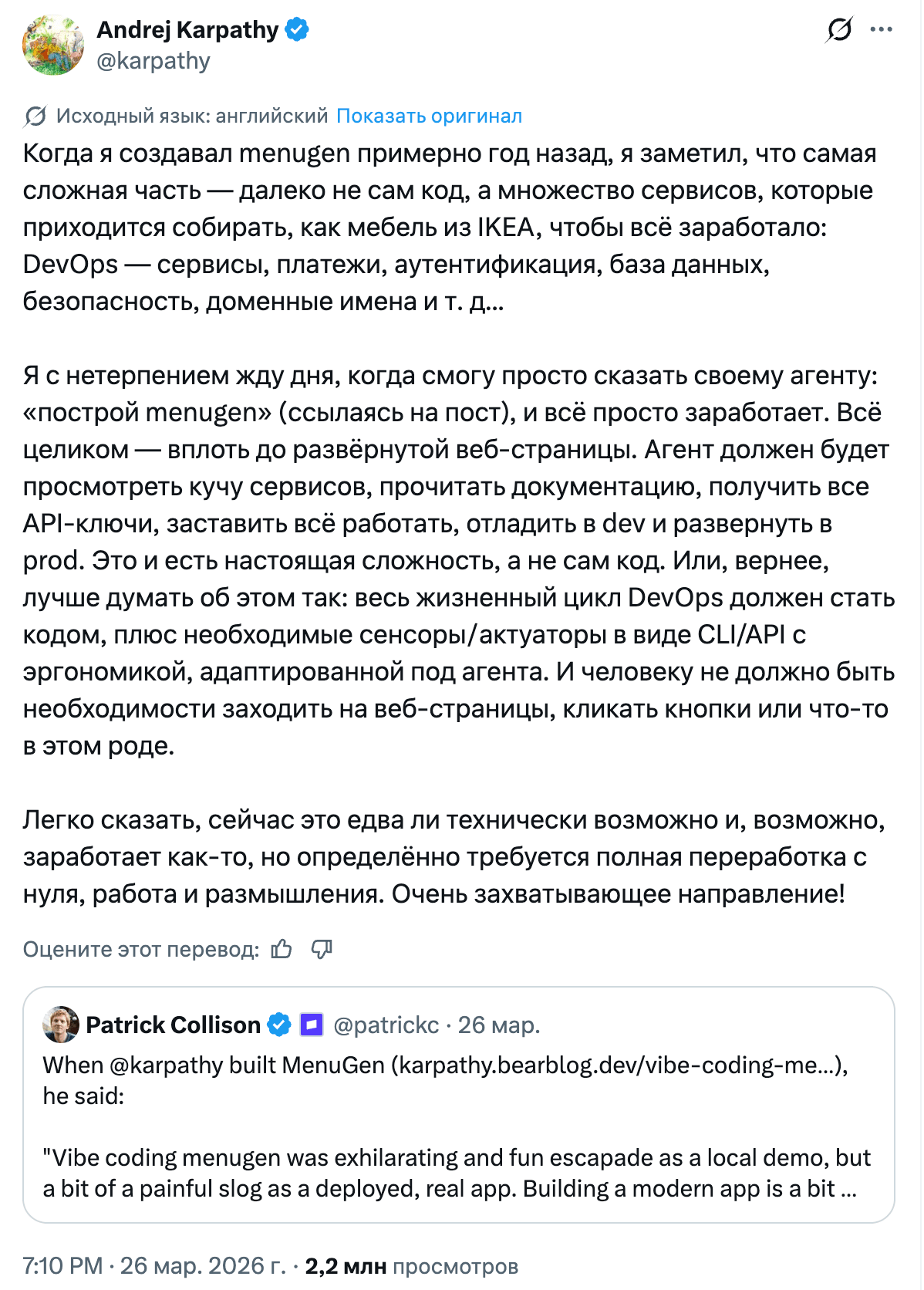
Но самый неожиданный тренд недели, пожалуй, CLI. Stripe запустил Projects.dev: пишешь stripe projects add posthog/analytics, и тебе автоматически создаётся аккаунт PostHog, генерируется API-ключ, настраивается биллинг. Patrick Collison сослался на Андрея Карпаты как на вдохновение: агентам слишком сложно провизионировать бэкенд-сервисы. И в тот же день вышли CLI от Ramp, Sendblue (iMessage), ElevenLabs, а чуть раньше, Visa, Resend и Google Workspace. CLI возвращается, и на этот раз не для людей, а для агентов. Ирония в том, что MCP, который должен был стать универсальным протоколом для подключения инструментов, проигрывает обычному stdin/stdout в простоте и надёжности. А ещё и жрёт контекст.
