Галлюцинации недели: Nemotron 3 Super, DLSS 5 и агент, который заменит вашего маркетолога
Автор: Алексей Бельтюков

У Anthropic новая малышка на миллион. Codex учится делегировать задачи субагентам, Hermes запоминает пользователей, а MCP опять хоронят. Штош..
В Opus 4.6 стало доступно контекстное окно 1M токенов для пользователей на тарифах Max, Team и Enterprise. Убрали дополнительную плату за длинный контекст через API, сняли требование beta-заголовка и подняли лимит до 600 изображений и PDF-страниц за один запрос. Главная цифра: 78.3% на MRCR v2, что на данный момент лучший результат среди всех моделей на длинном контексте. MRCR (Multi-Round Co-reference Resolution) проверяет, может ли модель находить и связывать информацию, разбросанную по огромному контексту. Простыми словами: если вы загрузили в модель 20 документов и спрашиваете про деталь из седьмого, которая связана с фактом из третьего, MRCR измеряет, насколько хорошо модель с этим справится. 78.3% означает, что Opus 4.6 реально работает с миллионом токенов, а не просто принимает их на вход.
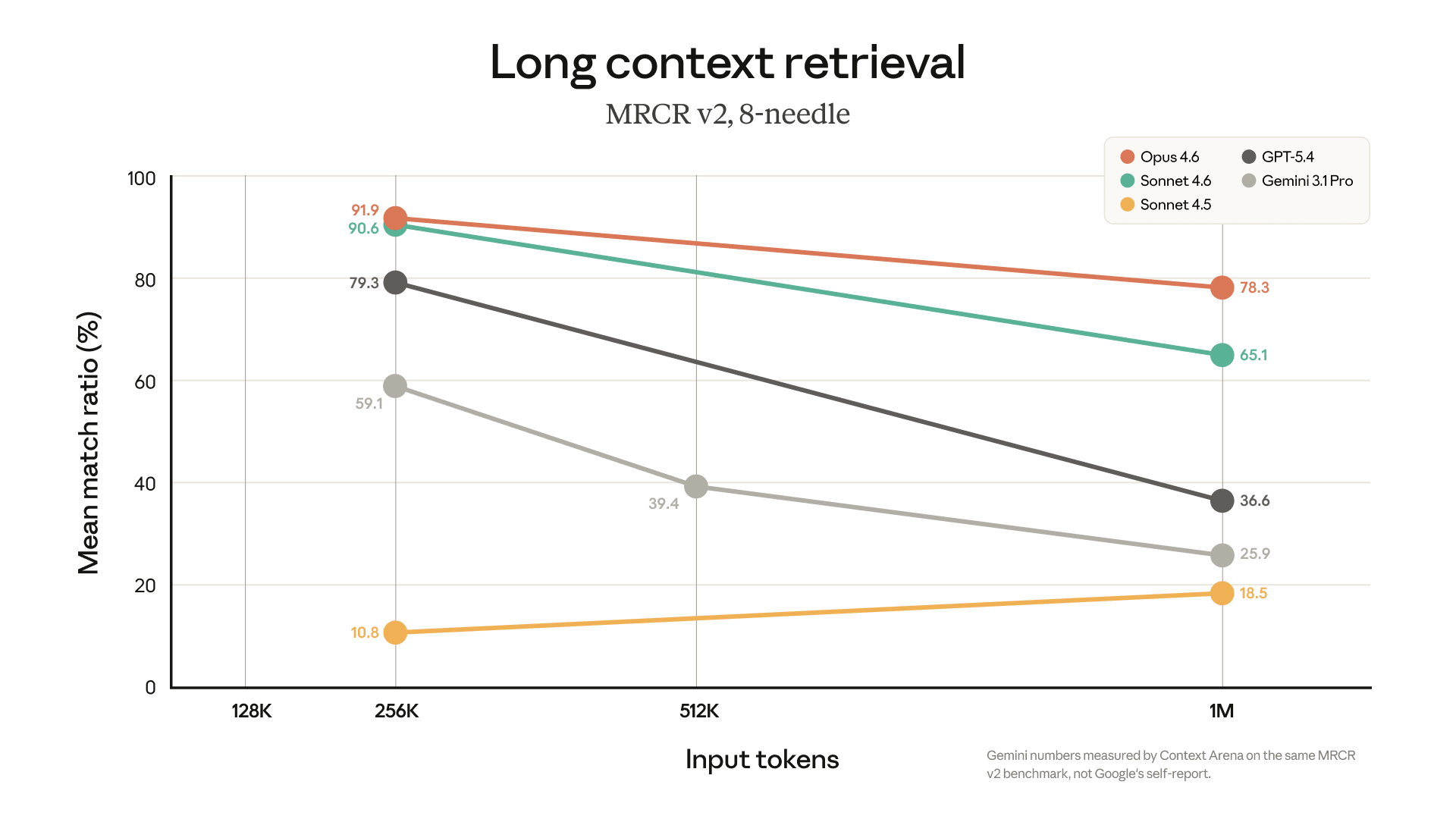
Формально миллион контекста нам доступен уже больше года в моделях Gemini. На прошлой неделе OpenAI сделали то же самое для GPT-5.4 за дополнительную плату. Но есть нюанс: бенчмарки показывают, что модели начинают заметно деградировать после условных 256K и особенно после 512K токенов. Именно поэтому такой показатель на MRCR v2 важнее самой цифры "1M": он отражает качество работы на всём доступном контексте, а не размер входного окна. Как эти флагманы соотносятся по качеству длинного контекста и другим осям — я разбирал в обзоре GPT-5, Gemini, Claude и Grok.
Контекстная гигиена никуда не уходит. Даже с миллионом токенов в окне стоит продолжать следить за тем, сколько данных вы передаёте в модель и насколько они релевантны задаче.
До 28 марта у Anthropic действует промо с удвоенными лимитами в нерабочие часы. Работает на Free, Pro, Max и Team (Enterprise не участвует), распространяется на Claude, Cowork, Claude Code и плагины для Excel/PowerPoint. Пиковые часы, когда лимиты обычные: 15:00–21:00 по Москве в будни. Всё остальное время, включая выходные, лимиты x2, и дополнительное использование не считается в недельную квоту. Активируется автоматически, ничего делать не нужно. Проверить текущий статус в вашей таймзоне можно здесь.
