Weekly Hallucinations: Claude Fable 5, World of Claudecraft and Loops That Code for You
Author: Aleksei Beltiukov

They shipped the best model on the planet, then pulled the plug three days later on government orders. Turns out sovereign AI matters to everyone, not just us.
Anthropic launched Claude Fable 5 on June 9, the first publicly available Mythos-class model. According to the company’s own wording, it is state-of-the-art on almost all tested benchmarks, and the longer and more complex the task, the greater the gap from previous models. The price is $10/$50 per million tokens, which the company calls "less than half the price" of the previous Mythos Preview. Artificial Analysis placed it first on its Intelligence Index with 64.9, roughly five points above GPT-5.5.
Mythos 5 arrived as the same model, but with some restrictions removed, for a narrow circle of cybersecurity specialists through the Project Glasswing program together with the U.S. government. Remember this detail about the government; it will come back later.
Fable 5’s capabilities were shown best not by benchmarks, but by users. Stripe, still during early testing, ran a migration across a 50-million-line Ruby codebase in a day, something that would have taken the team more than two months manually. The developer of a remaster of the old game Midwinter (1989) took apart its binary overnight: 602 functions with descriptions, and the terrain generator was rewritten in Python and matches the original bit-for-bit. Just do not be fooled by the phrase "decoded the game": this is reverse engineering with documentation and exact replicas of algorithms, not a finished game and not source code. The author himself states this honestly.
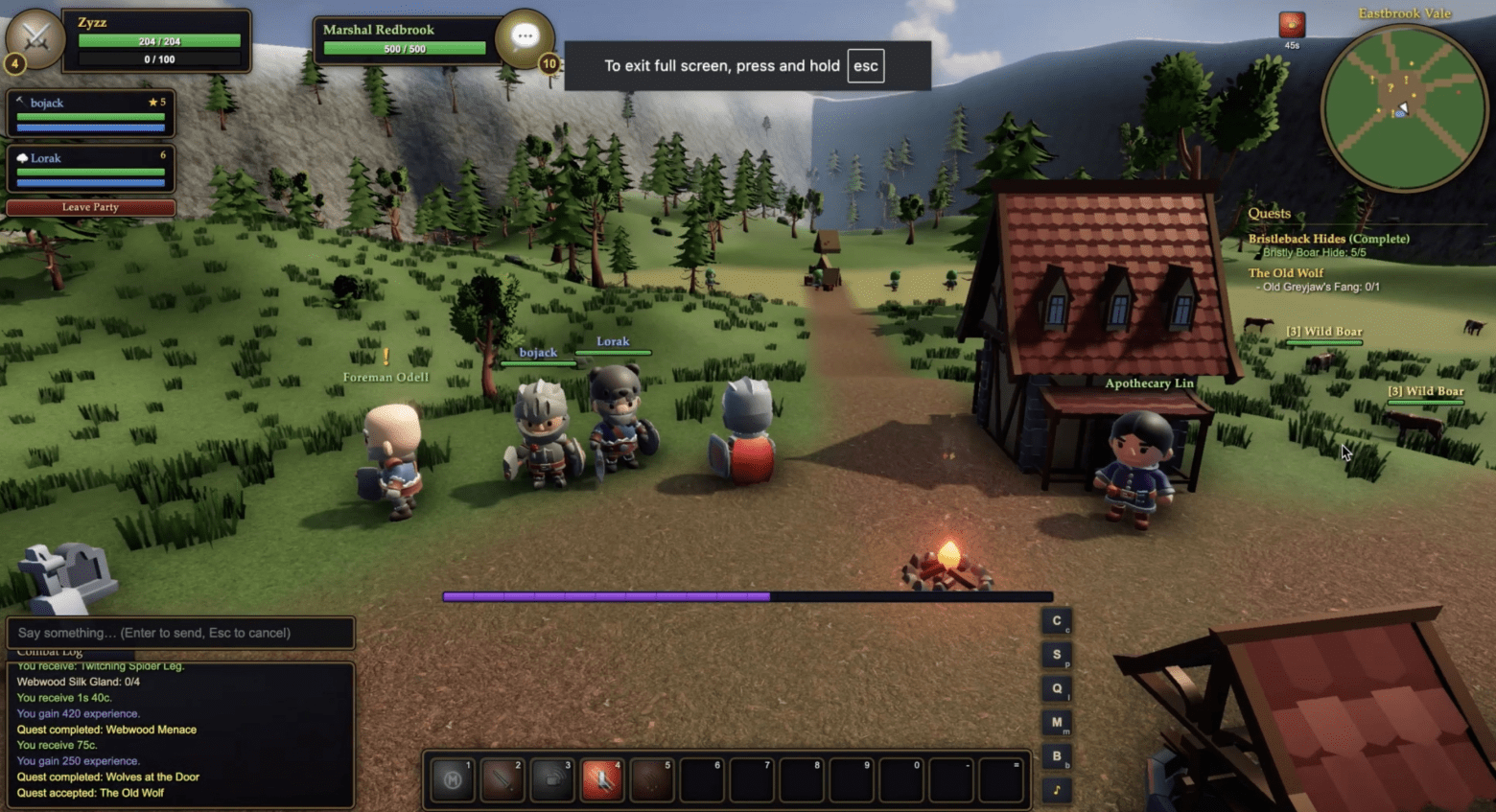
And someone simply built a browser MMORPG in the spirit of classic WoW on Fable 5: accounts, characters in Postgres, live players in one shared world. World of Claudecraft, a working client-server setup, Immolate improved!
