Weekly Hallucinations: Composer 2, Unsloth Studio, and Claude That Clicks Buttons for You
Author: Aleksei Beltiukov

Cursor got caught with Kimi under its cloak, OpenAI is buying up Python infrastructure, Claude is learning to live outside the terminal, and Unsloth has decided it’s time to hand fine-tuning over to ordinary people. Let’s break it all down.
Cursor released Composer 2, and at first everything looked almost exemplary. 61.7% on Terminal-Bench 2.0 versus 58% for Opus 4.6, a price of $0.50/$2.50 per million tokens, and a story about post-training and RL backed by a serious budget. For a product that many still saw as a convenient wrapper around other people’s models, this was already a step into a new league. Honestly, my first thought was: well, that’s it, Cursor has finally decided to stop being just a storefront.
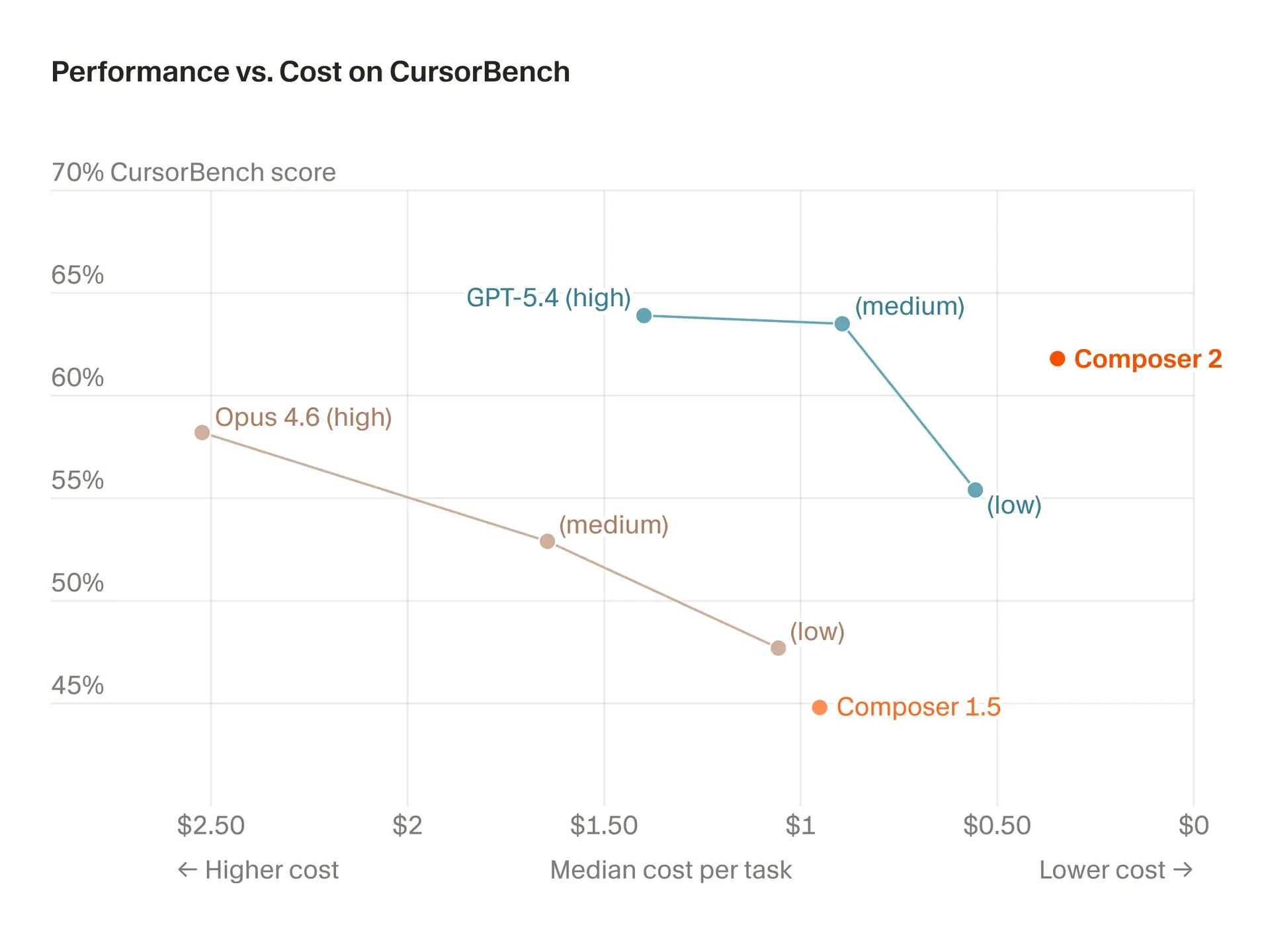
And then the internet did what it does best. First, people noticed that Composer 2 had a suspiciously familiar tokenizer. Then a model URL surfaced in the debug output. Next, Clement Delangue from Hugging Face reminded everyone about the licensing nuances of Kimi K2.5, and Reddit quickly branded Cursor a wrapper. The beauty didn’t last long.