Дженсен Хуанг, глава Nvidia, в своей классной куртке отработал свои фирменные два часа без телесуфлёра на GTC и выдал главный тезис года: центр тяжести сместился с обучения на инференс. Слово "inference inflection point" звучало из каждого второго твита после доклада.
Из интересного: анонс CPU Vera для серверных платформ, бэклог заказов на $1T к 2027 году (хотя тут нужна бухгалтерия), и NemoClaw, форк OpenClaw с акцентом на безопасность. Дженсен долго хвалил OpenClaw, а потом аккуратно указал на проблемы с безопасностью и предложил своё решение.
DGX Station тоже показали, настольный AI-суперкомпьютер на чипе GB300 Grace Blackwell Ultra. 748 ГБ когерентной памяти, до 20 петафлопс AI-производительности, связь CPU-GPU через NVLink-C2C на 1.8 ТБ/с (в семь раз быстрее PCIe Gen 6). NVIDIA говорит, что на нём можно запускать модели до триллиона параметров без облака. Если вам интереснее земной сценарий — запустить LLM на своём железе без DGX — я написал практическое руководство по локальному запуску. Машина работает и как персональный суперкомпьютер, и как общий вычислительный узел для команд, поддерживает изолированные конфигурации для регулируемых отраслей. Весной начнут продавать через ASUS, Dell, GIGABYTE, HP, MSI и других. Это уже не "GPU для энтузиастов", а полноценная инфраструктура для локальной разработки агентов, и Дженсен явно позиционирует DGX Station + NemoClaw как платформу для автономных агентов, которые думают, планируют и работают непрерывно.
На стороне графония DLSS 5 вызвал больше всего эмоций, а Хуанг назвал его "GPT-моментом для графики". Что это такое: модель берёт цвет и векторы движения из каждого кадра, понимает семантику сцены (персонажи, волосы, ткань, кожа, условия освещения) и генерирует визуально точный результат с корректным подповерхностным рассеиванием, бликами на ткани и взаимодействием света с материалами. Всё это в реальном времени, до 4K, с покадровой стабильностью (критично для игр). Разработчики могут тонко настраивать интенсивность, цветокоррекцию и маскировать отдельные объекты. А нам, геймерам, остаётся наслаждаться аниме-девочками и мемами.
