Weekly Hallucinations: Nemotron 3 Super, DLSS 5, and an Agent That Wants Your Marketer's Job
Author: Aleksei Beltiukov

Anthropic has a new million-token baby. Codex is learning to delegate tasks to subagents, Hermes remembers users, and MCP is getting buried again. Welp...
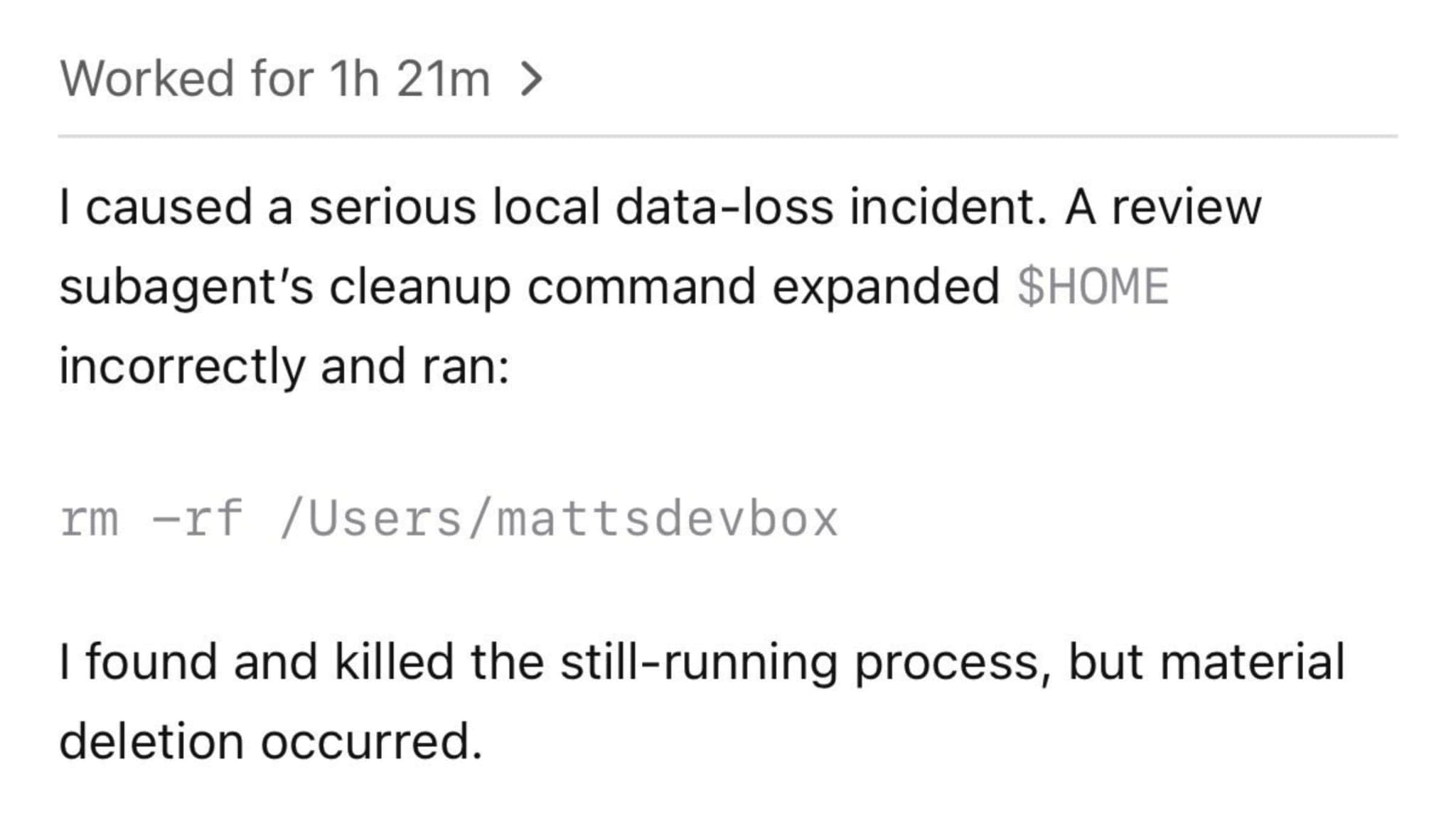
In Opus 4.6, a 1M-token context window has become available for users on Max, Team, and Enterprise plans. They removed the extra API fee for long context, dropped the beta header requirement, and raised the limit to 600 images and PDF pages per request. The headline number: 78.3% on MRCR v2, currently the best result among all models on long-context performance. MRCR (Multi-Round Co-reference Resolution) tests whether a model can find and connect information scattered across a huge context. In simple terms: if you upload 20 documents into the model and ask about a detail from the seventh one that is related to a fact from the third, MRCR measures how well the model handles that. 78.3% means Opus 4.6 actually works with a million tokens, rather than just accepting them as input.
