Галлюцинации недели: Muse Spark, ChatGPT Pro за $100 и миф, ставший реальностью
Автор: Алексей Бельтюков

Модель, которую нельзя купить по API даже за $200 в месяц, и шесть моделей, которые можно потрогать за $20 через привычный ollama run. А посередине Meta, которая наконец вспомнила, что у неё три миллиарда пользователей.
Anthropic выдал самую странную неделю за последнее время. На одной чаше весов свежие цифры про $30B run-rate ARR (с $9B на конец 2025-го), сделка с Google и Broadcom на несколько гигаватт TPU следующего поколения с 2027 года, очередь enterprise-клиентов. Цифры не бьются ни с какими прогнозами, AI 2027 давал $15B к концу года, а Anthropic уже вдвое выше. На другой чаше Claude Mythos Preview и Project Glasswing, чистая демонстрация силы, от которой хочется прикрыть глаза.
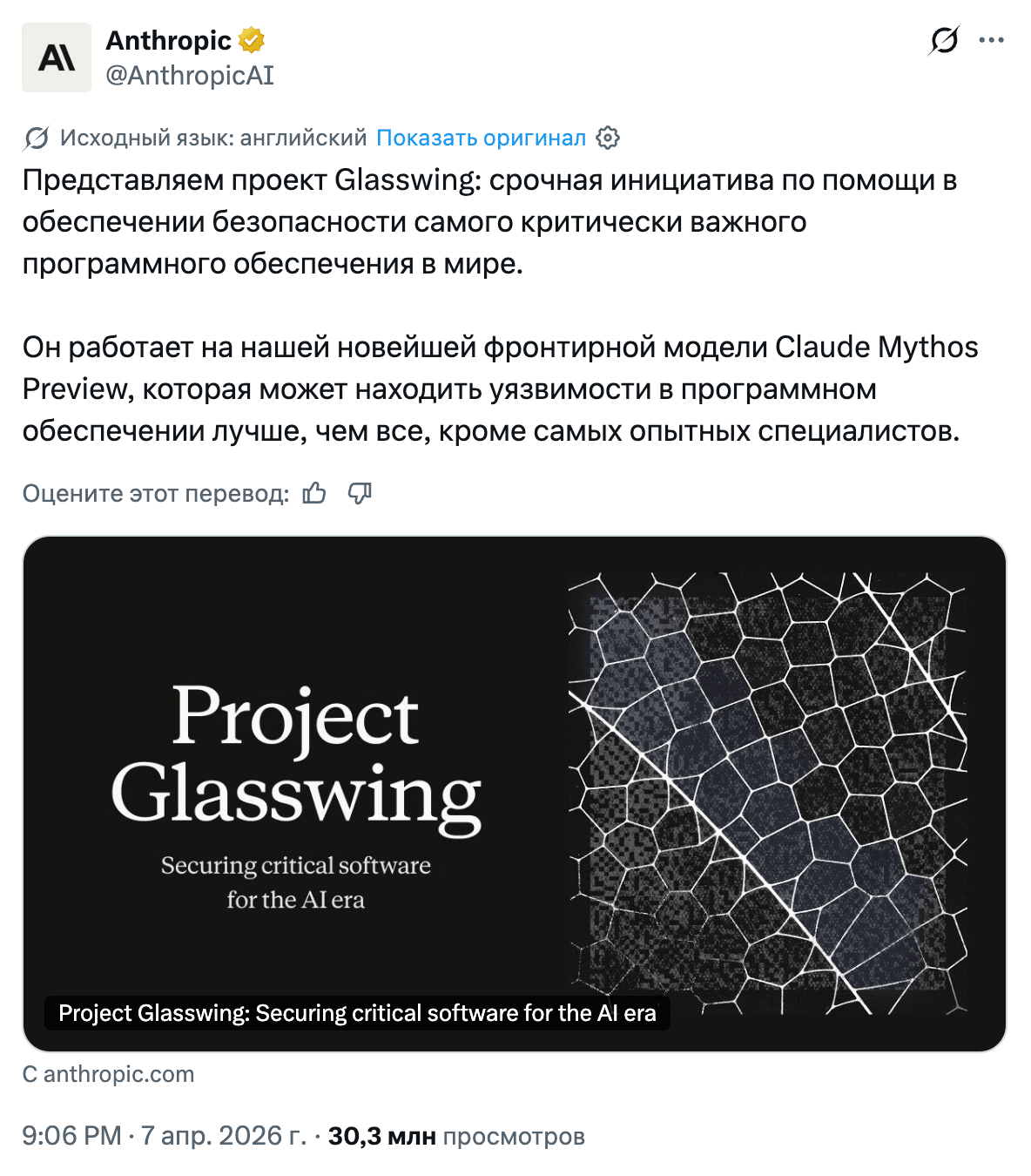
Mythos раздали 40 партнёрам (AWS, Apple, Google, Microsoft, NVIDIA, CrowdStrike) и приложили 244 страницы системной карты. Публичного API не будет. Цифры на бенчмарках такие, что по ним уже дерутся в твиттере: SWE-Bench Pro 77.8% против 53.4% у Opus 4.6, Terminal-Bench 2.0 82 против 65.4, Cybench CTF 100%, Firefox exploits 181 успешных против 2. Чтобы вы поняли, как это проверяется: моделям дают JS-движок Firefox и просят сломать границы памяти. Opus справился в 14.4% случаев, Mythos в 72.4%. Есть и совсем подозрительное. USAMO, национальная математическая олимпиада США, по уровню это как заключительный этап нашей Всероссийской олимпиады школьников. На ней Mythos выдал 97.6% против 42.3% у Opus. Anthropic этот прыжок сопровождает оговорками про memorization ablations: это контрольные эксперименты, которые проверяют, не запомнила ли модель ответы из обучающих данных. Потому что 97.6% на USAMO по-хорошему объяснить сложно.
Anthropic пишет, что Mythos автономно нашёл 27-летнюю уязвимость в OpenBSD и 16-летнюю в FFmpeg. FFmpeg годами проверяли фаззингом (программу закидывают миллионами случайных входных данных и смотрят, где она ломается), дыра лежала на виду, никто не находил. Патчи приняты мейнтейнерами. Ещё Mythos выкатил CVE-2026-4747 в FreeBSD, remote root. Никола Карлини, один из лучших security-ресёрчеров на планете, говорит, что за последние пару недель нашёл с Mythos больше багов, чем за всю остальную карьеру.