Важный нюанс: на демо использовали две RTX 5090, одну для игры, вторую целиком под DLSS 5. NVIDIA говорит, что к запуску осенью оптимизируют под одну GPU. Но сам подход показателен: рендеринг перестаёт быть чисто растеризационной задачей и становится нейронной генерацией, привязанной к 3D-геометрии. Если DLSS 4 рисовал нам кадры, то DLSS 5 улучшает визуальное качество. Это тот же тренд, что и во всём остальном AI: модели перестают "помогать" и начинают "делать".


А за пару дней до GTC NVIDIA выпустила Nemotron 3 Super, и это модель, на которую стоит обратить внимание. 120B параметров, из которых активны только ~12B, гибридная архитектура Mamba-Transformer с SSM Latent MoE, контекст на миллион токенов. Главное отличие от других open weight моделей: NVIDIA опубликовала не только веса, но и рецепт обучения, данные и детали инфраструктуры. Параллельно вышел Nemotron 3 Nano 4B — edge-модель на той же гибридной архитектуре Mamba2-Transformer с контекстом 262K, сжатая из 9B через Nemotron Elastic. Предназначена для запуска на Jetson Thor, GeForce RTX и DGX Spark, умеет переключаться между режимом с reasoning и без него через системный промпт. Вот GGUF от нашего брата unsloth: Nano 4B и Super 120B.
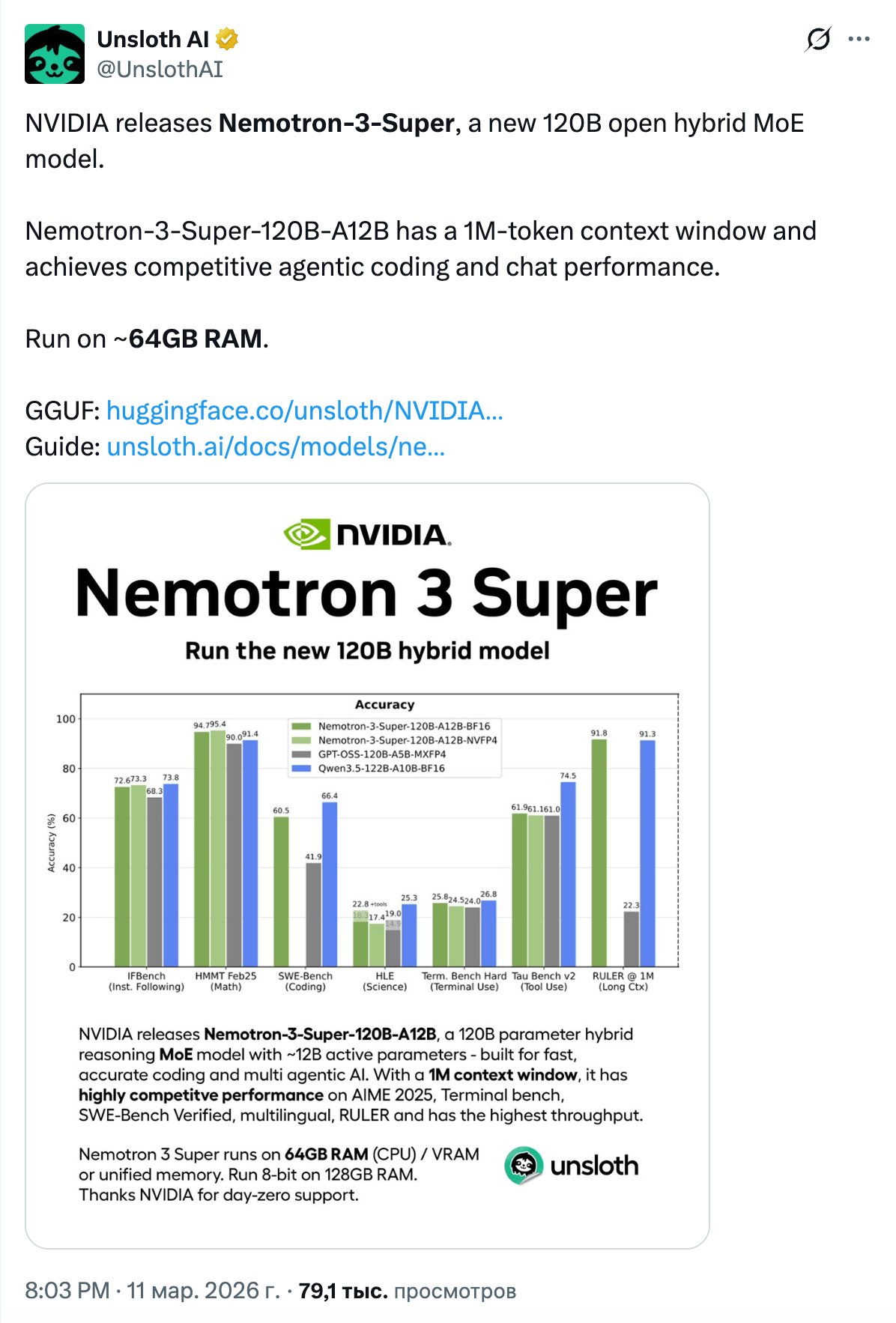
По производительности Artificial Analysis поставил 36 на своём Intelligence Index (gpt-oss-120b набрал 33, Qwen3.5-122B-A10B всё ещё впереди с 42), но скорость инференса выше на ~10% при тех же GPU. Ключевая фишка, multi-token prediction: модель генерирует несколько токенов за раз и верифицирует на следующем проходе. Плюс значительно меньший KV-cache по сравнению с Qwen3.5-122B: ~8,192 байт/токен против 24,576 у Qwen в BF16.
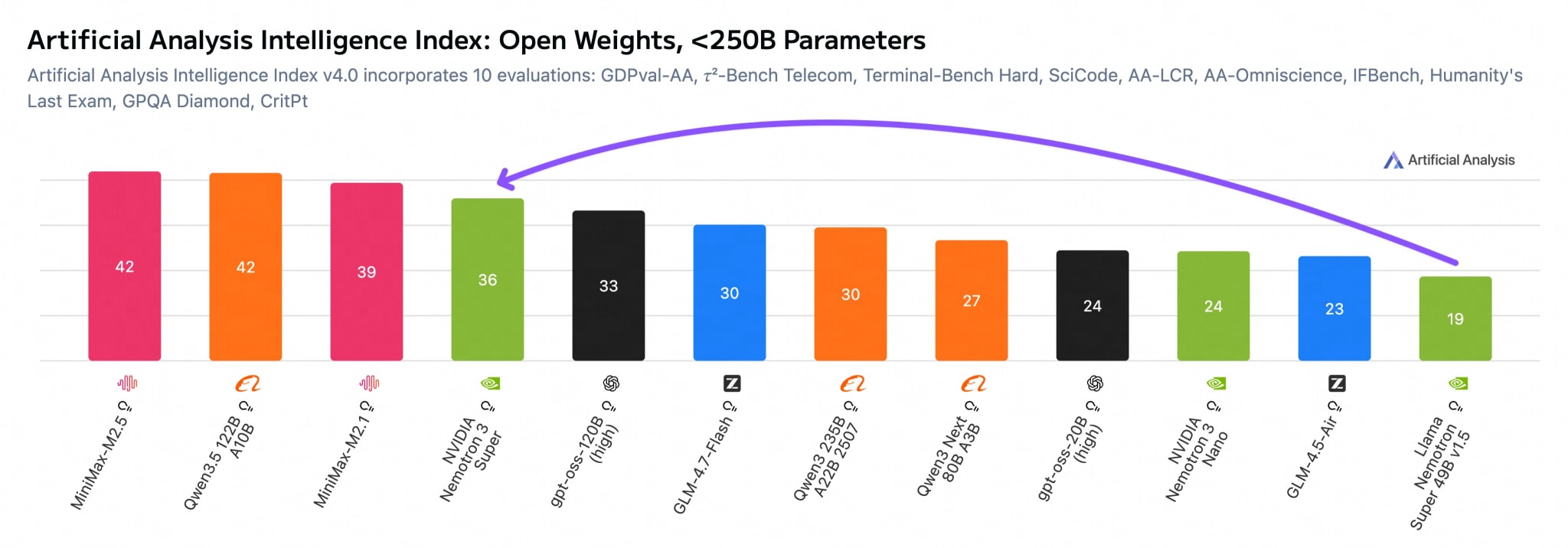
Экосистемная поддержка прилетела в день запуска: vLLM, llama.cpp, Ollama, Unsloth. NVIDIA обновила лицензию, убрав спорные пункты про guardrails и брендинг, что делает модель реально свободной для модификации.