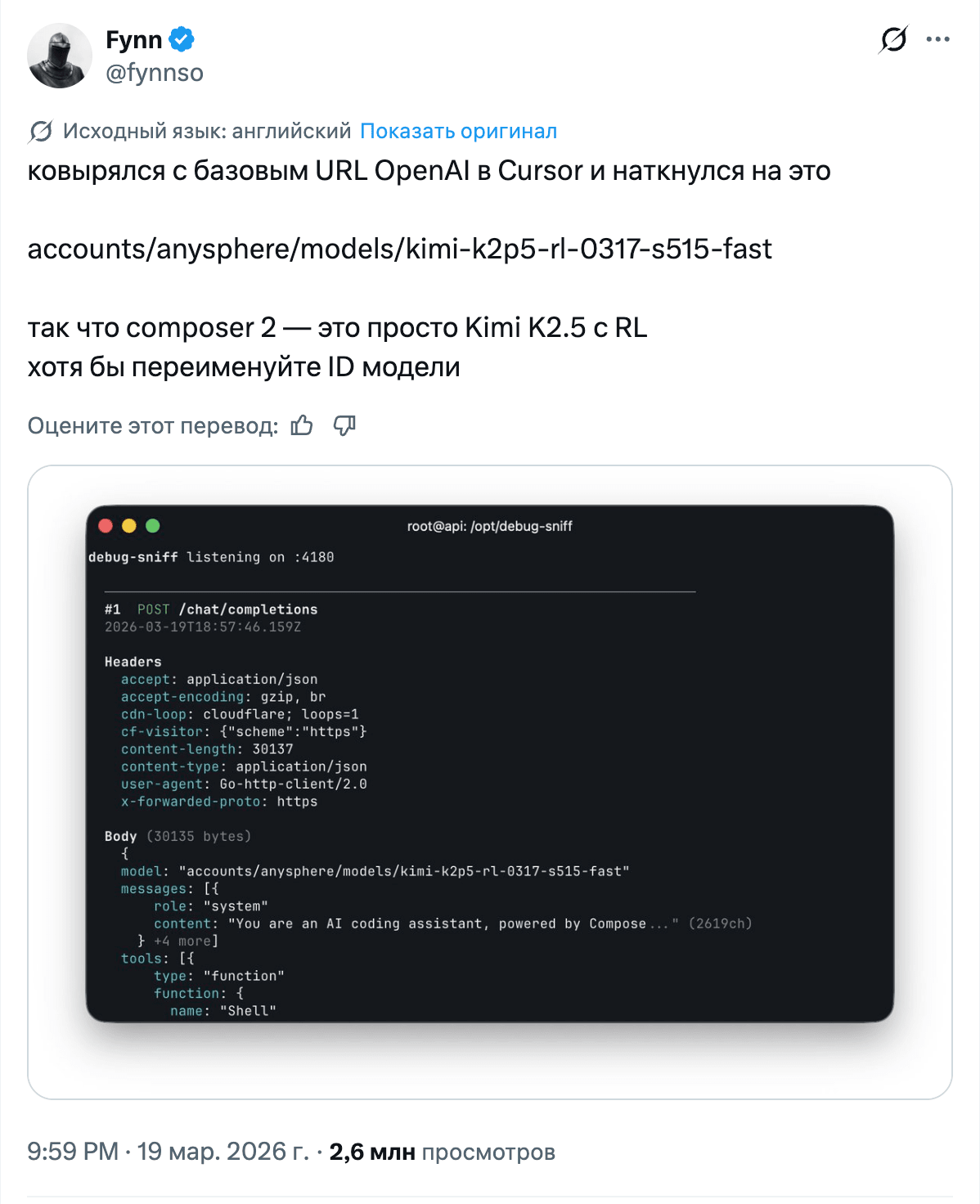
A few hours later, Cursor explained that K2.5 really had been the base, but the main work lay in their own post-training and RL, all done through a commercial partnership with Fireworks. Moonshot AI confirmed this. To me, the key point here isn’t the drama itself, but the precedent: a major product takes a strong Chinese open-weight model, fine-tunes it, and sells it as its own value layer. There will only be more stories like this. Next time, they’ll probably package it more honestly with wording like “built on top of X,” just to avoid triggering a half-day detective saga for free.