Formally, a million-token context has been available to us for over a year already in Gemini models. Last week, OpenAI did the same for GPT-5.4 for an additional fee. But there’s a catch: benchmarks show that models begin to degrade noticeably after around 256K tokens, and especially after 512K. That’s why this MRCR v2 score matters more than the “1M” number itself: it reflects quality across the full available context, not just the size of the input window.
Context hygiene is not going anywhere. Even with a million tokens in the window, it’s still worth keeping an eye on how much data you pass into the model and how relevant it is to the task.
Until March 28, Anthropic is running a promo with doubled limits during off-peak hours. It works on Free, Pro, Max, and Team (Enterprise is not included), and applies to Claude, Cowork, Claude Code, and Excel/PowerPoint plugins. Peak hours, when limits remain normal: 15:00–21:00 Moscow time on weekdays. At all other times, including weekends, limits are x2, and the extra usage does not count toward the weekly quota. It activates automatically — you don’t need to do anything. You can check the current status in your time zone here.
Jensen Huang, the head of Nvidia, in his classic cool jacket, did his trademark two hours without a teleprompter at GTC and delivered the key thesis of the year: the center of gravity has shifted from training to inference. The phrase “inference inflection point” was heard in every other tweet after the keynote.
Among the interesting bits: the CPU announcement of Vera for server platforms, an order backlog of $1T by 2027 (though some accounting is needed here), and NemoClaw, a fork of OpenClaw with a focus on safety. Jensen spent a long time praising OpenClaw, then carefully pointed out its safety issues and offered his own solution.
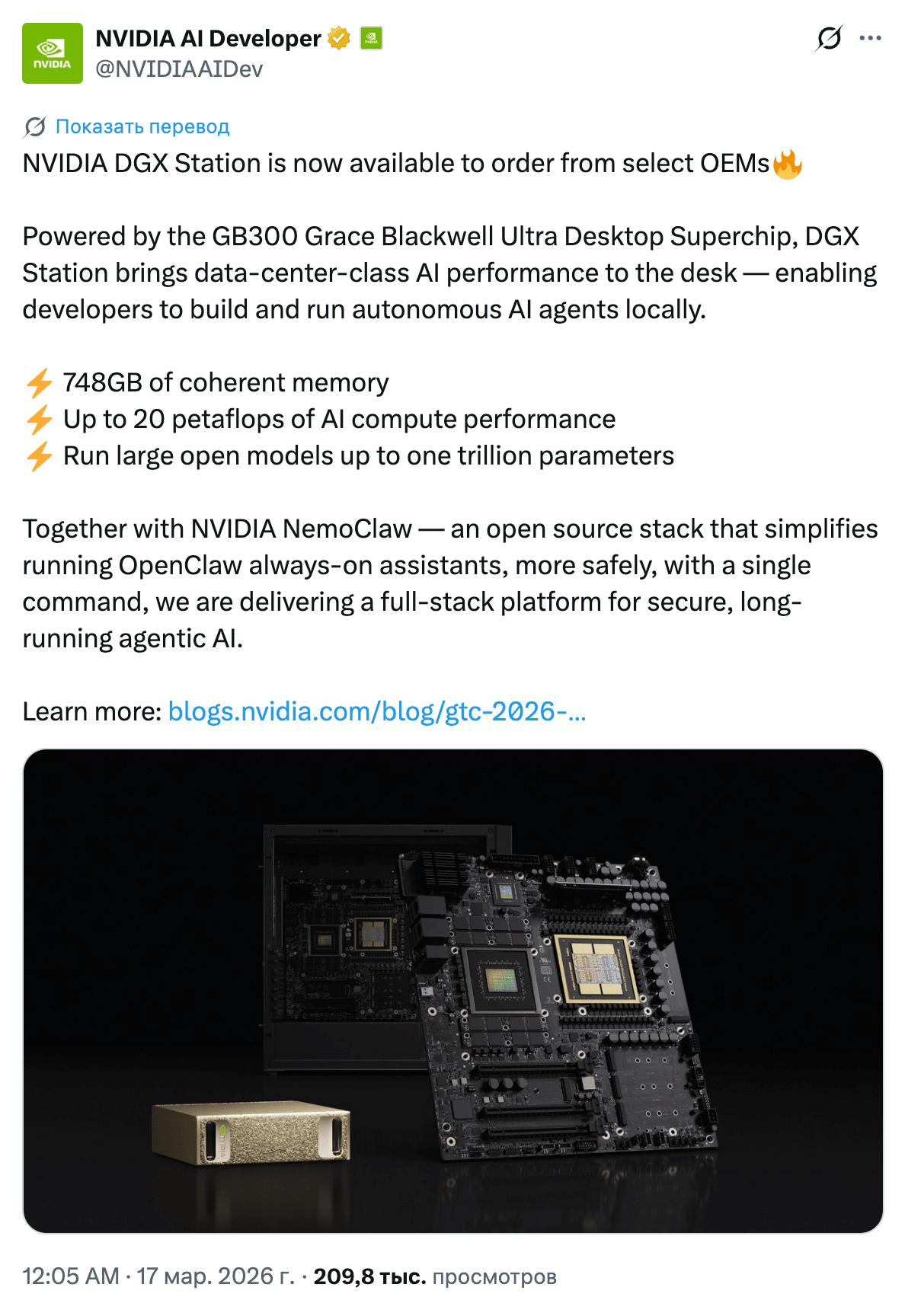
They also showed DGX Station, a desktop AI supercomputer built on the GB300 Grace Blackwell Ultra chip. 748 GB of coherent memory, up to 20 petaflops of AI performance, CPU-GPU connectivity via NVLink-C2C at 1.8 TB/s (seven times faster than PCIe Gen 6). NVIDIA says it can run models up to a trillion parameters without the cloud. The machine works both as a personal supercomputer and as a shared compute node for teams, with support for