Moonshot (создатели Kimi) представили Attention Residuals, замену классического фиксированного residual connection на attention по предыдущим слоям. Идея: вместо того чтобы просто складывать выход слоя с его входом (как делают все трансформеры с 2017 года), модель учится динамически взвешивать информацию из всех предыдущих слоёв. Добавили Block AttnRes, чтобы это не убивало производительность на больших моделях. Ссылка для любителей почитать.
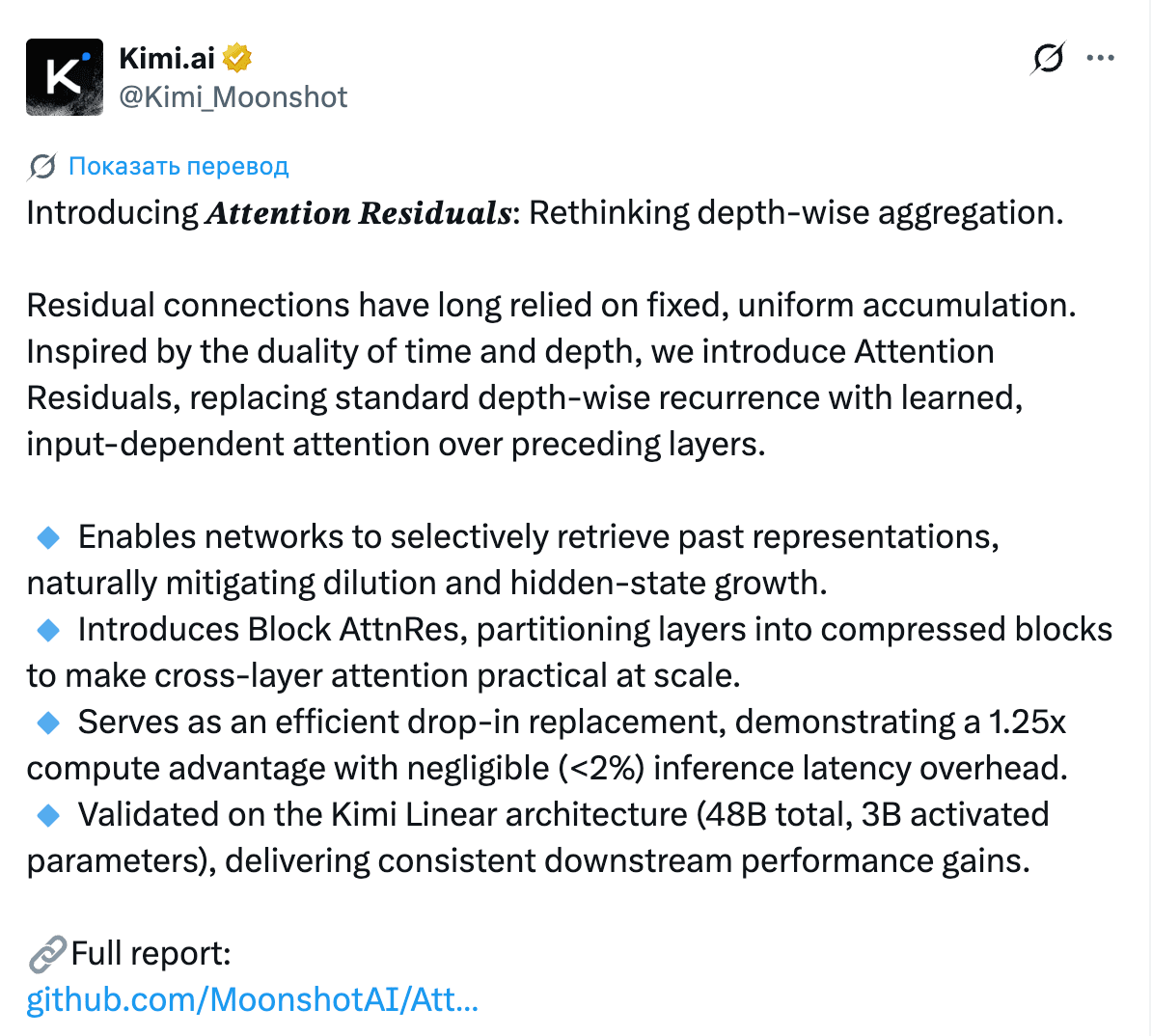
Результаты: 1.25x вычислительное преимущество (то есть модель с AttnRes догоняет стандартную модель с 1.25x бюджетом вычислений), менее 2% накладных расходов на инференсе. Проверили на Kimi Linear 48B / 3B active. Реакция была бурной: от Yuchen Jin до Илона Маска.