OpenAI, meanwhile, acquired Astral, the team behind uv, ruff, and ty. If you write Python, you already live inside their ecosystem. I’d put it even more bluntly: many of us are already half-working inside Astral, we just don’t say it out loud. The Astral team is joining Codex. Google previously picked up Antigravity, Anthropic bought Bun. Now OpenAI is pulling developer infrastructure closer too. Labs no longer want to own just the model. They want to own the toolchain through which the developer works in the first place. Against that backdrop, Fidji Simo’s remarks about winding down side quests and merging ChatGPT with Codex into a super app sound perfectly logical.
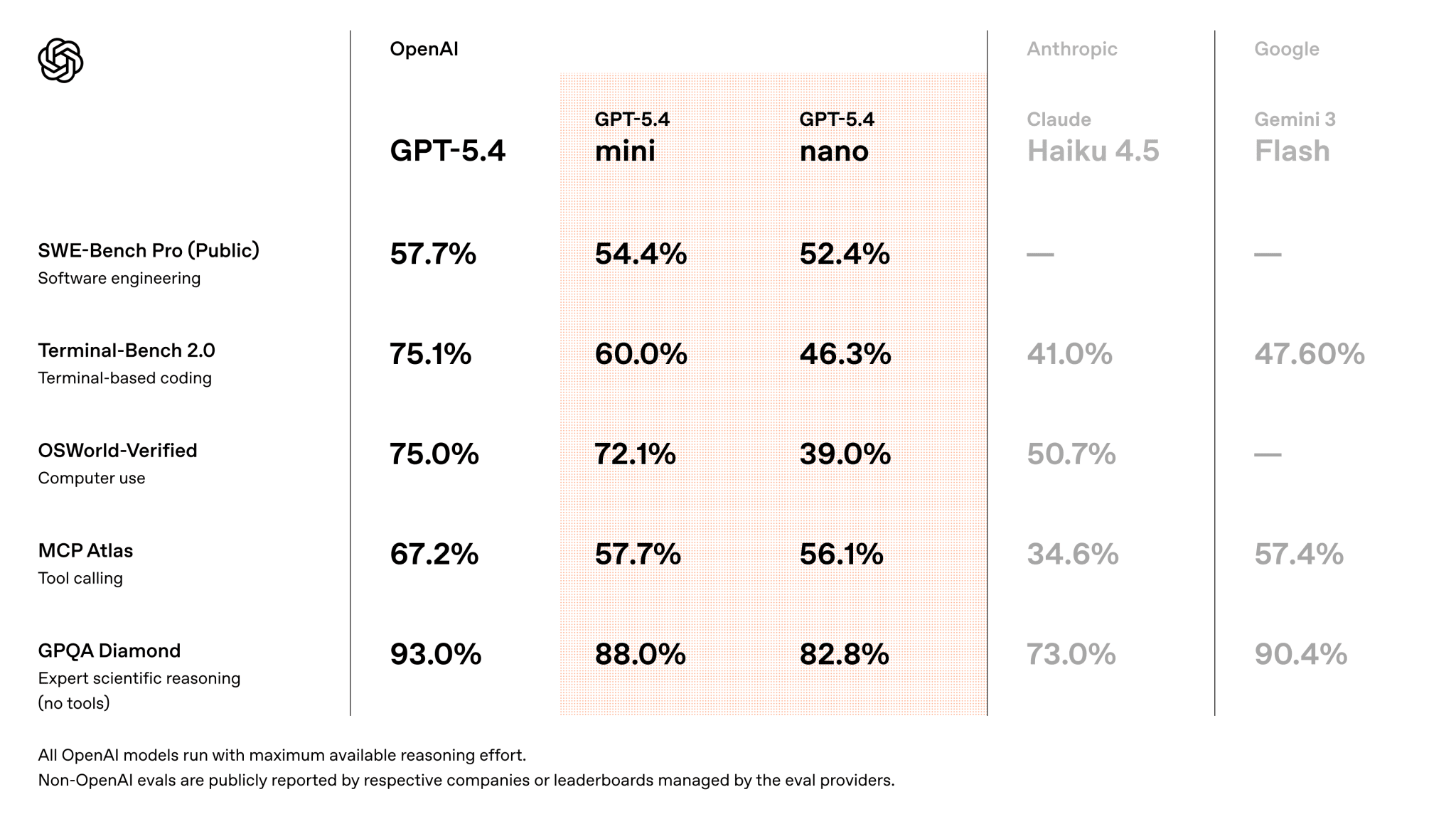
That same day, OpenAI also rolled out GPT-5.4 Mini and Nano. Mini is 2x faster than GPT-5 mini, with a 400k context window and pricing of $0.75/$4.50 per million tokens. But the positioning matters more: this isn’t “just another smaller model,” but a cheap workhorse for background tasks, subagents, and everything you don’t want to hand over to an expensive flagship. In Codex, Mini consumes only 30% of the GPT-5.4 quota, and on APEX-Agents it scores 24.5% Pass@1 with xhigh reasoning. Not a miracle machine. But for real-world routine work, it’s already more than enough. At the same time, on BullshitBench the new little models don’t look especially impressive, which is actually a useful reminder: a cheap model for routine work is not the same thing as a model you can mindlessly trust with fact-checking.