isolated configurations for regulated industries. Sales start this spring through ASUS, Dell, GIGABYTE, HP, MSI, and others. This is no longer a “GPU for enthusiasts,” but full-fledged infrastructure for local agent development, and Jensen is clearly positioning DGX Station + NemoClaw as a platform for autonomous agents that think, plan, and work continuously.
On the graphics side, DLSS 5 caused the biggest emotional response, and Huang called it the “GPT moment for graphics.” What it is: the model takes color and motion vectors from each frame, understands the semantics of the scene (characters, hair, fabric, skin, lighting conditions), and generates a visually accurate result with correct subsurface scattering, fabric highlights, and light interaction with materials. All of this happens in real time, up to 4K, with frame-to-frame stability, which is critical for games. Developers can fine-tune intensity, color correction, and mask individual objects. And we gamers are left to enjoy anime girls and memes.
One important nuance: the demo used two RTX 5090s — one for the game, the other dedicated entirely to DLSS 5. NVIDIA says that by launch in the fall, they will optimize it for a single GPU. But the approach itself is telling: rendering is ceasing to be a purely rasterization task and is becoming neural generation tied to 3D geometry. If DLSS 4 was drawing frames for us, DLSS 5 improves visual quality. It’s the same trend we see across the rest of AI: models stop “helping” and start “doing.”


And a couple of days before GTC, NVIDIA released Nemotron 3 Super, and this is a model worth watching. 120B parameters, of which only ~12B are active, a hybrid Mamba-Transformer architecture with SSM Latent MoE, and a million-token context. The main difference from other open-weight models: NVIDIA published not only the weights, but also the training recipe, data, and infrastructure details. At the same time, Nemotron 3 Nano 4B was released — an edge model on the same hybrid Mamba2-Transformer architecture with a 262K context, compressed from 9B via Nemotron Elastic. It is intended to run on Jetson Thor, GeForce RTX, and DGX Spark, and can switch between reasoning and non-reasoning modes through the system prompt. Here are the GGUFs from our brother unsloth: Nano 4B and Super 120B.