Не всем твиттерским это понравилось. Раз и Два. Эта дискуссия сама по себе интересна как пример напряжения в ML-сообществе между "кто первый придумал" и "кто первый заставил работать".
Codex добавил субагентов: теперь внутри одной сессии можно запускать дочерние агенты для параллельных задач. Это финально закрепляет переход от "copilot, который дописывает строку" к мультиагентному рабочему процессу, где один агент пишет код, другой тестирует, третий ревьюит, четвёртый деплоит.
Инфраструктурный слой вокруг агентов для кода тоже зреет быстро. Andrew Ng расширил Context Hub (chub), open CLI для актуальной документации API с поддержкой циклов обратной связи от агентов. AssemblyAI выпустил свой скилл для Claude Code, Codex и Cursor. Появилась работа по автоматическому извлечению скиллов из GitHub-репозиториев в формат SKILL.md с заявленным приростом 40% в передаче знаний. Формируется новый стек: skills-файлы, актуальные доки, каналы обратной связи, процедурные знания из репозиториев.
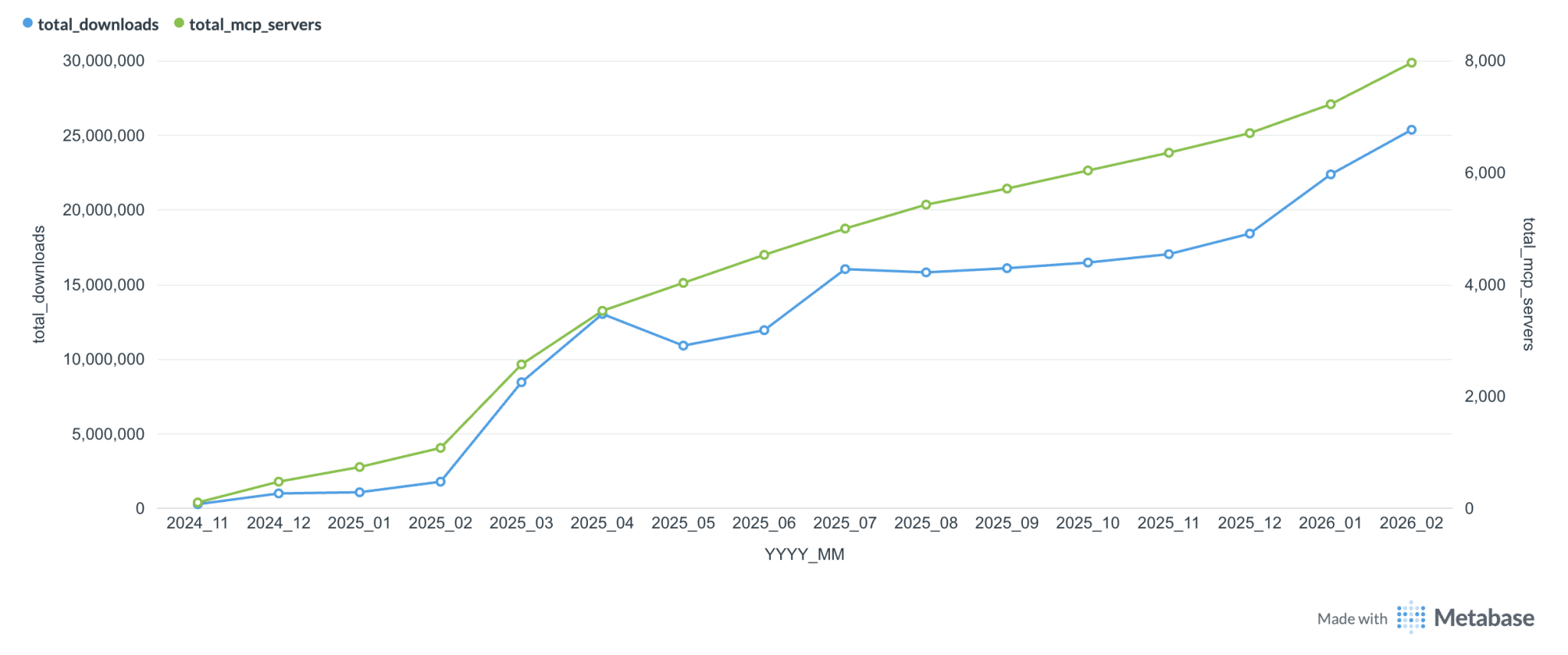
А вот MCP на этой неделе пережил мини-кризис идентичности, его опять хоронят. Издревле существует шутка, что разработчиков MCP серверов больше, чем пользователей. Но, судя по графику использование растёт. Я лично использую только один MCP-сервер, ExaMCP. Раньше пользовался ещё context7, но и он теперь доступен в cli.