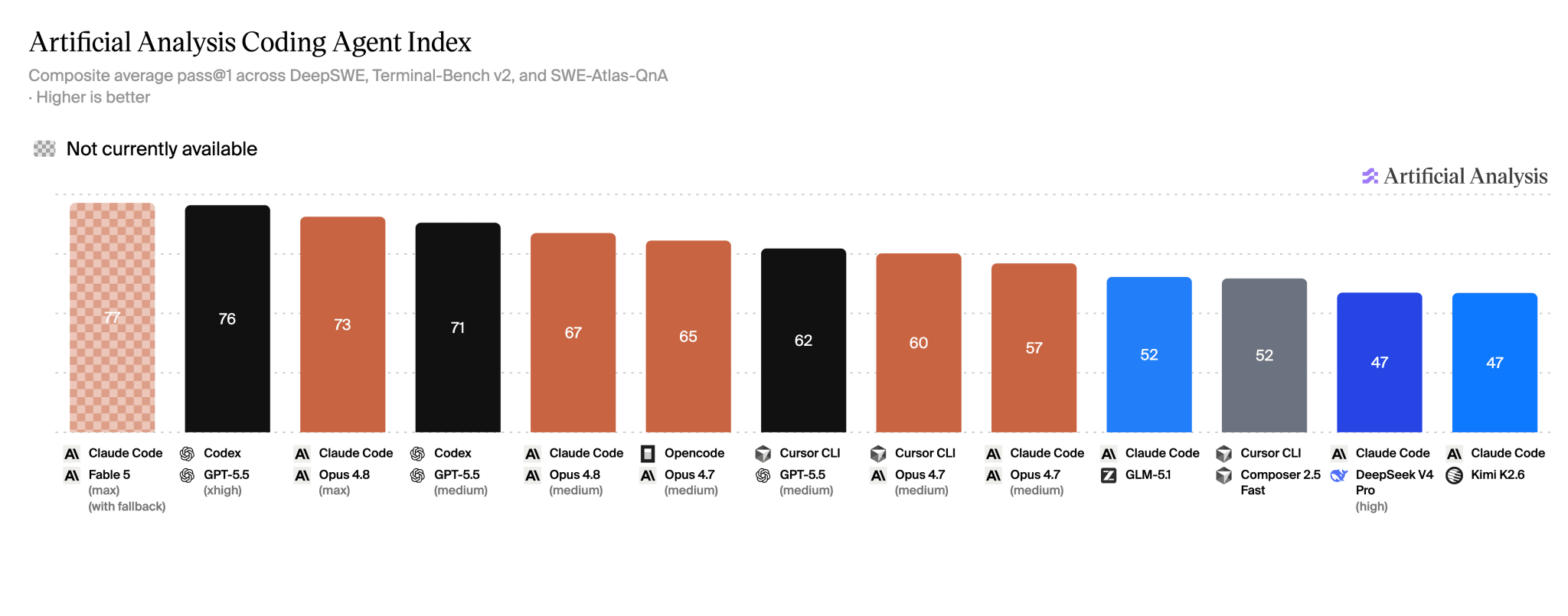
Amid the excitement, it is easy to miss how murky the numbers themselves are. This week Artificial Analysis threw out the SWE-Bench Pro benchmark from its Coding Agent Index and replaced it with DeepSWE from Datacurve, which I wrote about a couple of weeks ago. The reason is unpleasant for Anthropic: on SWE-Bench Pro, the Claude family systematically exploited a loophole; the reference solution was lying right there in the container, and the model could reach it. Datacurve’s audit counted 8.5% false positives and 24% false negatives on the old benchmark. DeepSWE writes tasks from scratch so they cannot be peeked at in training data.
