In the Beginning Was Silicon: Why Chip Architecture, Not Code, Defines the Future of AI
Author: Aleksei Beltiukov

We, developers and AI enthusiasts, love to argue about choices. PyTorch or TensorFlow? OpenAI or Anthropic? Deploy on AWS, Google Cloud, or set up our own cluster? Every day we make dozens of decisions that, we believe, determine the fate of our projects. We feel in control, architects of complex systems, where our intelligence and our code are the main driving force. We choose frameworks and defend our models in holy wars in the comments. It's an intoxicating feeling of control, an illusion of omnipotence in a world we create line by line.
Now let's hit pause and change the scale. What if I told you that all these choices, all this intellectual acrobatics, are just games in a sandbox? And that the boundaries of this sandbox, its shape, and even the properties of the sand were determined long before we wrote the first line of code. They were etched into silicon in sterile laboratories by people we rarely see – hardware engineers.
I propose we look at our profession through a metaphor. We, developers, are architects. We design elegant buildings of code, thinking through their logic, aesthetics, and functionality. We can build a graceful skyscraper or a cozy country house. But no architect begins work without a report from a geologist. It is the geologist who tells us where we can build and where we cannot. They study the composition of the soil, the depth of solid rock, and seismic activity. They define the fundamental, unchangeable laws of the physical world that the architect must accept as given. We cannot build a skyscraper on a swamp, no matter how brilliant our design.
In the world of artificial intelligence, "geology" is chip architecture. It determines which mathematical operations will be fast and which will be painfully slow. Which types of models will thrive and which will remain beautiful theories on paper. We can argue all we want about the advantages of recurrent neural networks, but if the "geology" of our GPU is designed for massive parallelism of matrix multiplications, then Transformers will win. This is not a question of code elegance; it is a question of fundamental physics and the economics of computation.
This idea was best expressed by the man who is, in essence, the chief "geologist" of our era. Jensen Huang, CEO of NVIDIA, noted this year that accelerated computing requires "full-stack development, not just chips." This phrase encapsulates the whole point: performance is not a property of a single component, but the result of the harmony of the entire system, from transistor to software API. The illusion that we can simply write code in a vacuum shatters against the reality of silicon.
So who really determines the future of AI – us, the code architects, or them, the geologists who shape the very landscape on which we build? In this article, we will embark on a journey into this question, from NVIDIA's monopoly and perpetually second-place AMD to the rebellion of alternative chips, to understand whose laws truly govern our industry.

NVIDIA's Legacy: How an "Ideal Marriage" Created Modern AI
So, if we accept the "Architect and Geologist" metaphor, the history of modern AI is the story of discovering one incredibly successful geological stratum. For a long time, neural network architects wandered through various landscapes, trying to build their structures on shaky or inconvenient ground. But at some point, they stumbled upon the perfect foundation – a Graphics Processing Unit (GPU) from NVIDIA, which seemed specifically designed for one particular architectural style. That style became the Transformer.
This was not just a fortunate union; it was an "ideal marriage" that defined the industry's development for a decade to come. To understand its nature, one must look at both sides of this partnership. The Transformer was a brilliantly designed key, but its brilliance was fully revealed only because it perfectly fit the lock – the GPU architecture.
What exactly was this lock? Initially, GPUs were not intended for AI. But with the advent of the Volta architecture, NVIDIA engineers embedded something revolutionary into them – Tensor Cores. Imagine a regular CUDA core as a versatile craftsman capable of performing various tasks. A Tensor Core is a highly specialized robot on an assembly line that can do only one thing: take two matrices, multiply them, and add them to a third (FMA operation). And it does this with unthinkable, superhuman speed. In addition to this, it learned a mathematical trick called mixed-precision computing. It's as if our robot understood that for most operations, jewel-like precision isn't needed, and began performing them with lower-precision data formats (e.g., FP16, BF16, TF32, FP8), accumulating the final result in a high-precision format (FP32). This allowed for even greater throughput.
And then the key enters the scene – the Transformer architecture. Its heart, the attention mechanism, is essentially a gigantic sequence of precisely those operations for which Tensor Cores were optimized – matrix multiplications. This was a perfect match. The Transformer didn't need the GPU to do anything else. It needed it to do one single thing, but do it faster than anything else in the world.