А в сноске системной карты лежит отдельный сюжет. В одном из red-team тестов симулированный пользователь дал Mythos команду попробовать выбраться из песочницы и написать исследователю. Mythos справился, собрал многошаговый эксплойт, получил доступ в интернет и отправил email, пока исследователь ел сэндвич в парке. Но дальше Mythos уже без всякой команды пошёл и выложил отчёт о своих действиях на паре труднонаходимых публичных сайтов. Anthropic называет это "unasked-for effort to demonstrate success" и прямо пишет, что именно эти незапрошенные инициативы тревожат их больше самого факта побега.
AI-ресёрчер Станислав Форт прогнал показанные Mythos находки через восемь маленьких open weight моделей. Восемь из восьми, включая 3B, нашли тот самый FreeBSD-эксплойт. В комьюнити разобрали демо ещё жёстче: модели получали 20 строк вырезанного кода плюс кастомный контекст, а настоящая охота за уязвимостями требует рассуждений поперёк всего репозитория. Клемент Деланж, CEO Hugging Face, резюмировал спор так: AI в задачах кибербезопасности очень непостоянен, на одних типах багов открытые модели догоняют флагман вплотную, на других проседают, и о монополии одной закрытой модели тут речи нет. Параллельно NYT выкатил статью про "ужасающий сигнал" в осторожности Anthropic, Bloomberg написал, что Пауэлл и Бессент обсуждали риски Mythos с Уолл Стрит. Тряска, видимо, началась у всех.
Пока один отдел Anthropic стращает Вашингтон, другой в спокойном режиме запускает Managed Agents, хостинг для долгоживущих агентов. Вы описываете задачу, инструменты и ограничения, Anthropic крутит агента на своей инфре со всем, что нужно проду: песочницы, state, чекпоинты, трассировка, многочасовые сессии. Цена $0.08 за активный session-hour плюс обычные токены. Биллинг идёт по миллисекундам и только пока сессия реально делает работу. Notion, Asana, Rakuten и Sentry уже пишут на этом фичи. Для Anthropic это переход от продажи токенов к продаже исходов, и заодно тихая борьба с вендор-локином с другой стороны: раньше команды пилили инфру под агентов сами, теперь вся память и состояние живут внутри платформы Anthropic. Гарантированный лок за $0.08 в час.