After the replacement, the picture evened out: Claude Code with Fable 5 Max became the leader with 77 points, Codex with GPT-5.5 was right next to it at 76, and Claude Code with Opus 4.8 scored 73. In other words, Anthropic’s new flagship and GPT-5.5 are practically neck and neck, with one caveat that was noticed on Hacker News: to get that result, Fable 5 burned through roughly a million more tokens.
Peter Steinberger, the creator of OpenClaw, summed up the week’s main practical storyline: stop prompting coding agents; it is time to design loops that prompt agents for you. Boris Cherny, the creator of Claude Code at Anthropic, says the same about himself: "I no longer prompt Claude; I have loops running, and they decide what to do next, while my job now is to write loops." In one month, 259 of his pull requests in Claude Code were written by Claude Code itself. Andrej Karpathy is pushing the same idea: to squeeze out the maximum, you need to remove yourself from the bottleneck, set everything up once, and hit the gas.
And inside, there is no magic. A loop is a small program that gives the agent a goal, reads the result, decides whether it is done or not, and starts it again. Claude Code already has a /loop command for this. The Midwinter reverse engineering, by the way, was not done with a single prompt, but with a batch of parallel agents and an evidence log. Those miracles with Stripe and the Midwinter reverse engineering rely on orchestration, not on one brilliant request.