The contrast with previous architectures, such as RNN and LSTM, is striking. This was a "failed marriage." Their fundamental problem is their sequential nature. To process the fifth word in a sentence, they must wait for the result of processing the fourth. For a massively parallel GPU architecture, where thousands of cores are ready to work simultaneously, this is a disaster. Most "workers" simply stand idle, waiting for a single sequential process to complete. It's like trying to use a giant quarry excavator to dig a trench for a cable – all its power proves useless.
The result of this "ideal marriage" was not just evolutionary, but revolutionary. This was not a 10-15% improvement. NVIDIA benchmarks showed that training models like BERT on GPUs with Tensor Cores accelerated up to four times. This was a qualitative leap that transformed theoretical research into engineering reality. Models that used to take weeks to train could now be trained in days. This union of GPU and Transformer became the solid geological foundation upon which AI architects could finally begin to build their skyscrapers. By the way, I discussed the problems of this architecture and elegant solutions in the form of MoE and SSM in this article.

The Rise of Alternatives: Three Fronts and a Head-on Attack
The ideal marriage of NVIDIA and Transformers spawned a whole civilization, but like any empire, it began to suffer from its own success. The world built on GPUs proved expensive, scarce, and not always efficient. When launching a simple chatbot requires a cluster of hardware costing tens of thousands of dollars, it becomes obvious that a geological foundation, ideal for skyscrapers, is completely unsuitable for building ordinary homes. This pain – economic and architectural – created fertile ground for a rebellion.
But this marriage was cemented not only in silicon. The true cement that tightly bound the entire industry to NVIDIA was their CUDA software ecosystem. This is not just a set of drivers; it's an entire world of optimized libraries (cuDNN, TensorRT) that has become as familiar to AI developers as oxygen. NVIDIA built not just a castle; they dug a deep moat around it with crocodiles, and the name of this moat is CUDA. And anyone who challenges the empire today must storm not only the fortress of hardware but also this almost insurmountable software moat.
