Галлюцинации недели: GPT-5.4, MacBook на M5 Max и 630 строк, которые автоматизируют ML-ресёрч
Автор: Алексей Бельтюков
Очередной флагман от OpenAI с миллионным контекстом, Claude делает code review, Google обновляет свою быструю малютку, новый MacBook для локального инференса. А что Титов?
OpenAI выпустил GPT-5.4 и GPT-5.4 Pro одновременно, что для них нетипично, обычно Pro-версия появляется через пару недель. Это первая модель семейства 5.x, которая объединяет код и интеллектуальные задачи в одном месте. Контекст до 1M токенов, нативный computer use.
Чтобы активировать 1M контекстное окно в Codex, надо прописать в config.toml:
model = "gpt-5.4"
model_context_window = 1000000
model_auto_compact_token_limit = 900000
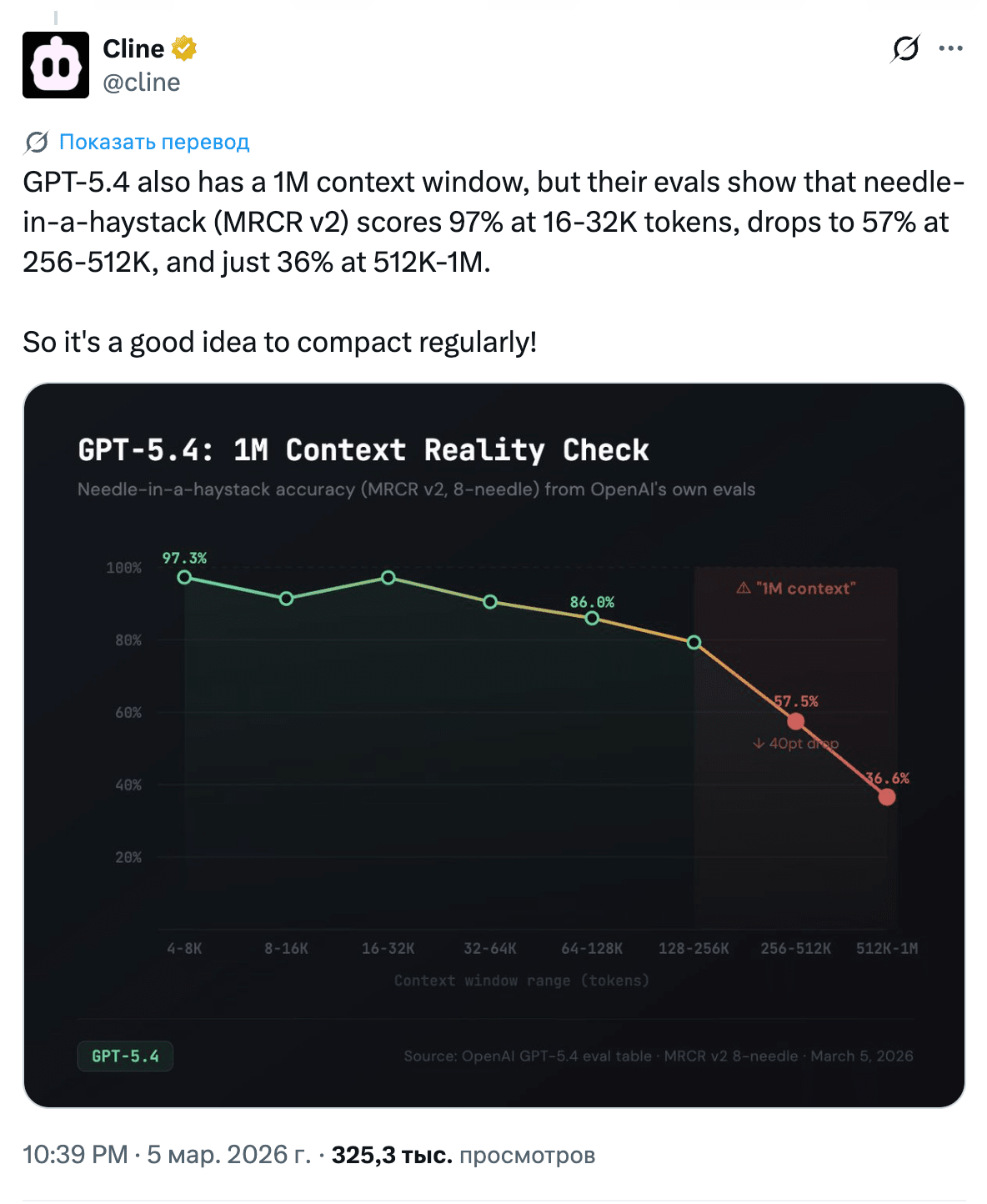
Но есть нюансы. Контекст в миллион токенов не означает миллион полезных токенов: на 16-32K точность ~97%, на 256-512K падает до 57%, а на 512K-1M уже 36% (источник). Плюс к этому, в Codex после 272K потребление увеличится вдвое. То есть реальный потолок так и остаётся где-то в районе 256K.
Я последний месяц 80% кода пишу с помощью 5.3-Codex, и 5.4 ощущается как логичное продолжение. Следование инструкциям заметно подтянули, код читается естественнее. Ожидаю, что в дизайне/фронтенде она стала получше, но я такие задачи поручаю Opus 4.6. В Codex также появился режим /fast, дающий до 1.5x ускорение генерации в обмен на двойное потребление. Если интересно, где 5.4 встаёт среди других флагманов, я разбирал это в полном сравнении флагманских моделей 2025.