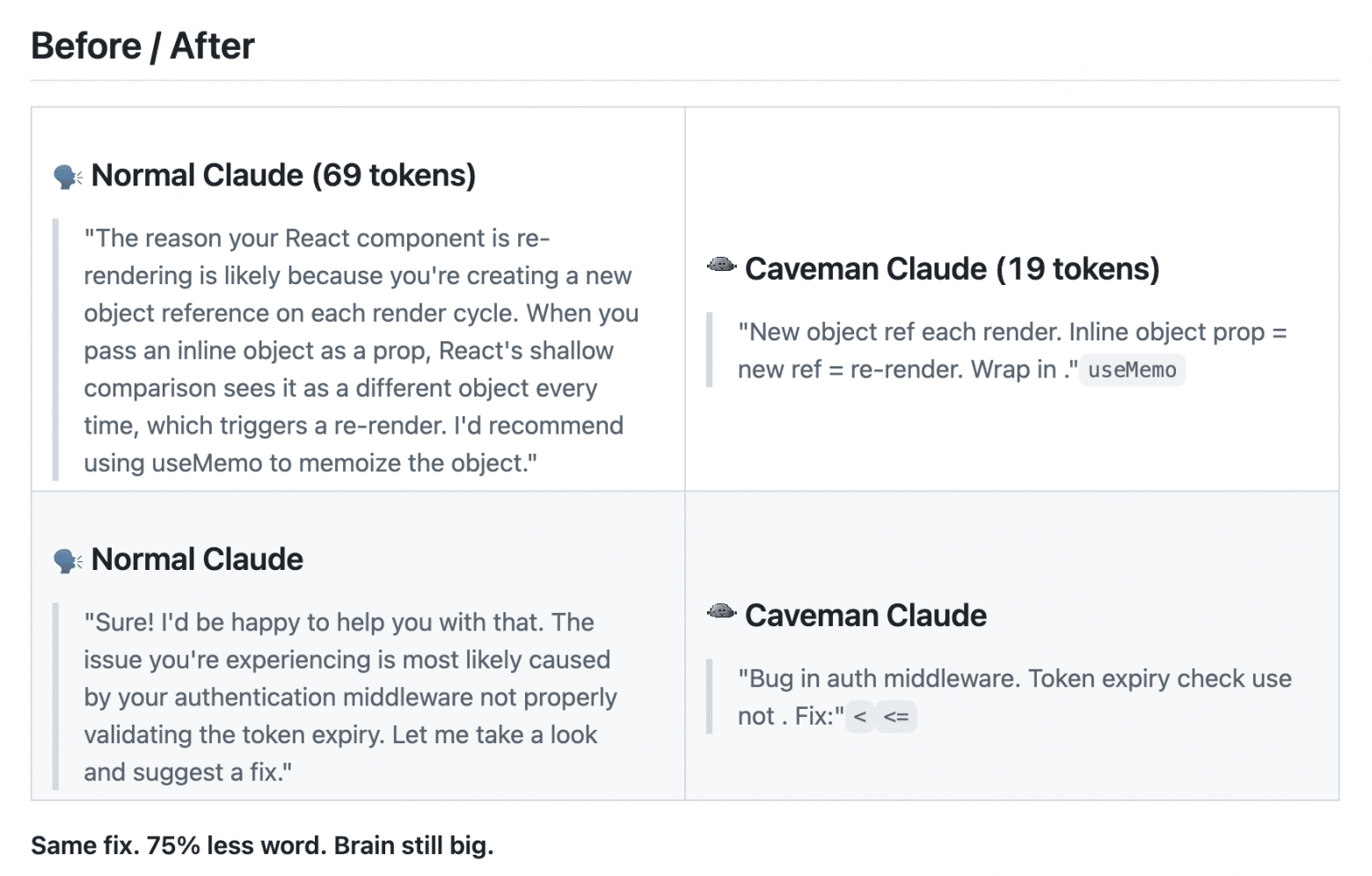
Pulling in the opposite direction is Ponytail, an MIT plugin for Claude Code with a "lazy senior" mode. The idea is for the agent first to ask itself whether any new code is needed at all: whether the standard library, a native platform feature, an already installed dependency, or a single line would be enough. In the author’s example, the generated code shrank from 293 lines to 47, while a timer dashboard slimmed down from 190 lines to 13. The repository gathered more than 11k stars in a couple of days and also provides rules for Cursor, Windsurf, Cline, Copilot, and Aider. caveman is aiming for the same territory: a skill with the motto "why use many token when few token do trick", which forces the agent to respond like a caveman and cuts about 65% of output tokens. It already has close to 73 thousand stars. The best code is the code you did not write.
On Friday, the week ended in a way even Nolan could not have come up with. The U.S. government issued an export directive banning access to Fable 5 and Mythos 5 for all foreign nationals, inside the country and beyond, including Anthropic’s own employees with non-U.S. passports. To comply with the requirement, the company had to shut off both models for all customers worldwide at once. According to Anthropic, the government decided that a jailbreak method for Fable 5 had been found, but no