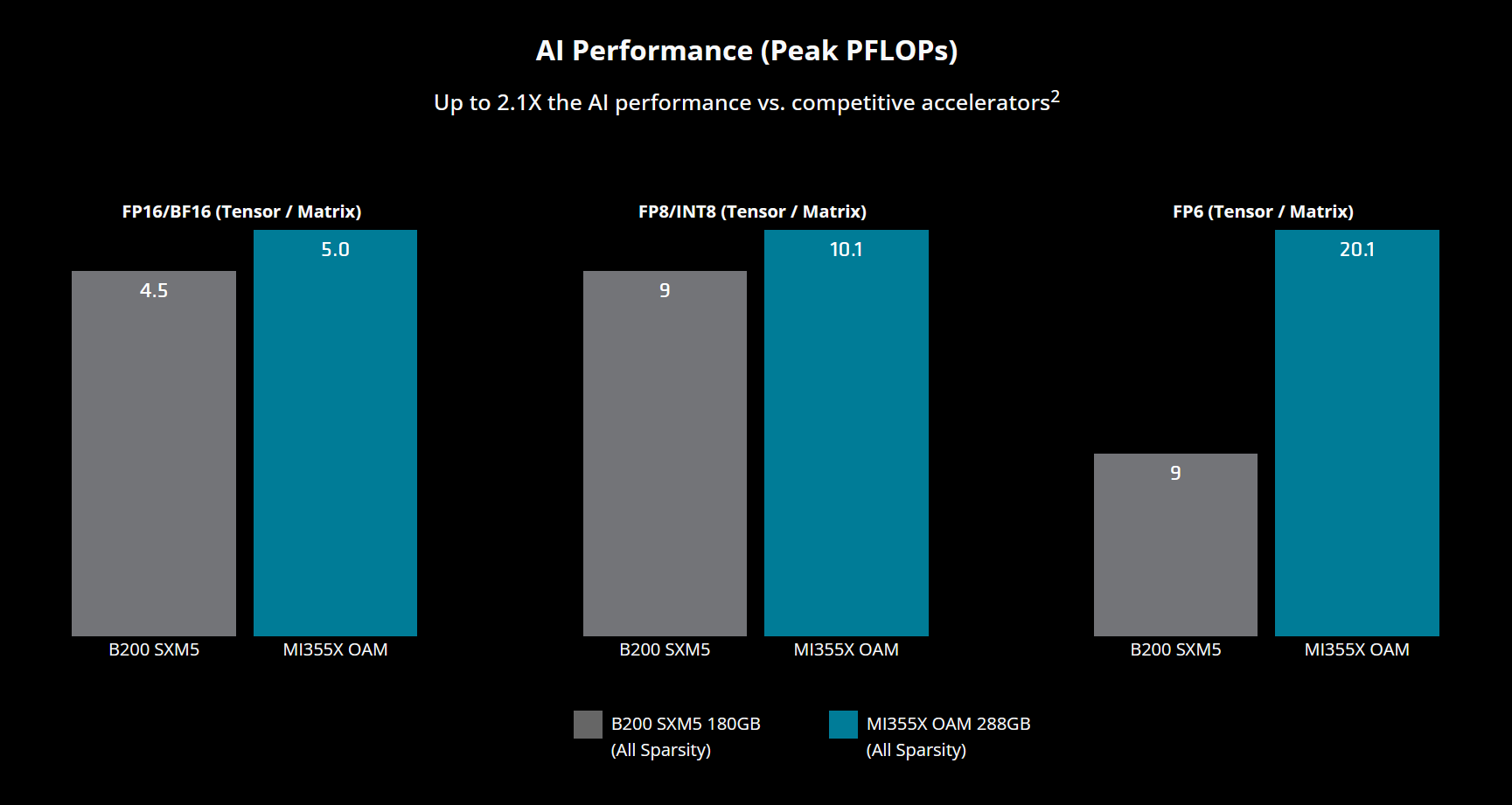
And the first head-on attack on this fortress comes from its eternal rival – AMD. In 2025, this battle reached its climax with the release of the MI350X accelerator on the new CDNA 4 architecture. AMD strikes at the competitor's sorest spot, betting on superiority in key characteristics: the MI350X carries 288 GB of HBM3E memory onboard, significantly exceeding the 180 GB of the Blackwell B200. These are not just numbers – this is the ability to host gigantic models on a single accelerator, and AMD claims up to 30% superiority in inference tasks. However, the real news is that AMD seems to be finally getting rid of its Achilles' heel. Their historically weak point, the ROCm software stack, has always been the very reason why developers, even looking at the impressive hardware specifications from AMD, were in no hurry to leave the convenient and predictable "golden cage" of CUDA. But with version 7.0 and the integration of universal tools like Triton, ROCm is for the first time beginning to transform from a "perpetually catching up" into a real, competitive alternative, offering the market not only powerful silicon but also an improved "tokens per dollar" ratio.
A head-on attack is not the only way to wage war. Other companies have chosen asymmetric strategies, creating highly specialized tools for specific tasks on three main fronts.
The Battle for Latency
Here, the main rebel is Groq with its Language Processing Unit (LPU). Their philosophy is a direct challenge to the chaos of thousands of GPU cores. Groq argues that for real-time applications, such as live dialogue with AI, it's not peak throughput that matters as much as determinism and predictability. When you talk to an assistant, a painful half-second pause kills the entire experience. GPU architecture, with its complex schedulers and resource contention, is inherently unpredictable.
The LPU is an anti-GPU. Instead of thousands of small cores, it has one huge, but completely manageable, core. Every operation, every data movement is pre-planned by the compiler. This is like the difference between a busy intersection during rush hour and a perfectly synchronized factory conveyor belt. The result is stable, repeatable, and ultra-low latency. Groq doesn't try to outperform NVIDIA in training giant models; they've created a scalpel for one specific operation – instant inference.