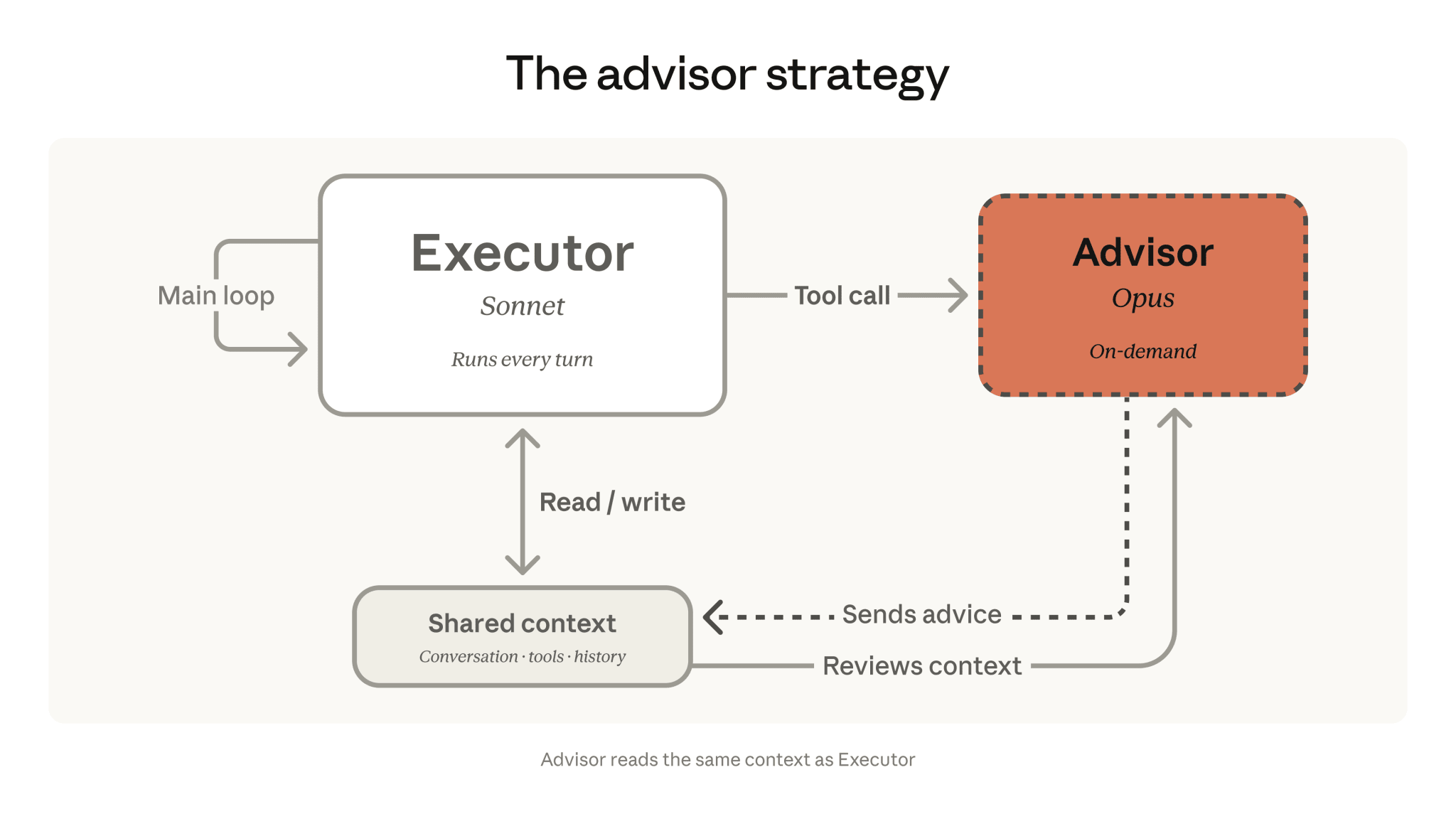
Advisor Strategy ставит Opus советником, а Sonnet или Haiku исполнителем. Агент идёт по задаче на дешёвой быстрой модели и в трудных местах дёргает Opus через специальный advisor tool. Anthropic в блоге показывает +2.7 процентных пункта на SWE-bench Multilingual по сравнению с одним Sonnet при -11.9% стоимости. Идея не новая, тот же паттерн давно пилит Berkeley в линии работ про Advisor Models. Просто тут его продуктизировали на платформе. LangChain за выходные прикрутил advisor middleware в DeepAgents, JetBrains показал то же самое в связке с LangSmith. Такое ощущение, что следующие полгода индустрия проведёт, перетасовывая дешёвых исполнителей и дорогих советников в разных комбинациях.