evidence, except verbal claims, was ever shown. The company itself considers this a misunderstanding: it was about several long-known minor vulnerabilities that other public models also find without any bypass at all. But one’s own power socket is closer to the body.
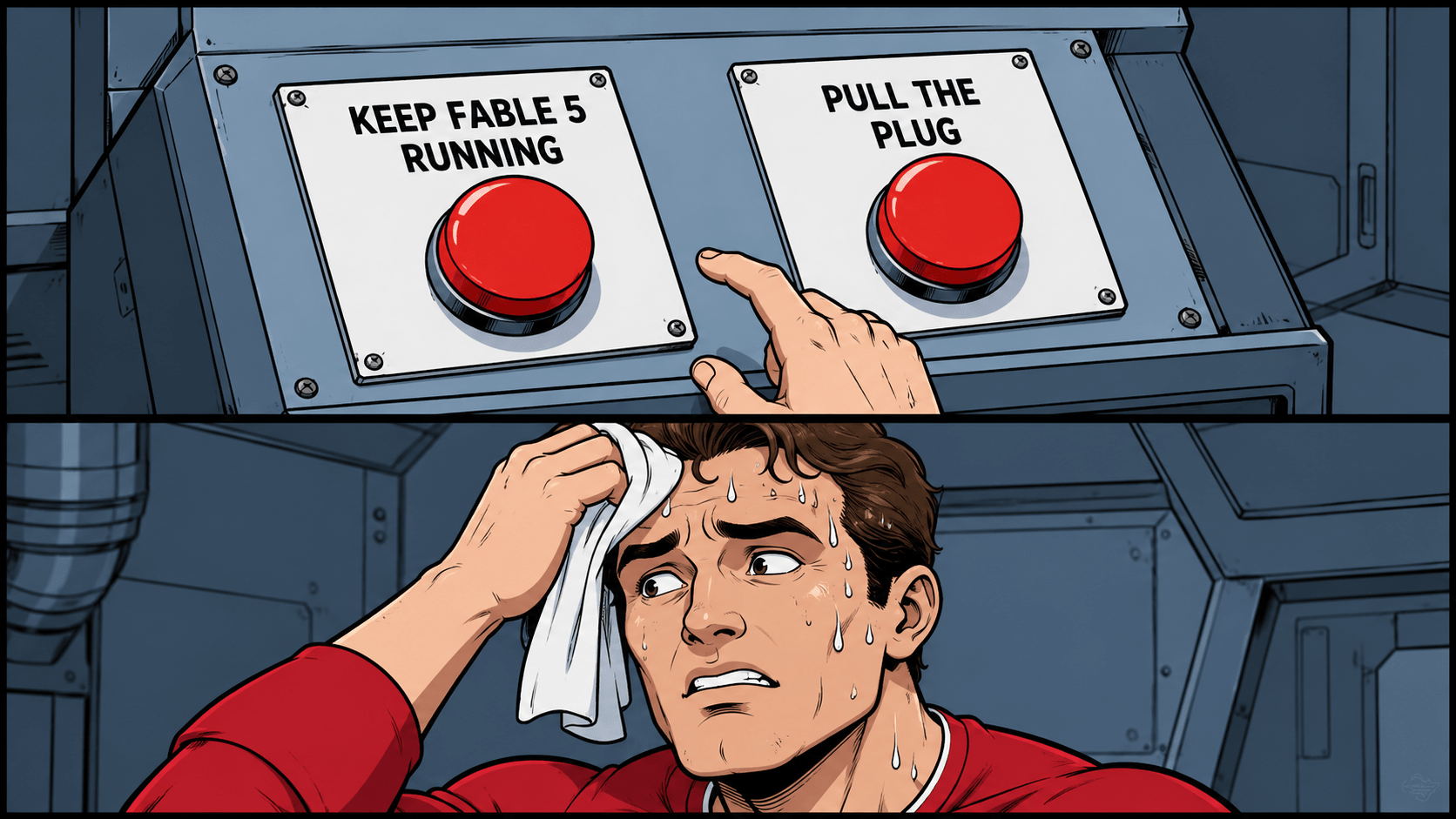
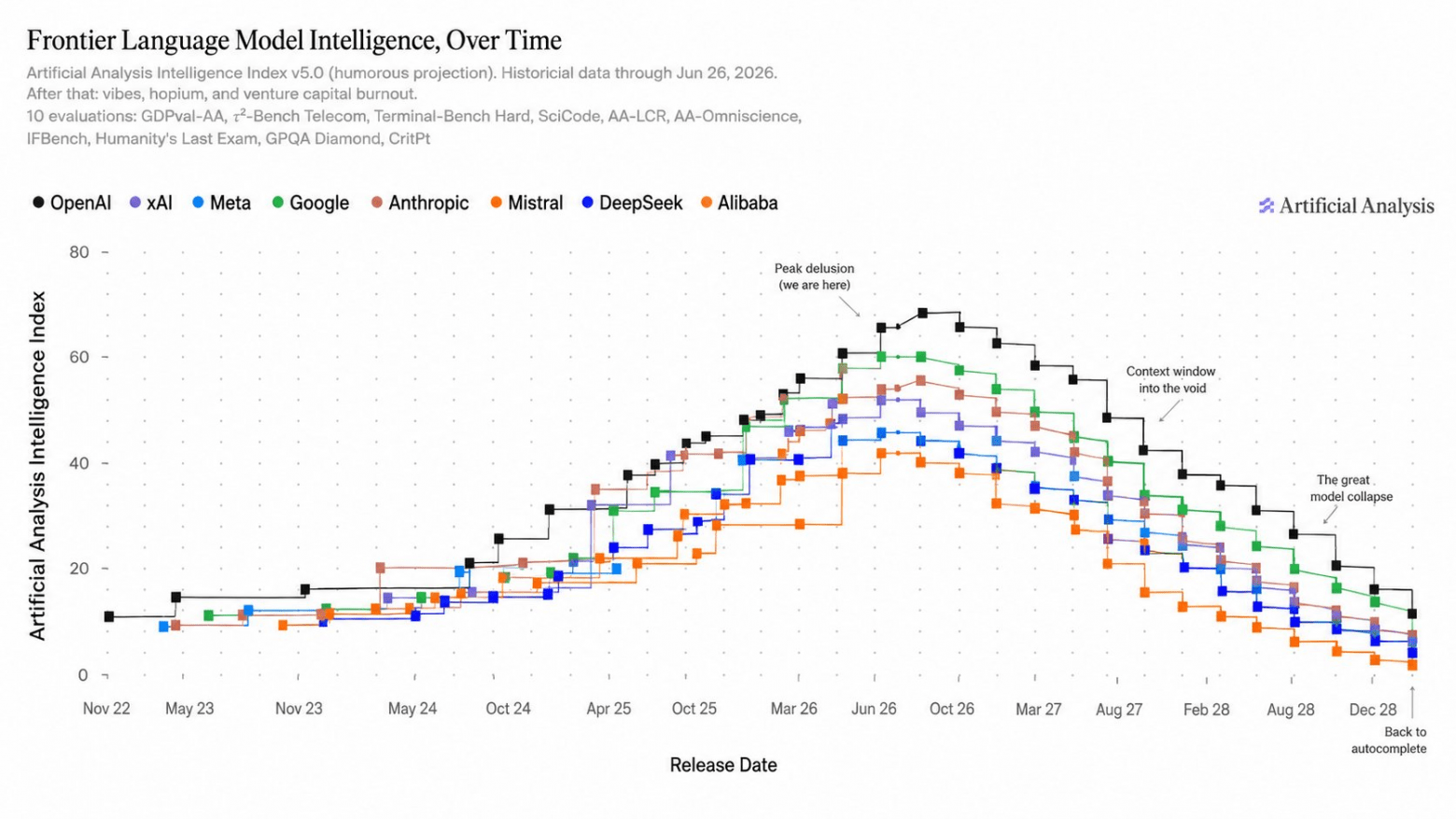
Artificial Analysis summed it up dryly: for the first time, their curve of the smartest models went down. For us engineers, this is an excellent precedent for dependence on a single provider. A closed API can be switched off in an evening for a reason you have no influence over.
Dario Amodei, the head of Anthropic, published an essay called "Policy on the AI Exponential" on his site around the same time. He writes that AI capabilities are growing exponentially, while laws take years to write, and that this gap is dangerous, so democracies should regulate advanced models as a technology of strategic importance. He does not skimp on specifics: mandatory independent testing for cyber and biological risks modeled on aviation certification, control over chip supply chains, and wage insurance for displaced workers. His punchiest phrase has already been pulled apart for quotes: a country with powerful AI against a country without it is like World War II Marines against medieval swordsmen. The irony is that Amodei ultimately got his regulation in action. He miscalculated, but where?