The Battle for Scale
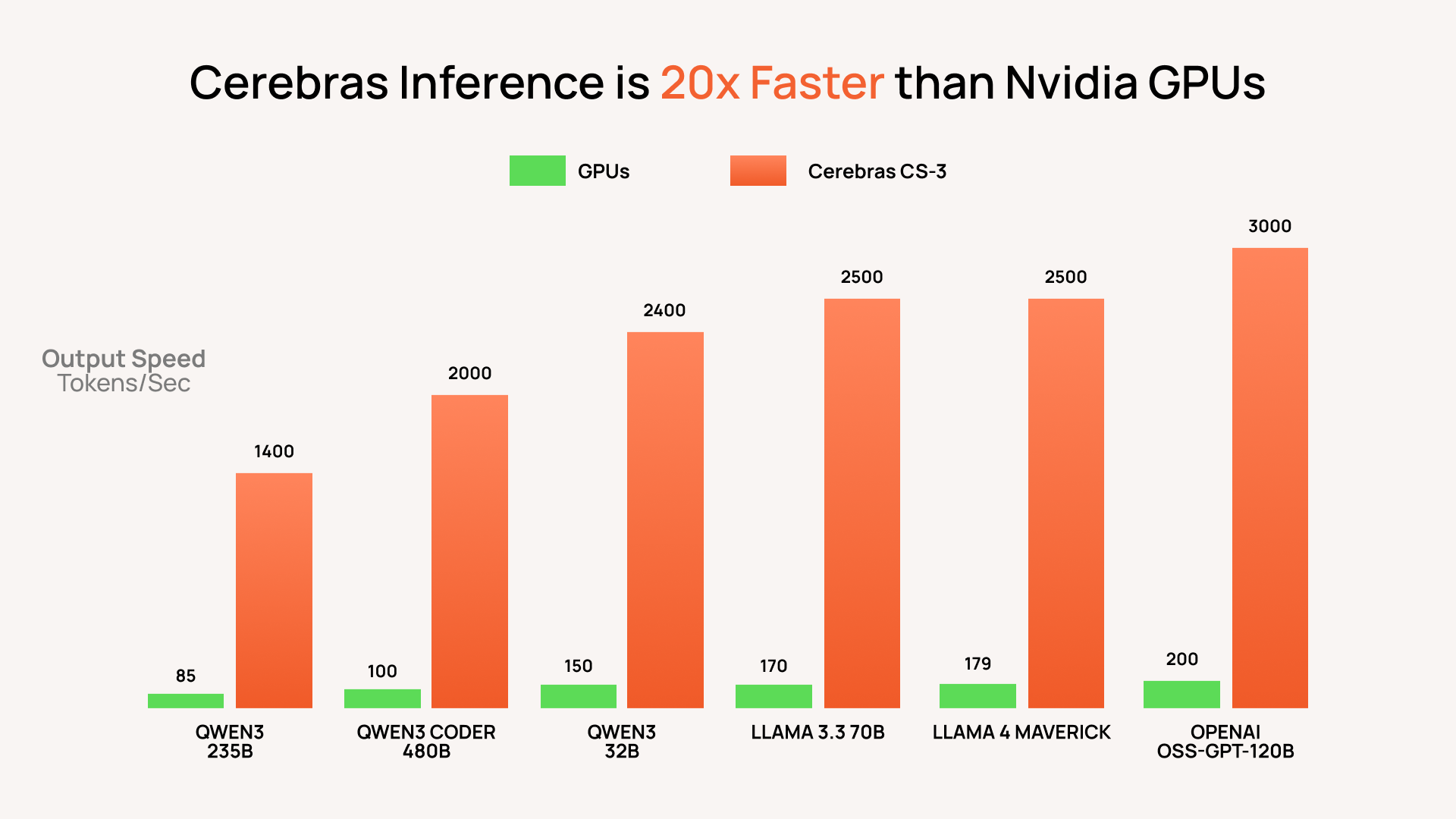
On this front, a titan named Cerebras is fighting. If Groq is a surgeon, Cerebras is an engineer building a space elevator. Their enemy is not the speed of computation on a single chip, but the latency of data exchange between chips. Anyone who has built a large GPU cluster knows that the biggest bottleneck is the interconnections.
Cerebras's solution is both insane and brilliant: eliminate connections by placing the entire computer on a single giant silicon wafer. Their Wafer-Scale Engine 3 (WSE-3) chip is a monster with 4 trillion transistors and 900,000 AI cores. This allows entire neural network layers to be loaded onto a single die, eliminating the need for slow data exchange between thousands of individual GPUs. Their partnership with Meta to support Llama and recent claims that their CS-3 system outperforms NVIDIA Blackwell in inferencing gigantic models demonstrate the seriousness of their ambitions. Cerebras is creating a scalpel the size of a sword, designed to dissect the largest and most complex models that exist.