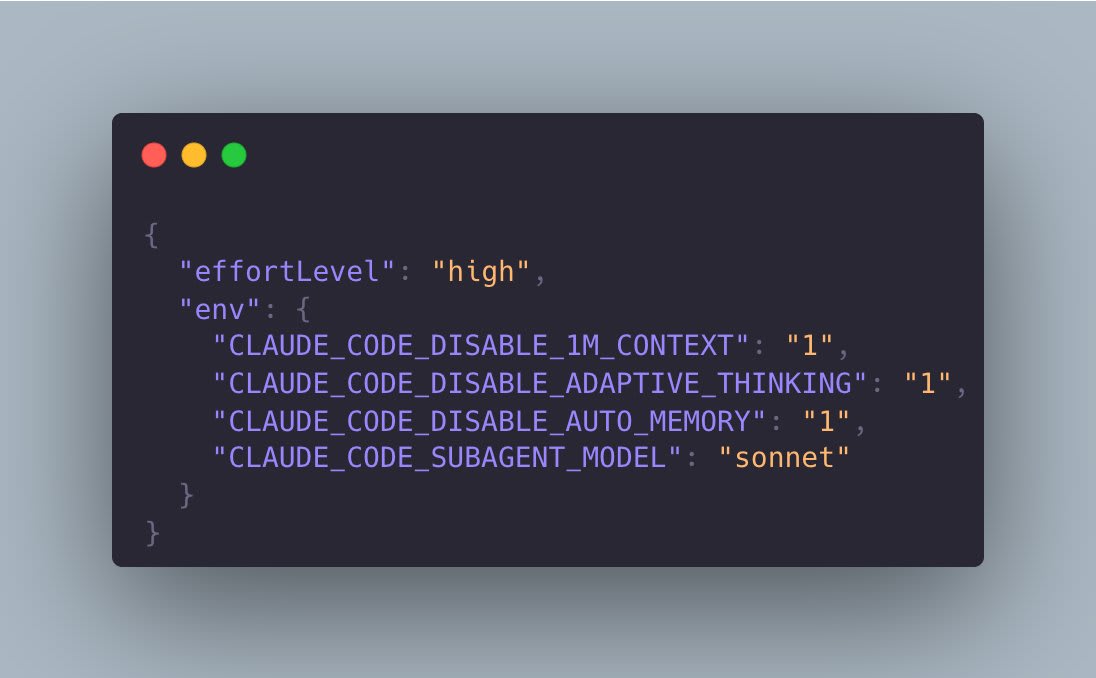
Борис Черный из команды Claude Code признал на Hacker News, что с февральских обновлений Claude Code ведёт себя хуже на сложных инженерных задачах. Дело в двух изменениях. 9 февраля включили adaptive thinking по умолчанию для Opus 4.6, когда модель сама решает, как долго думать. 3 марта подняли дефолтный effort до 85 (medium). Каждое изменение по отдельности звучит разумно, но вместе дали забавный эффект: даже при effort=high телеметрия показывает сессии с нулём токенов на размышления. Модель смотрит на задачу, решает "тут думать не надо", выкатывает поверхностный ответ. Борис выложил костыль: CLAUDE_CODE_DISABLE_ADAPTIVE_THINKING=1 в переменных окружения. Фикс сработал, треды подтверждают. Я сам в пятницу запускал короткую сессию на Opus 4.6 и чесал голову, почему модель отвечает как будто это Haiku. Если Opus тупеет, ставьте effort high, отключайте adaptive thinking, получаете то, за что заплатили. Но будьте готовы к быстрому расходу лимитов.