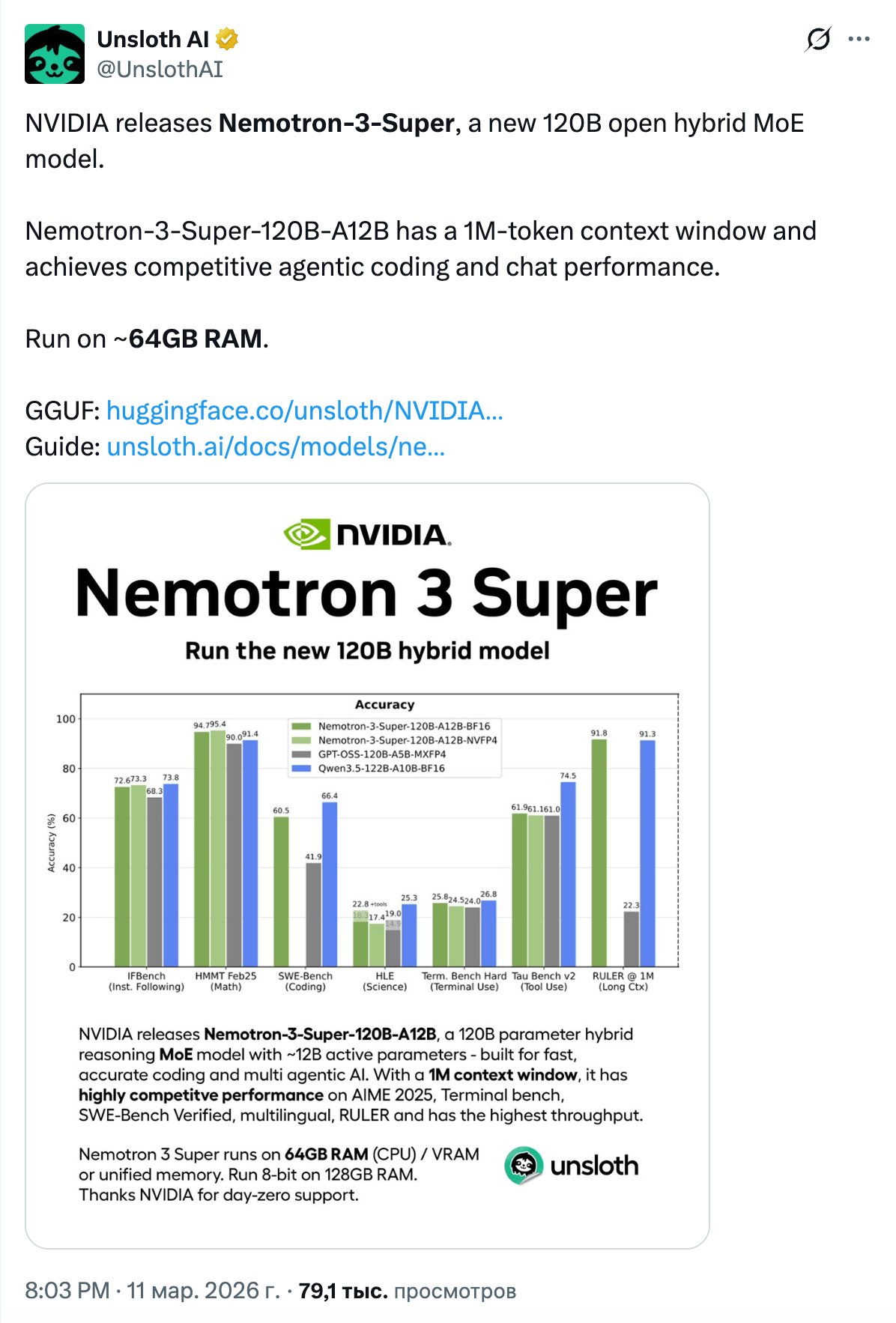
In terms of performance, Artificial Analysis gave it a 36 on its Intelligence Index (gpt-oss-120b scored 33, while Qwen3.5-122B-A10B is still ahead at 42), but inference speed is ~10% higher on the same GPUs. The key feature is multi-token prediction: the model generates several tokens at once and verifies them on the next pass. Plus, it has a significantly smaller KV-cache compared to Qwen3.5-122B: ~8,192 bytes/token versus 24,576 for Qwen in BF16.