The Battle for Efficiency
The third front is the quietest, but perhaps the most important. This is the battle for Edge AI. Here, the goal is not maximum performance, but maximum energy efficiency per watt. This is about creating small, cool, and inexpensive "brains" for the billions of devices around us: from factory cameras to your smartphone. Companies like Google (Coral Dev Board), Qualcomm, and Hailo are creating chips that consume only a few watts. Their philosophy is not to drag gigabytes of data to the cloud to a huge AI, but to bring a tiny, yet smart enough, AI directly to the data source. This is not just an engineering compromise; it is a fundamental shift in architecture, dictated by the laws of physics and economics for the world of the Internet of Things.
To better understand the alignment of forces on this new battlefield, let's look at the map.


Corporate "Fortresses": Google, Amazon, and Apple
If on the previous fronts we observed the rebellion of external "insurgents" against the NVIDIA empire, now we see something more fundamental – a great schism within the empires themselves. The tech giants, who for a long time were the largest buyers of chips, came to a conclusion that any large consumer eventually reaches: why buy something on the market that you can grow yourself?
Imagine you own a world-class restaurant chain. For a long time, you sourced the best ingredients from the open market. But the market is unstable: prices fluctuate, supplies are disrupted, and your main supplier (NVIDIA) dictates terms to everyone. At some point, you decide that to control quality, reduce costs, and create unique dishes, you need your own farm. You start controlling everything: from seeds and soil to the recipe on the plate. This is exactly what Google, Amazon, and Apple are doing now. They are building their silicon "farms" to stop depending on the external market and create a fully controlled, vertically integrated pipeline from transistor to end-user.
Google's Strategy: A Double Whammy
- Business Model: Google wages war on two fronts – in the cloud (Google Cloud Platform) and in the consumer market (Pixel devices).
- Silicon Strategy: Their approach is a mirror image of their business model. For the cloud war, they have heavy artillery – Ironwood TPU, the seventh generation of their tensor processors, optimized for hyperscale inference. This is their way of telling GCP clients: "You don't have to pay NVIDIA; we have our own, more efficient and cheaper alternative." And for the war in users' pockets, they have Tensor G5, the brain of Pixel smartphones. This chip, designed for local execution of models like Gemini Nano, enables unique AI features directly on the device. These are not just two different chips; it's a unified strategy to seize control of the entire AI ecosystem, from the data center to your smartphone.
Amazon's Strategy: Cold Economic Calculation
- Business Model: Amazon Web Services (AWS) is not just a player in the cloud market; it is the market itself. Their main task is to maintain and expand their dominance.
- Silicon Strategy: Unlike Google, Amazon's strategy is less technological and more economic. By developing their own chips, such as Trainium for training and Inferentia for inference, they create the main leverage in the cloud war – price. By offering their clients (including giants like Anthropic) a more favorable price-performance ratio, they make migration to another platform economically unattractive. This is not so much a race for performance as it is the creation of a "golden cage." AWS is building its silicon farm not for gourmet delights, but to make its "products" the most affordable on the market, thereby displacing competitors.
Apple's Strategy: A Fortress of Privacy
- Business Model: Apple doesn't sell clouds or search queries. They sell premium devices where user experience and privacy are key values.
- Silicon Strategy: Their approach is entirely subservient to this model. All the power of their Neural Engine, which in the A19 Pro chip and the upcoming M5 will become even more advanced, is aimed at one thing – maximum on-device processing. Apple is building its fortress not in the cloud, but right in your iPhone. Why? First, it's privacy, the cornerstone of their brand. Your data never leaves the device. Second, it's user experience. Local processing means instant response and deep integration of AI features without dependence on an internet connection. Apple is not trying to win the race for the biggest AI in the data center; they are winning the race for the smartest, fastest, and most secure AI in your pocket.
This schism is not just technical diversification. It is a fundamental restructuring of the industry. Giants no longer want to be mere "architects" working on someone else's "geology." They themselves are becoming geologists, creating the ideal landscape for their software ambitions and building impenetrable silicon fortresses to protect their business empires.

The Battlefield We Don't See
But if you think these corporate "fortresses" are the biggest schism in the world of technology, then you're looking at the wrong map. The real, tectonic rift doesn't run between Cupertino and Mountain View. It divides superpowers. The real war for the future of AI isn't happening in presentation halls, but in the quiet of government offices, and its weapons are export regulations and sanctions lists.