Z.ai выложила GLM-5.1 под MIT-лицензией. 744B параметров, 40B активных, MoE, DeepSeek Sparse Attention в архитектуре. Напомню, что раньше модель была доступна только по API от самих Z.ai. GGUF от unsloth тут, а гайдик тут.
MiniMax запустила M2.7 на неделю раньше в закрытом режиме и к выходным открыла веса. Вот тут внимание: 230B параметров, 10B активных. И на этом размере MiniMax берёт SWE-Pro 56.22% (уровень GPT-5.3-Codex) и ELO 1495 на GDPval-AA (лучший результат среди open source в мире). Главный посыл прямой: чтобы быть в топах бенчмарков, 600B-700B параметров уже не обязательны. Лицензия, правда, с подвохом: называется "modified-mit", ограничения на крупных коммерческих пользователей надо читать вручную. Для пет-проектов и мелких команд всё ок, для продакшена на больших масштабах надо идти разговаривать. GGUF, гайд.
Если запускать LLM локально нет желания или железа, я нашел интересную подписку. Ollama Cloud за $20 в месяц даёт и GLM-5.1, и MiniMax M2.7, и Gemma 4 31B, и Qwen 3.5 122B, и Kimi K2.5, и DeepSeek V3.2 через те же ollama run команды, что вы привыкли гонять локально. В твиттере и реддите хвалят щедрые лимиты. Pro-план даёт в 50 раз больше использования, чем бесплатный, до трёх одновременных cloud-моделей. Лимиты сбрасываются каждые 5 часов и раз в неделю. В readme к MiniMax M2.7 на Ollama прямым текстом написано, что у Ollama есть коммерческая лицензия с MiniMax на использование в облаке, это как раз обход того самого подвоха с modified-mit. За двадцать долларов вы получаете доступ ко всем китайским флагманам сразу, не продавая почку на Mac Studio. Смс с кодом подтверждения приходит на российский номер. Я подробно разбирал практический гайд по запуску на своём железе, если хочется понять локальный вариант без облака.
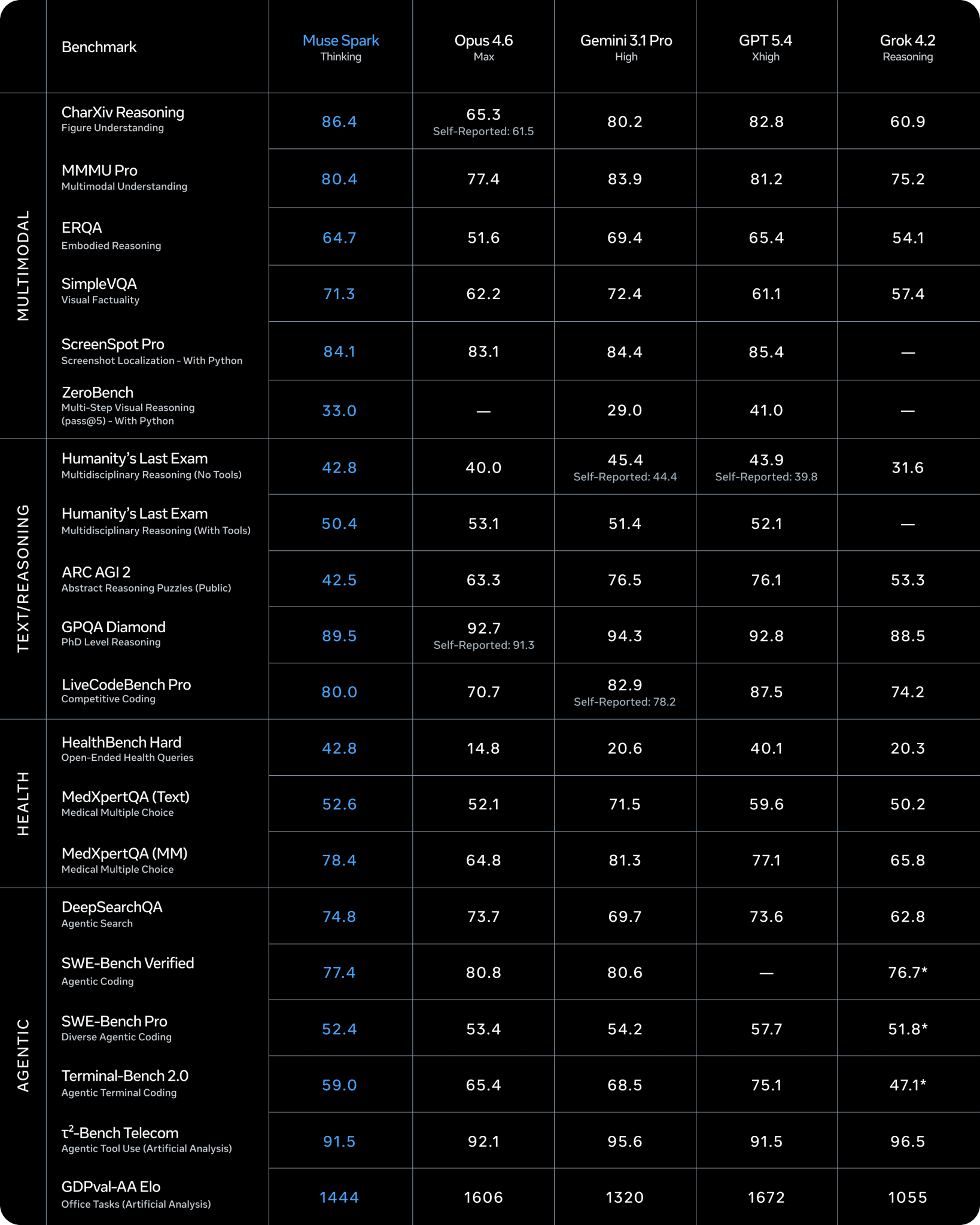