Для тех, кто уже запускает несколько агентов параллельно, Cline выпустил Kanban, бесплатный open-source инструмент для оркестрации coding-агентов. Каждый агент работает в изолированном git worktree, задачи выстраиваются в зависимости, диффы ревьюятся с одной доски. Поддерживает Claude Code, Codex и Cline. Разработчики, которые попробовали, говорят, что это решает две главных боли мульти-агентных workflow: ожидание инференса и конфликты при мёрже.
LiteLLM версий 1.82.7 и 1.82.8 на PyPI оказались скомпрометированы. Вредоносный код спрятан в .pth-файле, который Python выполняет автоматически при запуске интерпретатора. Никакого import litellm не нужно. Пейлоад собирает SSH-ключи, AWS/GCP/Azure-креды, кубернетис-конфиги, крипто-кошельки и shell-историю, шифрует всё AES-256 + RSA-4096 и отправляет на models.litellm.cloud (не путать с настоящим litellm.ai). И никакой социальной инженерии не понадобилось. Бонусом, если на машине есть Kubernetes service account, малварь пытается создать привилегированный под на каждой ноде кластера.
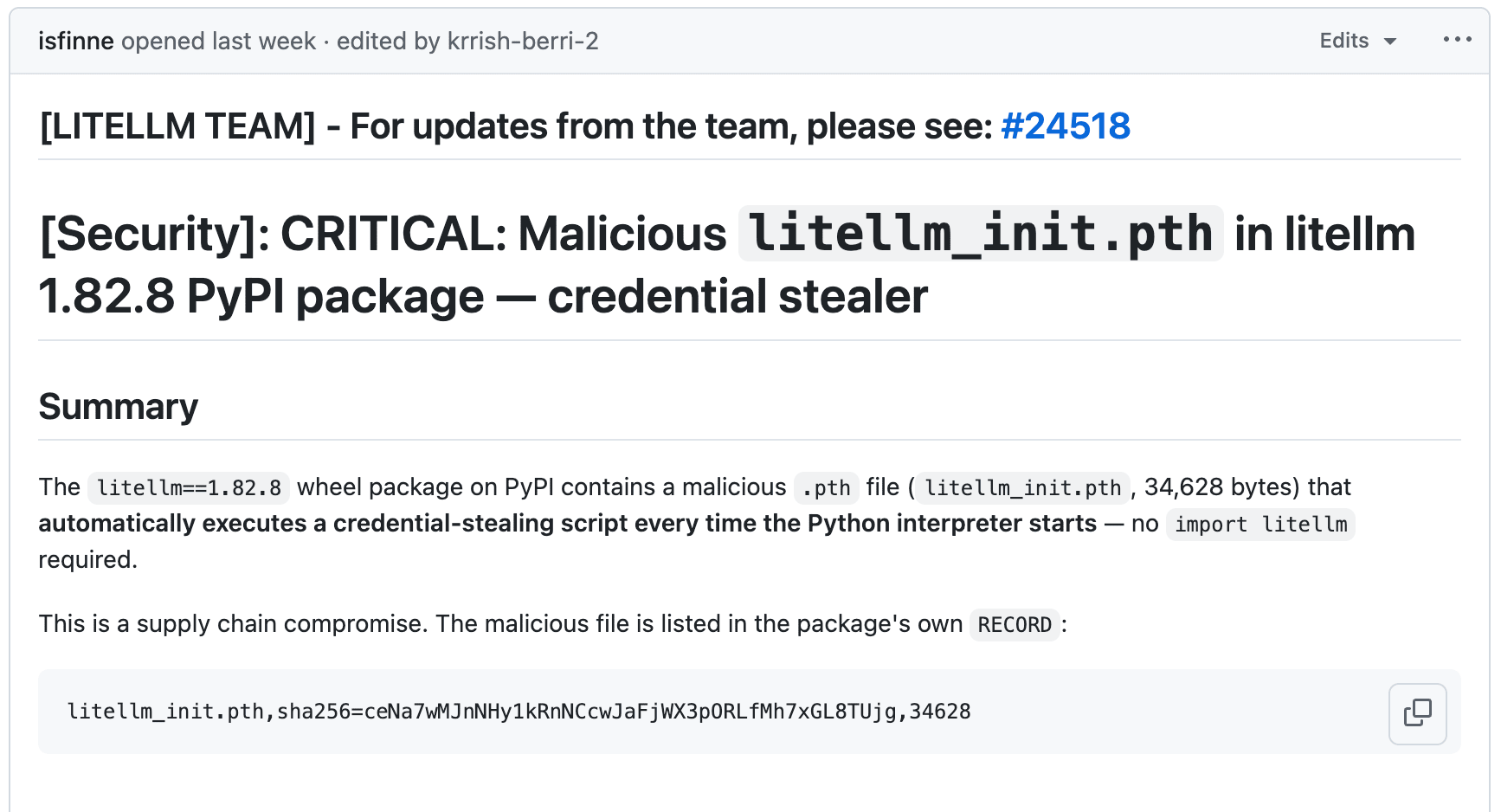
Андрей Карпаты дал самый подробный разбор: в агентном мире вся файловая система становится частью attack surface. FutureSearch обнаружил атаку, когда LiteLLM затянулся как транзитивная зависимость через MCP-плагин в Cursor. Баг в самом вредоносном коде (fork bomb из-за рекурсивного срабатывания .pth) уронил машину и тем самым привлёк внимание. Версии отозваны, PyPI-карантин снят, но все, кто обновился 24 марта, должны ротировать креды.