Claude, for its part, got Computer Use in research preview on macOS. Which means it can now actually click buttons, move the mouse, open apps, browse the web, and fill in spreadsheets through Cowork and Claude Code. Alongside that came Dispatch, where you can send a task from an iPhone and Claude will carry it out on the desktop. Simon Willison and Ethan Mollick compared this to OpenClaw, with the comparison favoring Claude. And then Claude Code Channels for Telegram and Discord arrived too. The coding agent is no longer confined to the terminal. You message it in chat, the task goes into the working environment, and the result comes back. Slightly Black Mirror. But already useful.
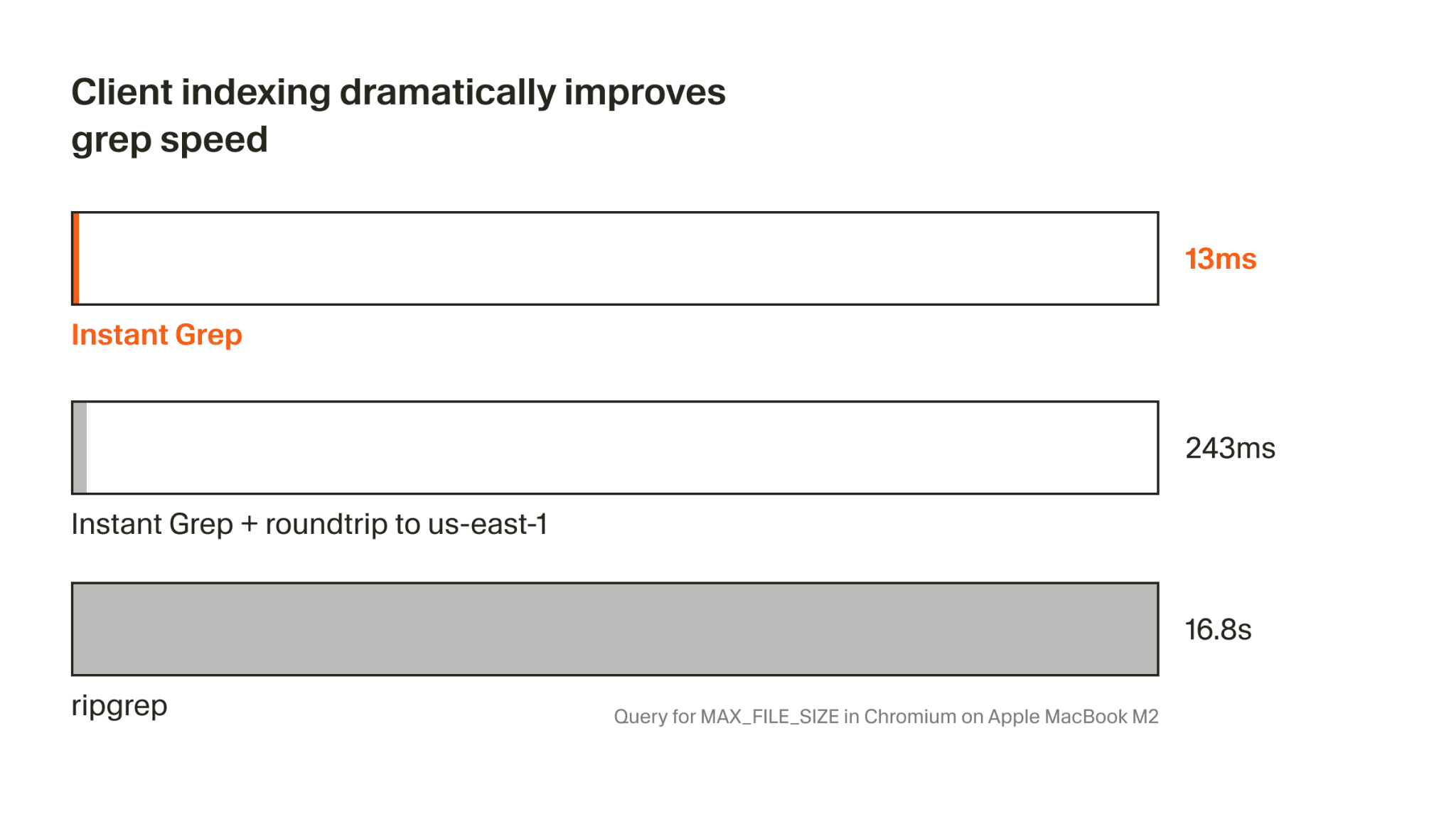
That same week, Cursor also released Instant Grep. They showed regex search across millions of files in 13 milliseconds instead of 16.8 seconds with ripgrep. It’s all built on n-grams, inverted indexes, and bloom filters, but the point isn’t the implementation so much as the behavior it enables. For an agent, searching through a repository is part of thinking. When that search becomes almost free in time terms, the agent can afford more iterations, more checks, and much more aggressive navigation through code. Hopefully the numbers aren’t embellished.