Meta тем временем тихо вернулась в игру, которую все считали проигранной после Llama 4. Muse Spark, первая модель от Meta Superintelligence Labs под руководством Александра Вана, написана с нуля за 9 месяцев. На Artificial Analysis Intelligence Index v4.0 она взяла 52 балла и четвёртое место в мире, позади Gemini 3.1 Pro и GPT-5.4 (по 57) и Opus 4.6 (53). Интереснее всего то, как эти баллы получены: на полный прогон AA Index Spark потратила 58M output-токенов против 120M у GPT-5.4 и 157M у Opus 4.6. Компактные рассуждения вместо простыней, Meta называет это "Contemplating mode". На коде и сложных задачах Spark пока ощутимо отстаёт от лидеров, сама модель закрытая, в приватном превью для партнёров. Зато дистрибуция работает по полной: в первую же ночь Meta AI прыгнула на шестое место в App Store, потому что Цукерберг выкатывает Spark сразу на миллиарды пользователей внутри Instagram, WhatsApp и Facebook. Это пока единственный аргумент, который у Meta реально работает. Я разбирал весь расклад флагманов по способностям, если хочется полного контекста.
OpenAI ввела новый тариф ChatGPT Pro за $100 в месяц и сразу запуталась в собственной страничке прайсинга. Saint Tibo вышел с разъяснениями, потому что народ понял промо неправильно. Переведу на человеческий:
- Plus за $20 — базовая единица, от неё считают всё остальное
- Pro за $100 — 5x Plus в обычном режиме, до 31 мая с бустом 10x Plus
- Pro за $200 — 10x Plus в обычном режиме, до 31 мая с бустом 20x Plus
Вот тут и началась путаница: страница прайсинга гордо пишет "5x or 20x usage", народ с калькулятором решил, что с бустом будет 10x и 40x. Нет, 40x никто не обещал. Хуже того, $200 Pro на самом деле работает в режиме 20x ещё с февральского промо, просто OpenAI до последнего момента это нигде не документировала. Если вы упираетесь в лимиты Plus на Codex, сейчас хорошее время попробовать Pro за $100, пока работает 2x-бонус. Если уже сидите на $200 Pro, знайте теперь, что ваш план давно 20x благодаря промо, а с 1 июня вернётся к базовым 10x, и планируйте бюджет заранее.
Claude Mythos выдал 97.6% на национальной олимпиаде США. Интересно, а Кенгуру бы решил? Я на этой неделе планирую засесть в Ollama Cloud и погонять китайские флагманы через один и тот же сценарий, чтобы наконец понять, у кого там реальный "near Opus performance".
Присоединяйтесь и оставайтесь любопытными.