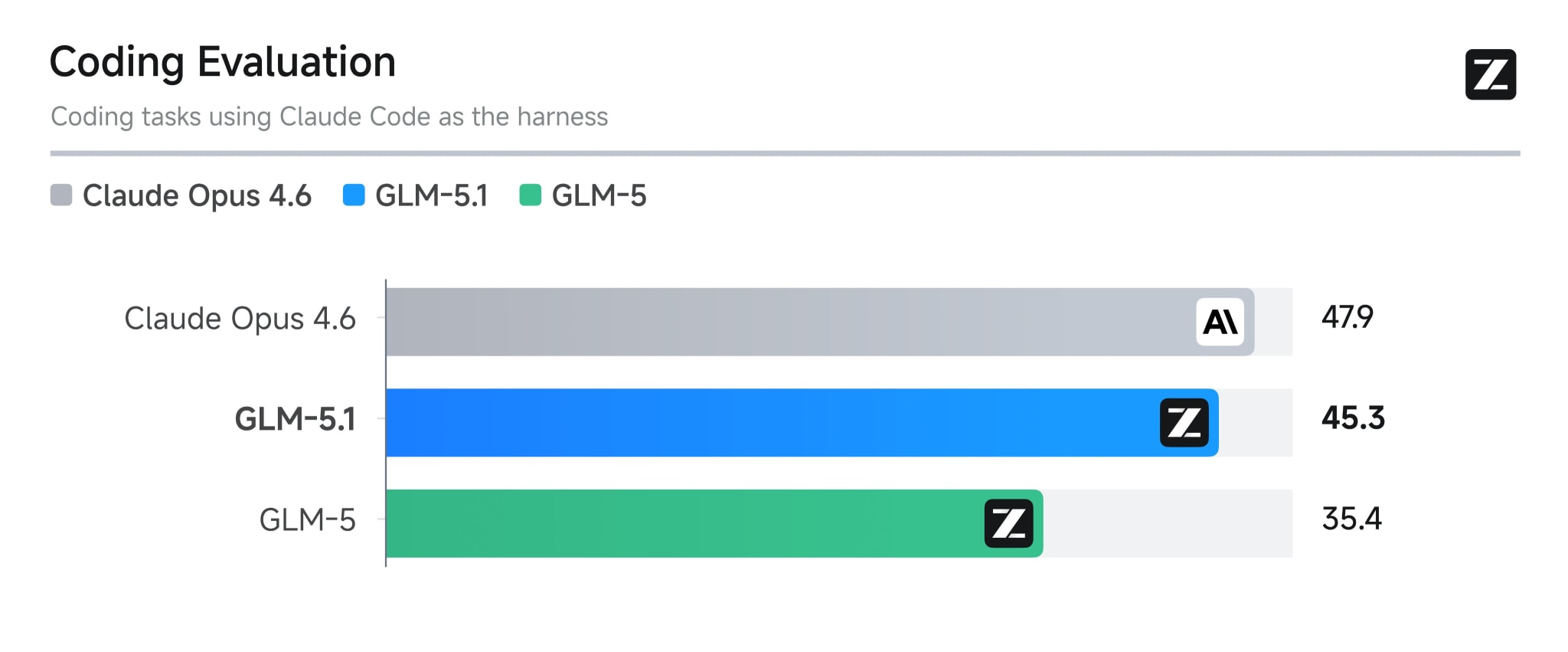
Zhipu выпустил GLM-5.1, очередного убийцу Opus, для всех пользователей GLM Coding Plan. На coding eval набирает 45.3 (Opus 4.6, для сравнения, 47.9). Разрыв между открытыми и закрытыми coding-моделями сокращается буквально каждую неделю, и GLM-5.1 очередное тому подтверждение. Может кто-то пользуется кодинг планами от китайских провайдеров, отпишитесь, как вам?