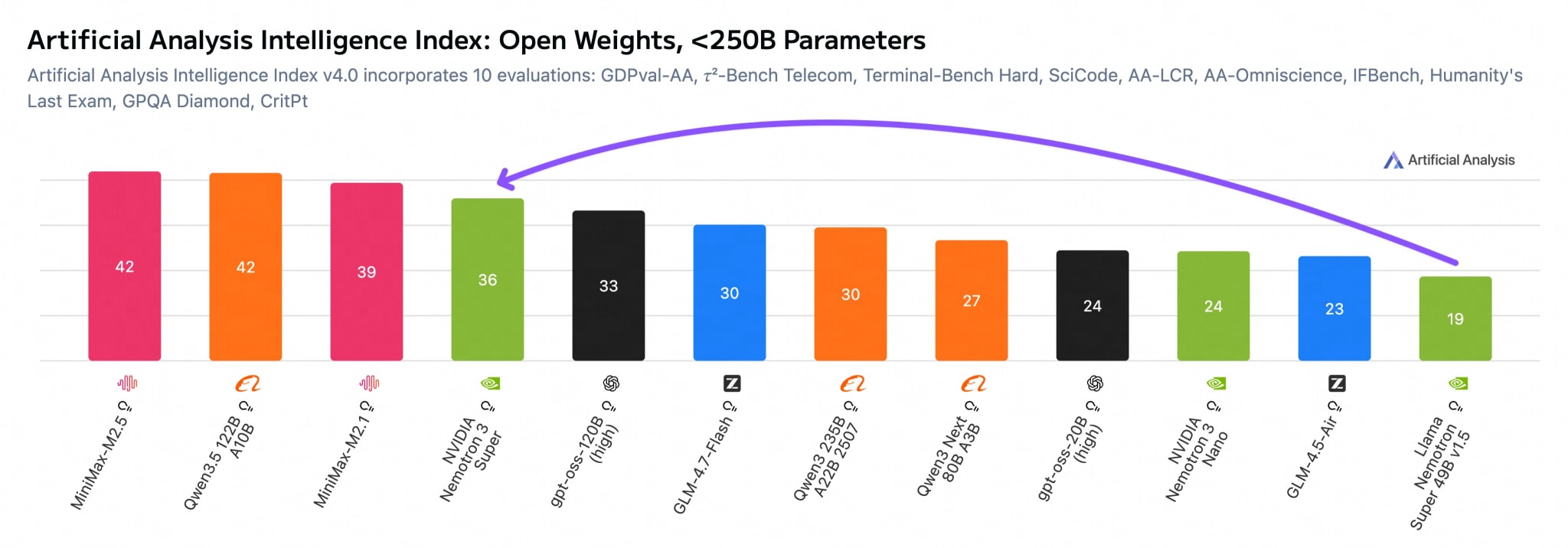
Ecosystem support landed on launch day: vLLM, llama.cpp, Ollama, Unsloth. NVIDIA updated the license, removing controversial clauses about guardrails and branding, which makes the model genuinely free to modify.
Moonshot (the creators of Kimi) introduced Attention Residuals, a replacement for the classic fixed residual connection with attention over previous layers. The idea: instead of simply adding a layer’s output to its input (as all transformers have done since 2017), the model learns to dynamically weight information from all previous layers. They added Block AttnRes so this wouldn’t kill performance on large models. Here’s the link for those who like to read.
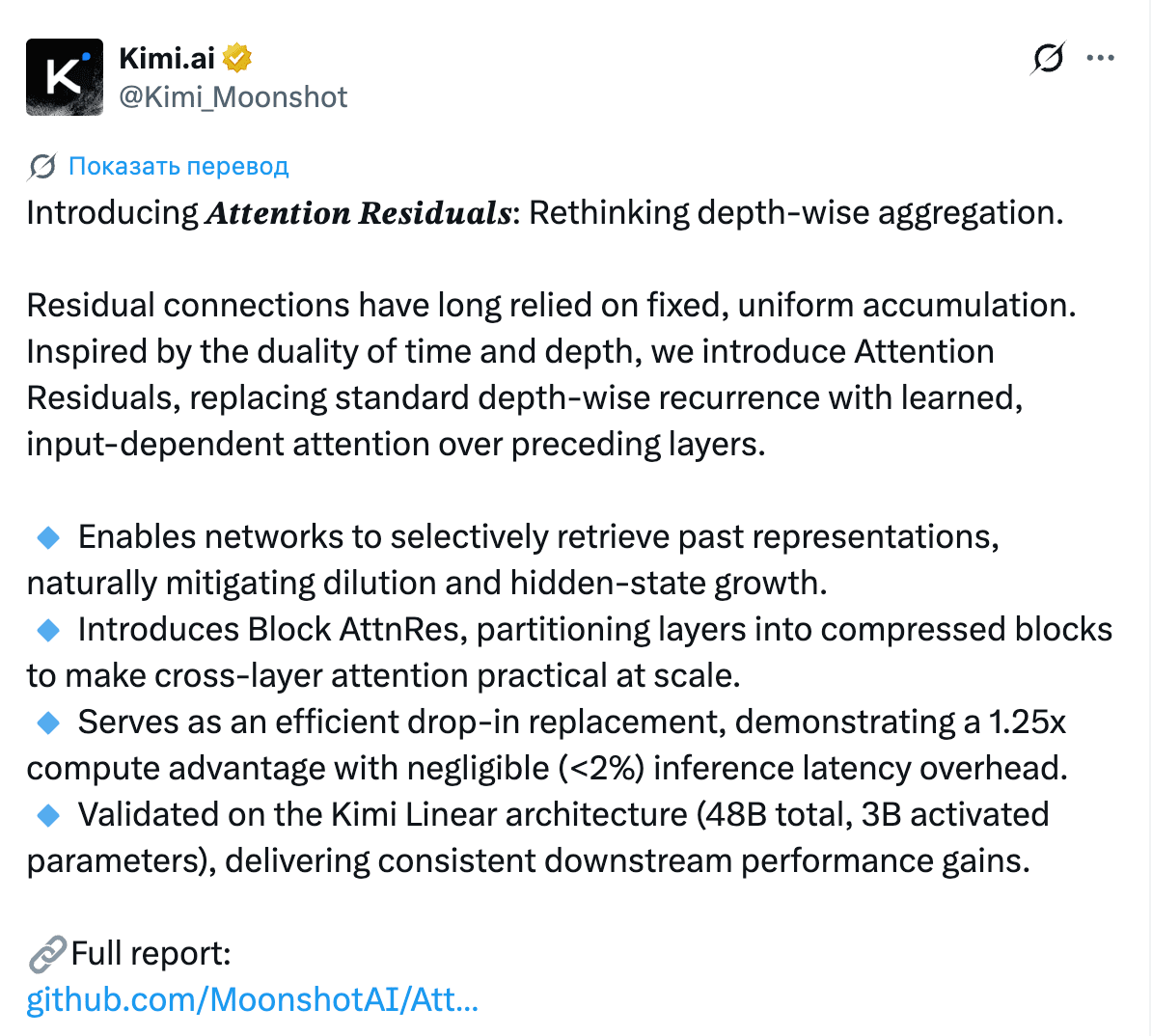
The results: a 1.25x compute advantage (meaning a model with AttnRes catches up to a standard model trained with a 1.25x compute budget), with less than 2% inference overhead. They tested it on Kimi Linear 48B / 3B active. The reaction was intense: from Yuchen Jin to Elon Musk.
Not everyone on Twitter liked it. One and Two. The discussion itself is interesting as an example of the tension in the ML community between “who came up with it first” and “who made it work first.”
Codex added subagents: now within a single session, you can launch child agents for parallel tasks. This finally cements the shift from a “copilot that completes a line” to a multi-agent workflow where one agent writes code, another tests it, a third reviews it, and a fourth deploys it.
The infrastructure layer around coding agents is maturing quickly too. Andrew Ng expanded Context Hub (chub), an open CLI for up-to-date API documentation with support for feedback loops from agents. AssemblyAI released its own skill for Claude Code, Codex, and Cursor. A paper also appeared on automatically extracting skills from GitHub repositories into the SKILL.md format, with a claimed 40% improvement in knowledge transfer. A new stack is taking shape: skill files, up-to-date docs, feedback channels, and procedural knowledge extracted from repositories.