MiniMax released M2.7 and framed it as a model that participates in its own evolution. The wording is a bit theatrical, but the idea is clear: autonomous optimization loops where the model analyzes mistakes, proposes changes, modifies code, and evaluates the result. 100+ cycles yielded a 30%+ improvement on internal evaluation sets. The benchmarks look solid too: 56.22% SWE-Pro and 57.0% Terminal Bench 2. Artificial Analysis gives it an Intelligence Index of 50 at a price of $0.30/$1.20 per million tokens. The model almost immediately appeared in Ollama, OpenRouter, and Vercel, but Reddit is rightly asking how well those numbers actually carry over into production.

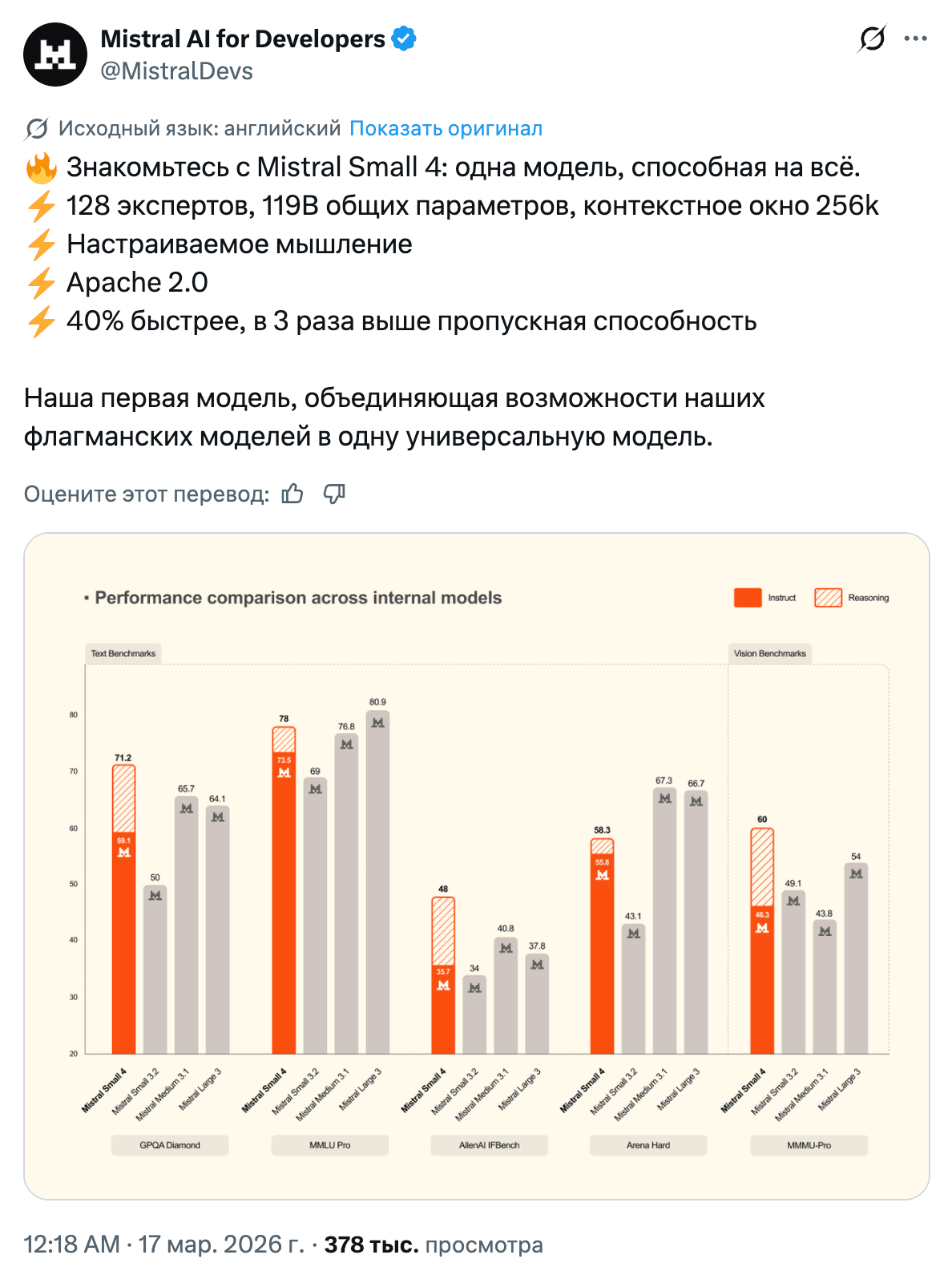
Mistral released Small 4, while Qwen 3.5 Max Preview climbed very high on LMSYS Arena. The midweight model market is becoming crowded and fiercely competitive: reasoning mode, multimodality, long context, yet another index from Artificial Analysis. Meanwhile, Qwen Image 2.0 had its “Open-Source” tag changed to “Release,” and the community read that as a signal: openness is wonderful right up until people start counting the money.
Against that backdrop, Unsloth Studio looks especially refreshing. It launched as an open-source interface for locally running and training 500+ models. The release comes with plenty of attractive claims: 2x faster training, up to 70% less VRAM, support for GGUF, vision, audio, embeddings, and automatic dataset creation from PDF, CSV, and DOCX. But if you strip away the fluff, the core promise is very simple: fine-tuning directly from the UI. I like releases like this more than yet another “smartest model in the world,” because at least this is something you actually want to use. On Reddit, Unsloth Studio was immediately compared to LM Studio, and the comparison is pretty uncomfortable for LM Studio: that one is mostly about inference, while this is already trying to capture both execution and training.
I also want to note the release of Mamba-3. As I wrote earlier, interest in SSMs and hybrids hasn’t gone anywhere, because pure attention runs into inference-cost and long-context limits too quickly. Mamba-3 is being positioned as an inference-first SSM and the best linear model at 1.5B for prefill+decode. But what matters more than the marketing line is the tone of the discussion around it. On Twitter, people are explicitly talking about replacing Gated DeltaNet in hybrid systems, while Tri Dao explains that nonlinear RNN layers add something that neither attention nor linear SSMs can provide on their own. You can read more here.
To close out the week, Luma showed Uni-1: an autoregressive transformer that thinks first, then generates pixels. There aren’t many details yet, but the idea is interesting. If the model first builds an internal plan of the scene and only then renders it, the quality and controllability of generation could improve significantly over time. For now, we’re just watching.
Dear ripgrep, we still love you. But 16.8 seconds versus 13 milliseconds is the kind of gap that makes you look at old tools with a little jealousy. Maybe not all of the future belongs to new models. Maybe part of the future belongs to the people who simply give agents decent hands.
Stay curious.