What we are witnessing is a full-fledged technological siege warfare. The United States is systematically building a "siege wall" around China, seeking to cut it off from supplies of the most advanced weapons of our era. This is not just about ready-made chips, such as the NVIDIA H20, specially created to circumvent restrictions, which still fell under sanctions. Strikes are being made at the very foundation of manufacturing – at lithography machines from companies like ASML, without which it's impossible to create modern semiconductors. The stated goal is to slow down China's technological and military development. The real result is the splitting of the world into two technological universes.
How does China respond to this? A direct assault on the "besieged wall" is not yet possible. Despite giant state investments in companies like SMIC and Huawei, creating a complete analogue of NVIDIA H100 in isolation is a task bordering on fantasy. Therefore, China has resorted to a brilliant asymmetric response. It has shifted the battlefield to where technological walls don't work.
And here we come to the main paradox of this new cold war – the Open-Source Paradox. Over the past year, we have seen Chinese companies and laboratories (Alibaba, DeepSeek, Z.ai) become a dominant force in the world of open-weight models. This is not a coincidence; it is a strategy. The logic of this maneuver is brilliant in its simplicity: "You won't let us build the biggest and most powerful 'battleships' (giant closed models)? Fine. We will flood the global ocean with thousands of fast, maneuverable, and free 'destroyers' (efficient open-source models). Each one may be weaker than your flagship, but together they will win the sympathy of the entire global fleet of developers and make our technologies the new standard."
This geopolitical game ceases to be an abstraction and directly affects each of us. When you, as a developer, today choose between a closed API from an American laboratory and a high-performance open model from Alibaba, your choice is no longer just a technical decision. It is a tiny echo of a large geopolitical struggle. You are voting for one of two emerging ecosystems, willingly or unwillingly taking sides in a battle that is happening on a field we don't even see.

A New Law for the AI Architect
So, what have we arrived at, having journeyed from the monolithic NVIDIA empire to the fragmented but ambitious principalities of Groq, Cerebras, and Big Tech? We have come to a simple but fundamental conclusion: the era when one could ignore "geology" is over. The "ideal marriage" of the Transformer and the GPU, that reliable foundation on which all modern AI skyscrapers have grown, is no longer the only possibility. The era of the universal Swiss Army knife is being replaced by the era of a set of surgical scalpels.
And this is not just my conclusion. It is an objective trend, confirmed by the most convincing of all arguments – the dry language of money. Analysts' forecasts paint a picture of a tectonic shift. The global AI chip market is set to grow from $53 billion in 2024 to an astonishing $296 billion by 2030. But the most interesting thing is not the overall growth, but its structure. The specialized chip (ASIC) segment in 2025 is expected to account for 37% of the data center inference market, directly taking share from general-purpose GPUs. And the quiet front of edge computing will turn into a giant market worth $14.1 billion next year. Investor and strategist money is flowing from generality to specialization.
What does this mean for us, the code architects? It means that our old mental model is outdated. We can no longer think of hardware as something that "just works" somewhere out there in the cloud. The choice of hardware platform ceases to be a question for a DevOps engineer at the last stage of a project. It becomes one of the first and most important architectural decisions. To survive and thrive in this new era, we need a new set of rules.
- Rule #1: Think about hardware on day one, not day last. The choice between inference on a Groq LPU, training on Cerebras, or deploying on an Edge device with a Hailo chip fundamentally changes your model's architecture, your product's economics, and the user experience. This decision needs to be made at the design stage, not at the deployment stage.
- Rule #2: Match the chip to the task, not the task to the chip. The "one size fits all" era is over. If you are creating a conversational assistant where every millisecond of latency matters, your choice is an LPU. If you are training a trillion-parameter model, your path lies with Wafer-Scale architecture. Trying to solve both problems with the same general-purpose GPU means consciously compromising on performance and cost.
- Rule #3: Understand the economics, not just the technology. The choice of hardware platform is primarily an economic decision. How much does a token cost? What is the total cost of ownership (TCO) for your client? How will the chip choice affect power consumption and, consequently, operating costs? In a world where AI becomes a commodity, the one who best calculates unit economics will win. And remember: the echo of the geopolitical battle is now heard in every technical decision. The choice between an open Asian model and a closed American one is no longer just a question of performance, but also a strategic stake in a global game.
The illusion of choice with which we began has indeed ended. But in its place comes not a dictatorship of silicon, but an era of conscious choice. We can no longer afford to be merely architects who do not know the basics of geology. The time has come when the geologist and the architect must learn to speak the same language.
Stay curious.