AI Sage выложил GigaChat-3.1 на HuggingFace: Ultra на 702B (MoE) и Lightning на 10B с 1.8B активных параметров. Оптимизированы для русского и английского. Lightning интересен для локального инференса, если верить бенчмаркам, на BFCLv3 набирает 0.76. В комментариях на HuggingFace пока осторожничают: геополитический контекст и вопросы о тренировочных данных никуда не делись. А ещё, меня смутило, что GigaChat-3.1 в бенчмарках сравнивают с прошлогодними моделями (Qwen3, gemma-3, DeepSeek V3).
Google выкатил Gemini 3.1 Flash Live, модель для голосовых и визуальных агентов в реальном времени. 70 языков, 128k контекст, SynthID watermarking. На Big Bench Audio 95.9% при высоком уровне reasoning (time-to-first-audio 2.98с) и 70.5% при минимальном (0.96с). Доступна в Gemini Live, Search Live и AI Studio.
Речевой стек вообще густеет с каждой неделей: в тот же период Mistral выпустил Voxtral TTS (3B параметров, 9 языков, ~90мс first audio, обходит ElevenLabs Flash v2.5 в preference-тестах), а Cohere выложил Cohere Transcribe под Apache 2.0 с лучшим WER на английском (5.42) среди открытых моделей.
OpenAI тем временем закрывает Sora. Официальный аккаунт поблагодарил пользователей и пообещал "подробности по таймлайну". На Reddit пишут, что продукт был финансово несостоятельным, а креаторы давно ушли на Runway и Kling. Ресурсы перенаправляются на кодинг и enterprise. Sora просуществовала меньше года. Disney вложил $1B и лицензировал 200+ персонажей, и это не помогло. Для open-source комьюнити вывод простой: локальные решения не закрываются по решению совета директоров.
Google Research представил TurboQuant на ICLR 2026: сжатие KV-cache в 6 раз без потери точности, ускорение инференса до 8x на H100. Работает через комбинацию PolarQuant (перевод в полярные координаты для устранения overhead нормализации) и QJL (1-битная коррекция ошибок через Johnson-Lindenstrauss). Уже есть форки для vLLM и llama.cpp, на MacBook Air M4 с 16GB запускают Qwen 3.5-9B с контекстом 20K токенов. Но методологию оспаривают: авторы RaBitQ обвиняют Google в нечестных бенчмарках, включая сравнение CPU vs GPU. Вот интересная статейка.
Intel выпустил Arc Pro B70: 32GB GDDR6, $949, 602 GB/s bandwidth, 290W. Для контекста, NVIDIA RTX 4000 PRO стоит дороже и даёт только 24GB. Intel заранее договорился с vLLM о поддержке с первого дня. Четыре карты за $4000 дают 128GB GPU-памяти, этого хватит для локального инференса 70B-моделей. Конечно, есть нюансы: int8 TOPS у B70 (367) сильно уступает RTX 4000 PRO (1290), CUDA нет, драйверная поддержка Intel исторически вызывает вопросы. Но по цене за гигабайт VRAM это сейчас одно из лучших предложений, если хочется запускать большие модели локально. Я бы присмотрелся, если в РФ их привезут.

ARC Prize запустил ARC-AGI-3, бенчмарк, на котором люди решают 100% задач, а фронтир-модели не дотягивают до 1%. Интерактивные среды, scoring по эффективности относительно человека, призовой фонд $2M+. Создатель подчёркивает: бенчмарк измеряет zero-preparation generalization, а не способность построить специализированный harness. Критики указывают на жёсткость scoring-протокола и неочевидность сравнения с предыдущими версиями ARC, но даже скептики соглашаются: текущие LLM-агенты плохо справляются с интерактивными средами с минимальной обратной связью.
Интересный вопрос: если .pth-файл исполняется при каждом запуске Python-интерпретатора, а ваш агент запускает Python по 50 раз в час, сколько раз за день ваши креды улетят на чужой сервер? Правильный ответ: достаточно одного.
Оставайтесь любопытными.


