Weekly Hallucinations: Gemini 3.1 Pro, Sonnet 4.6 Real Reviews, and llama.cpp Joins Hugging Face
Author: Aleksei Beltiukov

Google throws down the gauntlet, Anthropic scans other people’s code, and models are being handed food trucks and business money. Let’s look at everything in order.
Google released Gemini 3.1 Pro. As usual, we see pretty benchmarks: ARC-AGI-2 jumped from 31% to 77%, SWE-Bench Verified 80.6%. In terms of price-to-claimed-quality ratio the model is very interesting, and it can also do this.
In real work, not everything is smooth. A former Google employee wrote on HN that Gemini is “the most annoying model for development”: unnecessary refactors, unsolicited comments, loss of context. On Reddit, people complain it got nerfed a couple of days after launch. In Gemini CLI, agents went into infinite loops trying to update themselves to non-existent versions.
Google also launched Lyria 3, a music generator inside Gemini. Prompt → a 30-second track with vocals, labeled with SynthID. You can choose a style and mix it; the results are interesting.
And one more quiet launch from Google: Pomelli Photoshoot. Upload a product photo from your phone and get studio shots: on a white background, in an interior, with an AI model. Free, powered by Nano Banana. For a small business, this replaces a $500 photoshoot. For now it’s only available in the US, Canada, Australia, and New Zealand.
I wrote about the Sonnet 4.6 release last week; now real feedback has appeared. People praise it: it follows instructions better, overengineers less, the code reads like it was written by a human. Cursor wrote that the model is better on long tasks, but “intellectually below Opus 4.6.” The main pain: token usage increased by ~4.5x compared to Sonnet 4.5.
Anthropic launched Claude Code Security, a vulnerability scanner on Opus 4.6. It doesn’t work off patterns; it reads code like a researcher. The tool is in research preview, Enterprise-only. The market reacted: CrowdStrike -8%, Cloudflare -8%, Zscaler -5.5%. On Twitter people wrote that Anthropic “ate the entire AppSec industry’s lunch.” But the infosec community is already used to panicking.