Самый содержательный разбор дал LlamaIndex: MCP tools хорошо работают, когда нужны детерминированные, централизованно поддерживаемые API с быстро меняющимися данными. Skills (лёгкие локальные процедуры на естественном языке) проще, но менее надёжны. Нужно правильно выбирать инструмент под задачу.
Параллельно появилась поддержка Web MCP в Chrome v146, с демо LangChain Deep Agent, который непрерывно мониторит X и компилирует ежедневную сводку. MCP точно не мёртв. Но хайп прошёл, и люди начинают разбираться, где он реально нужен, а где проще написать обычный скрипт.
Hermes Agent от Nous Research провёл хакатон, и проекты получились разношёрстные: автоматизация домашнего медиасервера для аниме, кибербезопасность, OSINT-прогнозирование, визуализация исследований. Участники пишут, что Hermes проще настроить и он стабильнее в работе, чем OpenClaw.
Что выделяет Hermes на фоне остальных: постоянная память через Honcho. Агент накапливает знания о пользователе и улучшается со временем, а не забывает всё после выполнения задачи. IBM на этой неделе опубликовал работу, в которой рассматривает память мультиагентных систем как задачу компьютерной архитектуры: кеш-иерархия, когерентность, контроль доступа. Это перекликается с тем, что делает Hermes на практике.
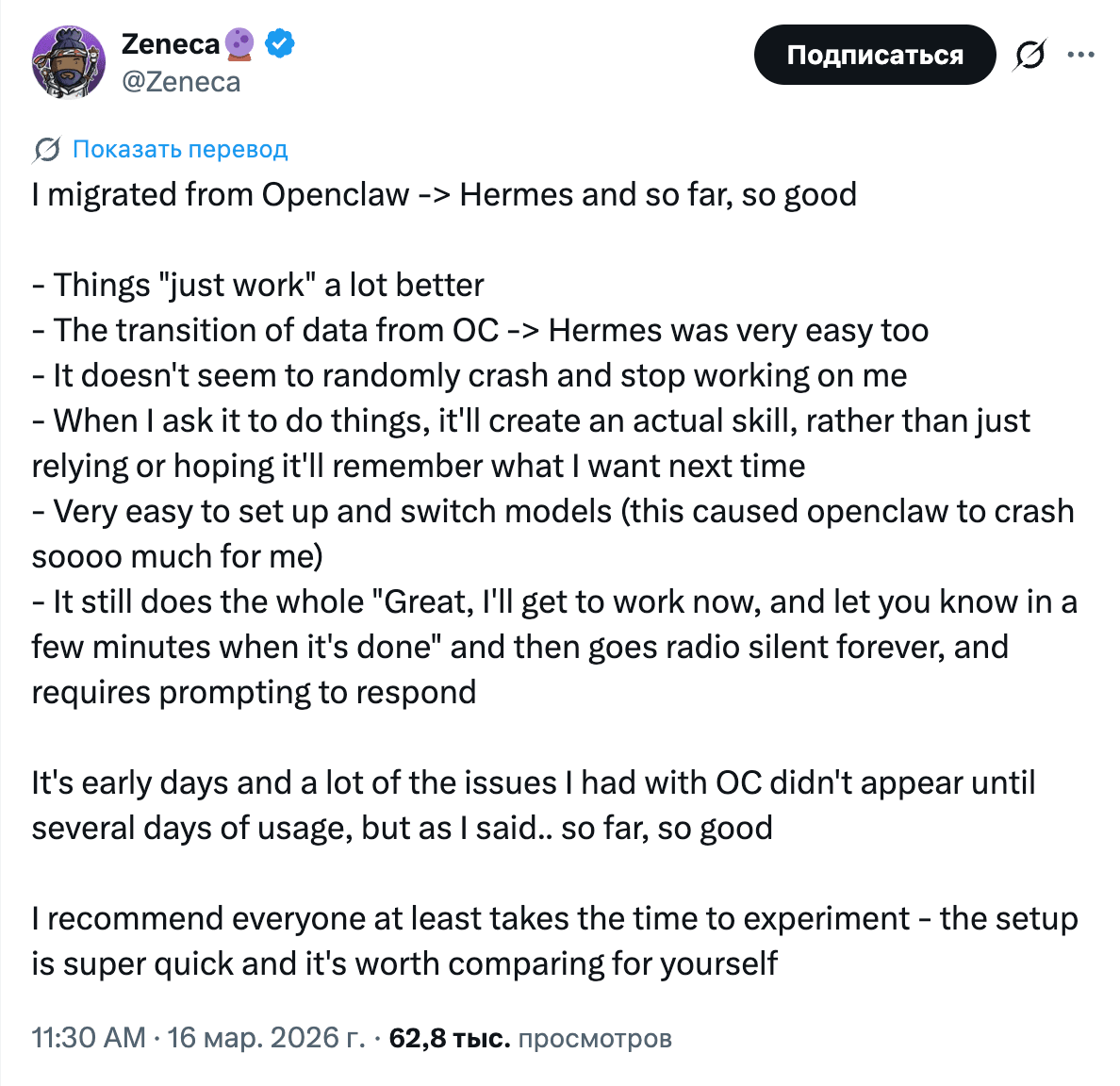