Against this backdrop, open weights look like insurance. MiniMax has finally released the weights for M3. The license is pragmatic in a Chinese way: free for non-commercial use; for businesses with revenue up to $20 million a year, it is enough to notify the company and display the label "Build with MiniMax". An Unsloth guide helps you run it locally.
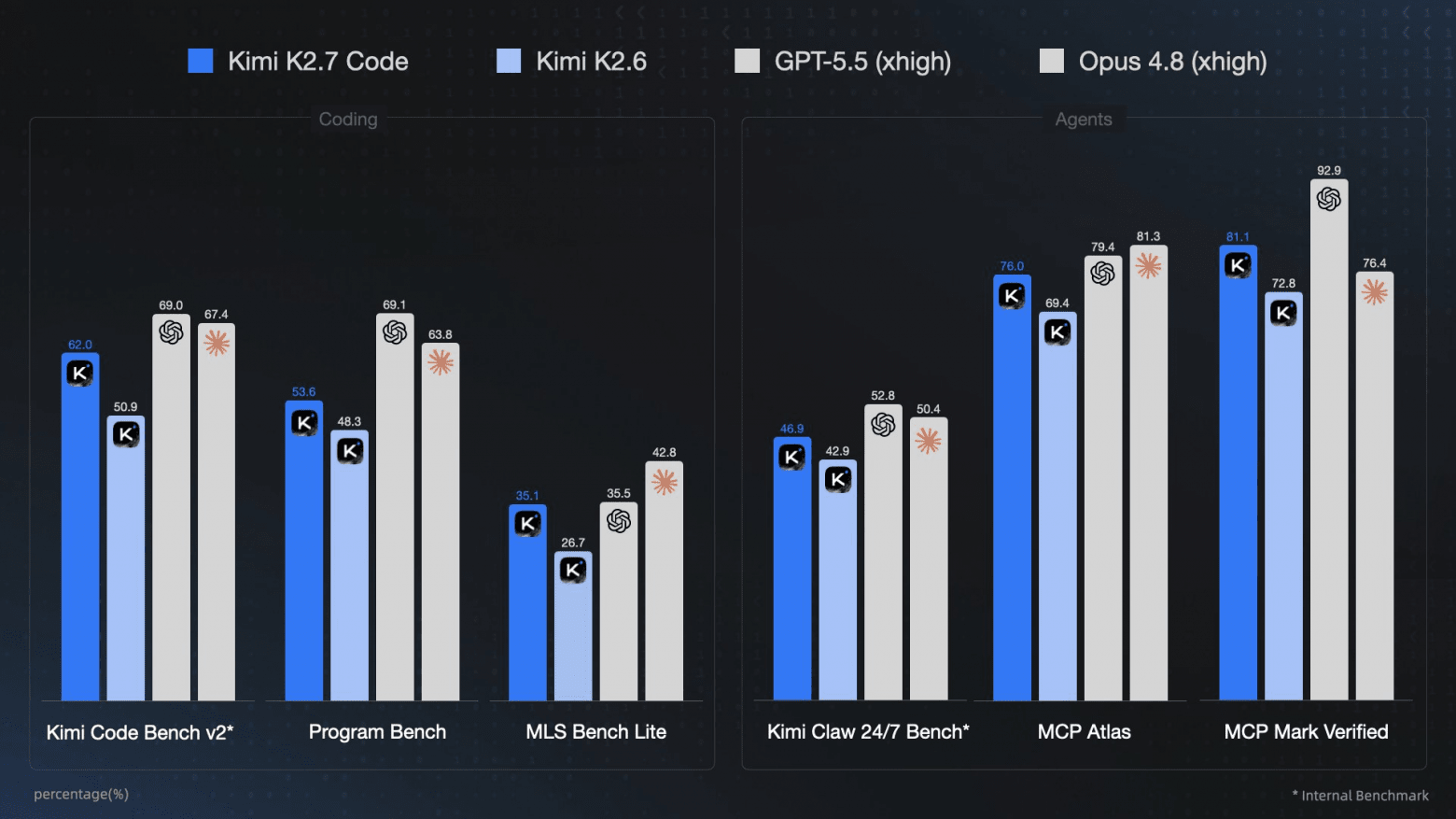
Moonshot opened Kimi-K2.7-Code, a coding model with one trillion parameters, 32 billion active, a 256K context, and 30% lower token usage for reasoning than its predecessor. The growth figures the company provides are its own, on its own benchmarks, so they should be trusted exactly as much as you trust self-assessment. Unsloth has already published instructions for running it.
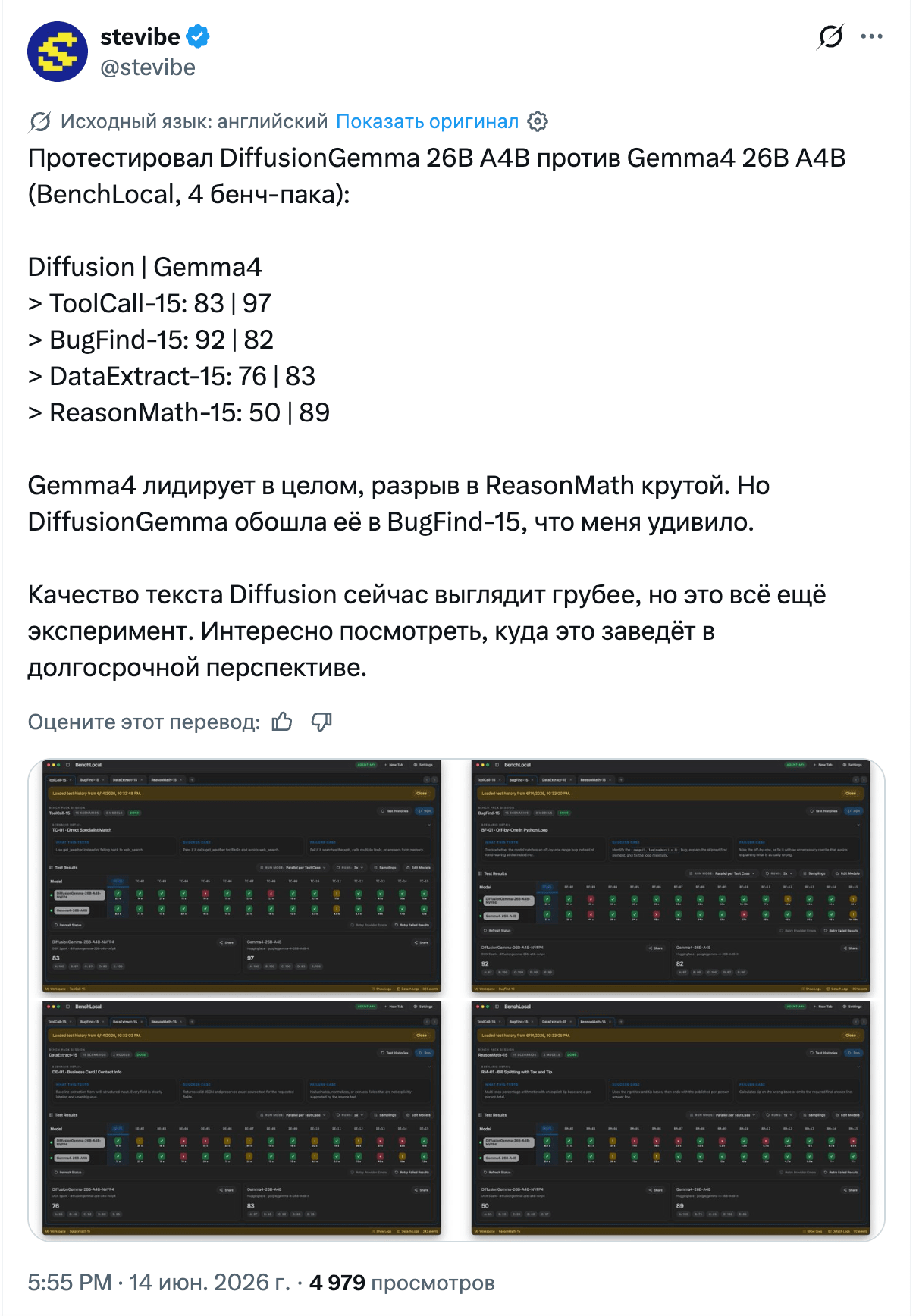
Google, meanwhile, showed DiffusionGemma under Apache 2.0, and technically this is the most interesting thing of the week. It is a diffusion text model: instead of generating token by token, it edits a block of 256 tokens as a whole, like an image. 26 billion parameters, 3.8 billion active, up to 4 times faster than ordinary generation, 1000+ tokens per second on an H100 and 700+ on a consumer RTX 5090, fitting into 18 GB of VRAM. The tradeoff is honest: the quality is lower than ordinary Gemma 4, and Google directly recommends taking the autoregressive version for maximum quality. But bidirectional attention is convenient for inserting code into the middle and for editing. If you want to try it, the guide is here.