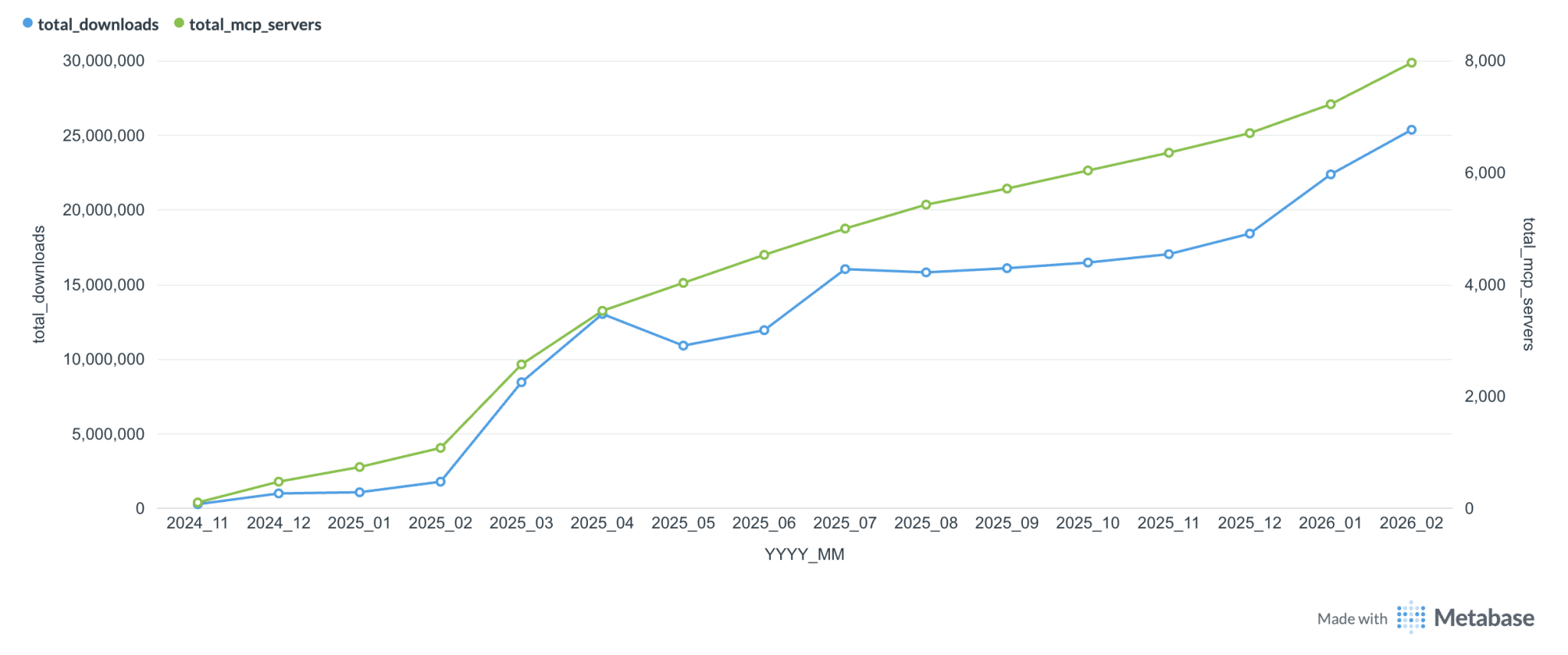
As for MCP, this week it went through another mini identity crisis — people are burying it again. There’s an old joke that there are more MCP server developers than users. But judging by the chart, usage is growing. Personally, I use only one MCP server, ExaMCP. I used to use context7 too, but now it’s available directly in the CLI.
The most substantial breakdown came from LlamaIndex: MCP tools work well when you need deterministic, centrally maintained APIs with fast-changing data. Skills (lightweight local procedures written in natural language) are simpler, but less reliable. You need to choose the right tool for the job.
In parallel, support for Web MCP appeared in Chrome v146, with a demo of a LangChain Deep Agent that continuously monitors X and compiles a daily digest. MCP is definitely not dead. But the hype has passed, and people are starting to figure out where it’s actually needed and where it’s easier to just write a normal script.
Hermes Agent from Nous Research ran a hackathon, and the resulting projects were all over the place: home media server automation for anime, cybersecurity, OSINT forecasting, and research visualization. Participants write that Hermes is easier to set up and more stable in operation than OpenClaw.
What makes Hermes stand out from the rest is persistent memory through Honcho. The agent accumulates knowledge about the user and improves over time, rather than forgetting everything after completing a task. This week, IBM published a paper that treats the memory of multi-agent systems as a computer architecture problem: cache hierarchy, coherence, access control. That echoes what Hermes is doing in practice.