При этом OpenClaw не стоит на месте. Ollama стал официальным провайдером, Comet запустил observability-плагин для трассировки вызовов и стоимости. Вокруг обоих проектов формируется экосистема с провайдерами, memory-бэкендами, трассировкой и хакатон-расширениями.
Сингапурский стартап Okara запустил AI CMO, маркетингового агента для стартапов. Вводишь URL сайта, и система разворачивает команду специализированных субагентов: SEO-аудит, GEO (Generative Engine Optimization), контент, Reddit, Hacker News, X. SEO-агент проверяет сайт ежедневно и присылает конкретные фиксы на почту каждое утро. Стоит $99/мес.
Твит с анонсом собрал 5.3 миллиона просмотров за 4 часа. Целевая аудитория понятная: инди-разработчики и bootstrap-команды, у которых есть продукт, но нет маркетингового бюджета. Okara считает, что заменяет $50-168K в год на найм контент-райтера, SEO-агентства, SMM-менеджера и комьюнити-менеджера.
Cам факт показателен: мультиагентный паттерн (один оркестратор + команда специализированных субагентов) перестал быть прерогативой инструментов для кода и пришёл в маркетинг. Codex добавляет субагентов для кода, Okara делает то же самое для growth. Вопрос, как всегда, в исполнении.
Кстати, про контекстную гигиену. Даже с малышкой на миллион не забывайте фильтровать то, что в неё грузите. А если на этой неделе есть время попробовать только одну вещь, засядьте на все выходные с Claude Code, пока промо действует.
Оставайтесь любопытными.