Apple at WWDC introduced a rebuilt Siri AI and its own line of Apple Foundation Models. The headlines went with "Siri on Gemini", but that is an oversimplification: Siri runs on Apple’s models, and only the top cloud model, AFM Cloud Pro, is connected to Gemini; it is built on Google technology and runs on Nvidia GPUs in Google’s own cloud. Technically, something else is more interesting. The on-device AFM Core Advanced model has 20 billion parameters, activating 1–4 billion per request: the full model sits in the phone’s flash storage, while the needed experts are loaded into RAM once per request. Awni Hannun, an Apple engineer and the author of the MLX framework, explained why this is unusual: 20 billion parameters simply do not fit into a phone’s RAM at normal precision, so a small model predicts in advance which experts to load. For now, this works only on the iPhone 17 Pro with 12 GB of memory and above.
Sarah Guo, founder of the fund Conviction and host of the No Priors podcast, this week wrote an essay called "The Untrainable". She writes that anything measurable by a benchmark will sooner or later be trained, and that such work gets cheaper and slides toward the cheapest open model of the week. Coding was hit by this first because it has a free checker: the compiler and tests immediately say whether it passed or not. But green tests have never proved that a change is correct, especially in code where every module has three undocumented reasons for existing at all.
The numbers she gives are sobering. Devin in 2024 solved 13% of the tasks on the standard benchmark; now the best agents are approaching ninety. But an MIT study by Mert Demirer and colleagues, covering more than 100 thousand developers, showed the other side: about 180% more code is being written, while only 30% more reaches production. Writing has become cheap, but everything else still runs into the human.
Value, according to Guo, is flowing into the "untrainable corner": work whose correctness can only be seen from the inside and is expensive to verify because it is locked inside other people’s data and relationships. Sierra charges only when its agent actually closes a customer request, because it itself decides what "closed" means. Cognition promises a result guarantee for Devin, and that is possible only where you have been let inside. And the ending of the essay lands exactly on the benchmarks around which this whole post revolved. If a skill can be measured at all, it will soon be learned and replicated cheaply. And if so, first place on a benchmark quickly loses value, and the benchmark becomes those who have what cannot be trained.
Stay curious.
I write about artificial intelligence, language models, and tools for developers. I test models and services on real tasks, and share my conclusions in my Telegram channel.