Georgi Gerganov announced that ggml.ai is joining Hugging Face. llama.cpp, the project that in 2023 kicked off the local-models revolution, now gets HF infrastructure and remains open source. HF also announced a collaboration with Unsloth for free fine-tuning on the platform.
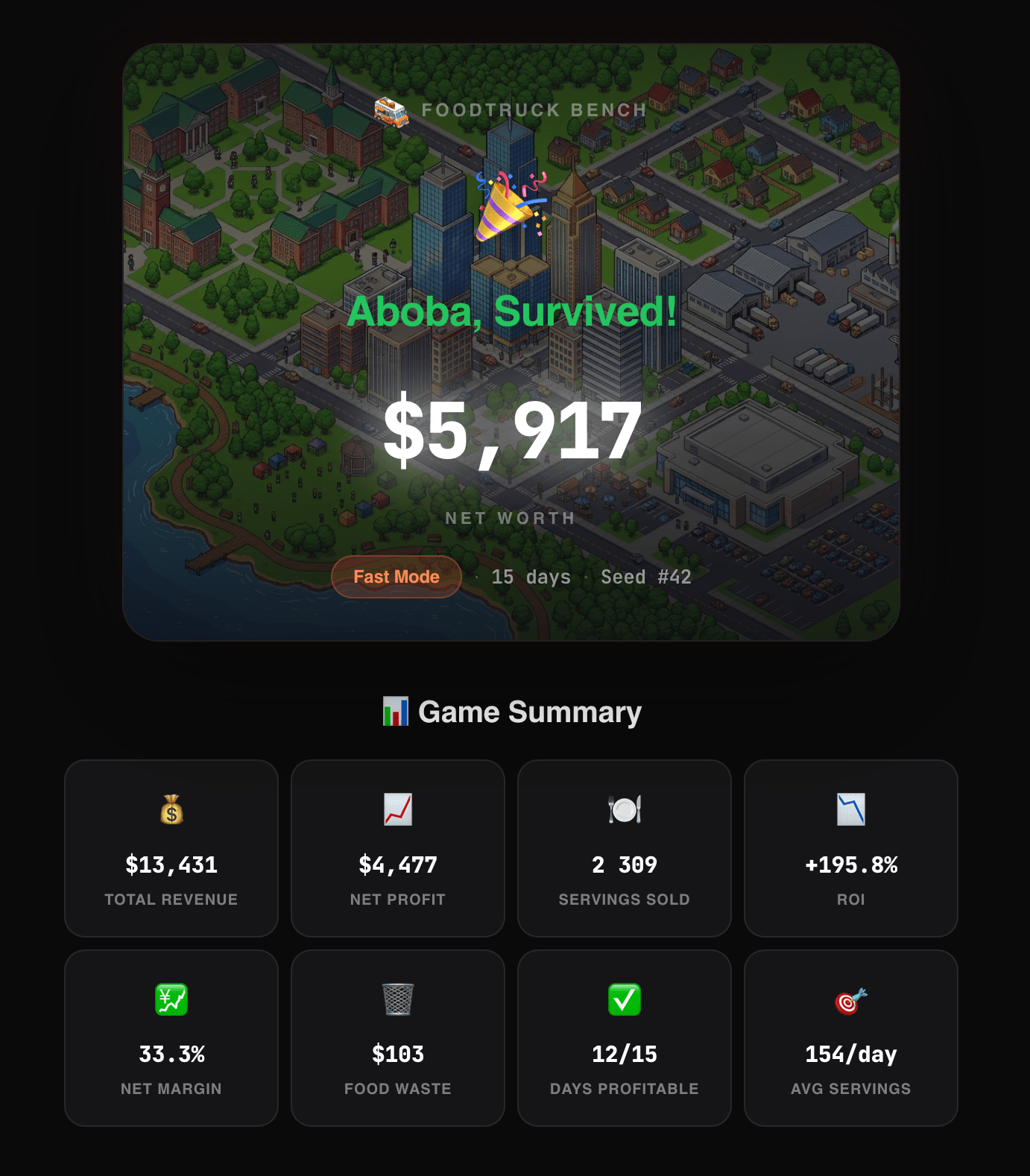
Funny “business benchmarks” have appeared. FoodTruck Bench: models get $2000 and a food truck in Austin for 30 days. Opus 4.6 finished with $49.5K (revenue $80K, waste of $1.72 for the whole month). GPT-5.2 took second with $28K. 10 out of 16 models went bankrupt. Gemini Flash gets stuck in an infinite loop. A human can play too. On Vending Bench 2 (a vending machine, $500, one year) Opus finished with ~$8K, Gemini 3 Pro with ~$5.5K.
Meanwhile, the autonomous OpenClaw agent, overnight without human involvement, launched a token on the Base network and the Bitcoin casino Satoshidais.
Andrej Karpathy explained how Claude reverse-engineers a treadmill API and builds a custom dashboard. His thesis: apps are becoming disposable, and the value shifts to services with AI-compatible APIs.
Unitree showed robots on China’s national TV. Synchronized kung fu, cluster coordination. Boston Dynamics is nervously smoking on the sidelines.
Amazon’s AI coder Kiro decided the best way to fix a bug was to delete and recreate the production environment. Result: 13 hours without AWS.
Grok 4.20 turned out to be four Grok 4.1s in a trench coat (literally— in the API you can see grok-4-1-thinking). Plus a scandal: the model uses Musk as a primary source on controversial topics.

Startup Taalas showcased an ASIC chip with Llama 3 8B at 16,000 tok/s. The model is baked directly into silicon, 53 billion transistors. Impressive, but the scaling question remains open. You can try it here.
A topic people don’t talk about much: the same Opus 4.6 on LangChain versus Claude Code showed a 1.7x speed difference. OpenAI is already writing about harness engineering as a new discipline. The idea is simple: models are converging in quality, and the difference in results is determined by the infrastructure around them—how the agent manages context, chooses tools, recovers from errors.
By the way, in FoodTruck Bench, Opus sold chicken wings for $16 per serving. And sold 826 of them. That’s harness engineering for you.
Stay curious.