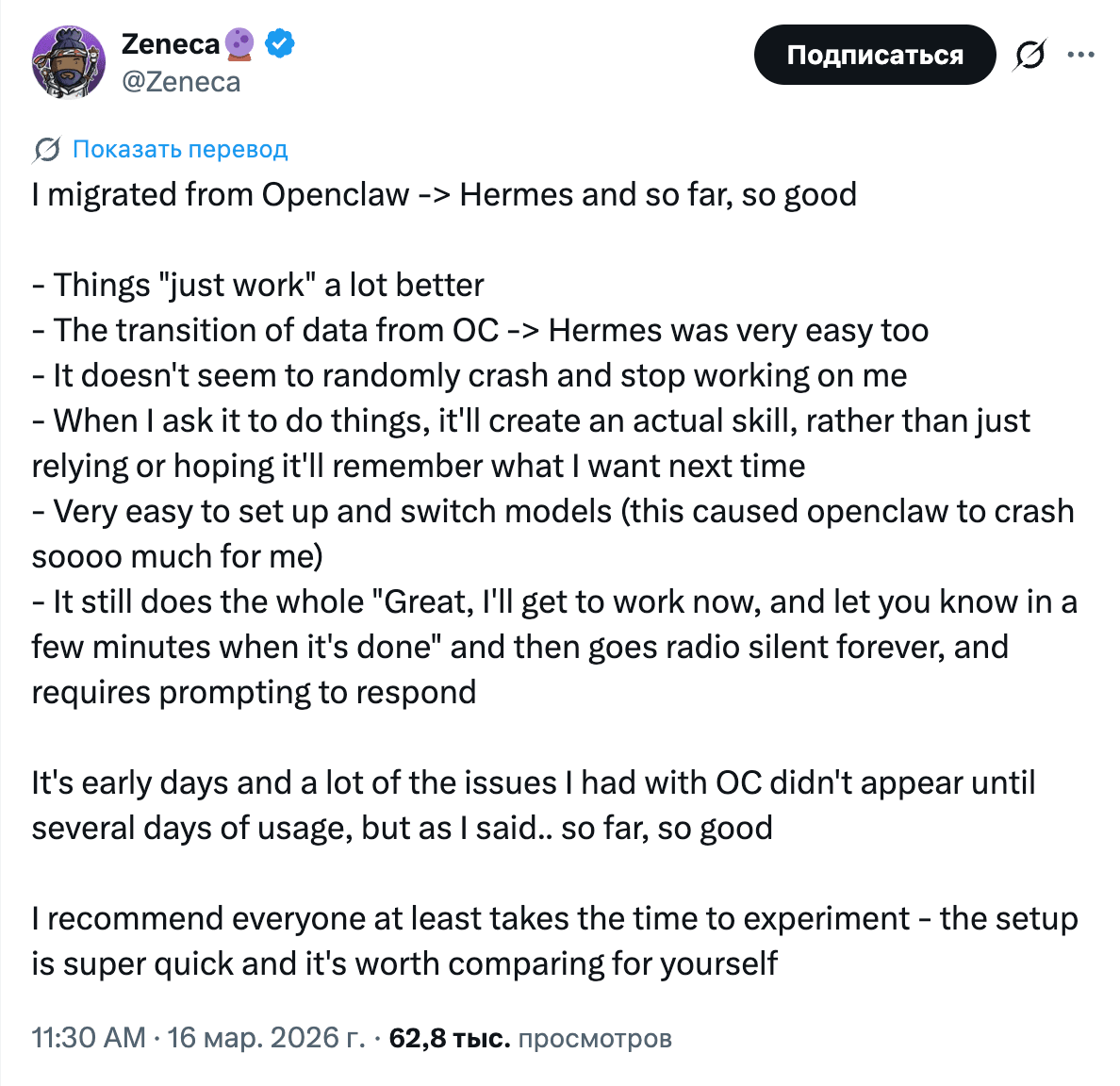
At the same time, OpenClaw is not standing still. Ollama became an official provider, and Comet launched an observability plugin for tracing calls and costs. An ecosystem is forming around both projects, with providers, memory backends, tracing, and hackathon extensions.
Singapore startup Okara launched an AI CMO, a marketing agent for startups. You enter a website URL, and the system spins up a team of specialized subagents: SEO audit, GEO (Generative Engine Optimization), content, Reddit, Hacker News, X. The SEO agent checks the site daily and sends concrete fixes to your email every morning. It costs $99/month.
The announcement tweet pulled in 5.3 million views in 4 hours. The target audience is obvious: indie developers and bootstrap teams that have a product but no marketing budget. Okara claims it replaces $50K–168K per year in hiring costs for a content writer, SEO agency, SMM manager, and community manager.
The fact itself is telling: the multi-agent pattern (one orchestrator + a team of specialized subagents) has stopped being the exclusive domain of coding tools and has arrived in marketing. Codex is adding subagents for code, Okara is doing the same for growth. The question, as always, is execution.
By the way, about context hygiene. Even with a million-token baby, don’t forget to filter what you load into it. And if this week you only have time to try one thing, spend the whole weekend with Claude Code while the promo is still active.
Stay curious.