Наконец-то выпустили Codex для Windows с нативным sandbox на уровне ОС (ACL, restricted tokens, выделенные пользователи). Поддержка PowerShell, CMD, Git Bash, WSL. Плюс запустили программу Codex for Open Source: мейнтейнерам крупных проектов дают полгода ChatGPT Pro с Codex, доступ к Codex Security и API-кредиты на автоматизацию ревью и релизов. У Anthropic аналогичная программа: 6 месяцев Claude Max 20x для мейнтейнеров репозиториев с 5000+ звёзд или 1M+ скачиваний в NPM.
И бонус: за неделю OpenAI сбросили лимиты в Codex раза 3-4, каждый раз объясняя это найденным багом. В сообществе это уже стало мемом.

Anthropic запустил Claude Code Review, мультиагентную систему, где параллельные агенты ищут проблемы, верифицируют находки и ранжируют по серьёзности. Внутренние метрики: доля PR с осмысленными комментариями выросла с 16% до 54%, при этом менее 1% находок оказались ошибочными. И тут же в треде Anthropic написали, что одно ревью стоит примерно $15-25.
Индустрия пришла к консенсусу: проблема генерации кода решена, узкое горлышко теперь в верификации. Двухагентная архитектура "генератор + ревьюер" становится стандартом, как юнит-тесты когда-то.
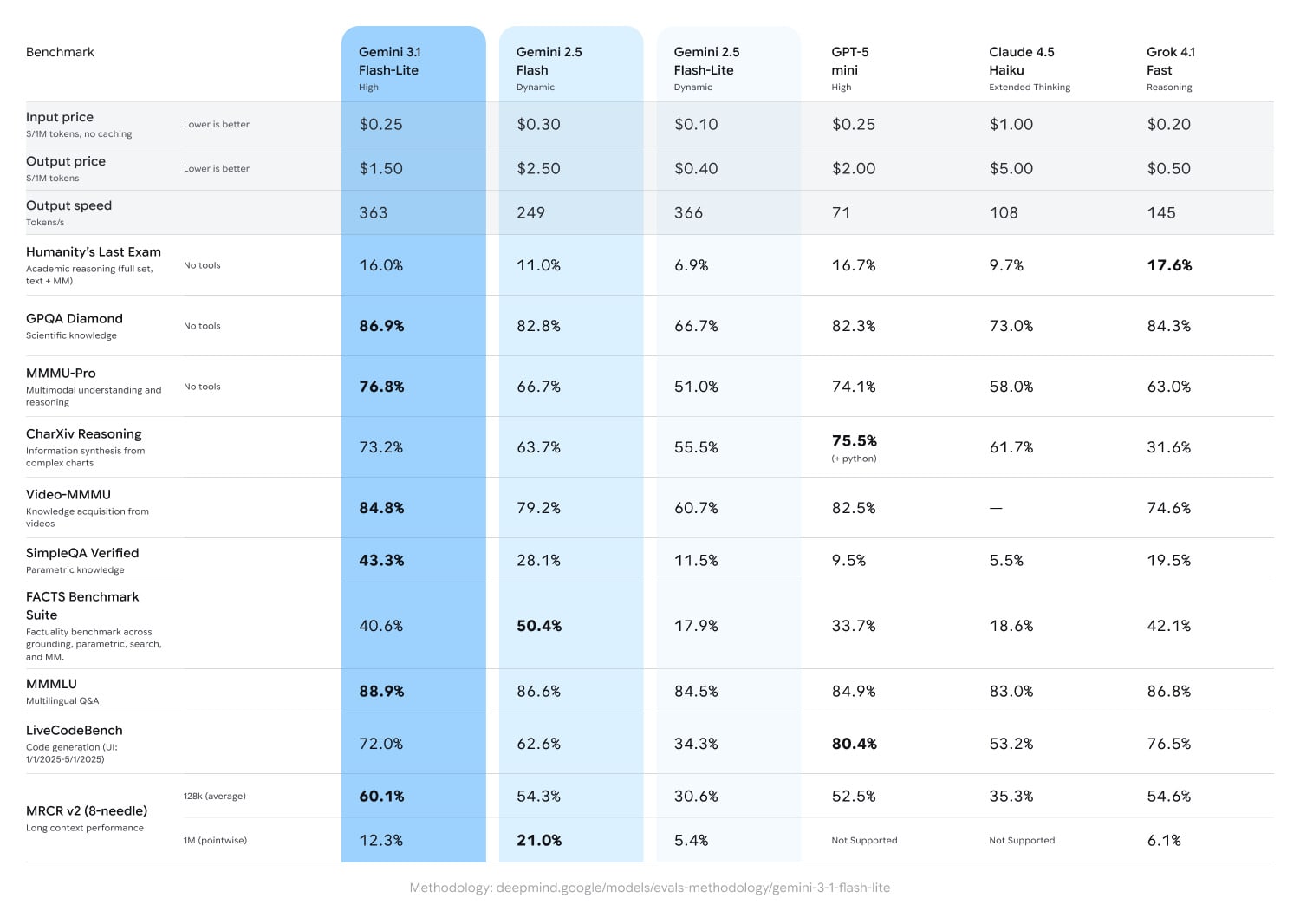
Google выкатил Gemini 3.1 Flash-Lite. Регулируемый thinking level, где ты сам выбираешь баланс между интеллектом и скоростью. Заявлено больше 360 tok/sec и миллионный контекст. Да, стало дороже по сравнению с предшественником Gemini 2.5 Flash-Lite: $0.25/$1.50 за миллион токенов. Google не пытается конкурировать с флагманами, в собственных бенчмарках модель сравнивают с GPT-5 mini и Claude Haiku, а не с Opus или GPT-5.4. Это рабочая лошадка для пайплайнов: мультимодальный ввод (текст, картинки, видео, аудио, PDF) на высокой скорости вместо самописных парсеров. Я с удовольствием переключил на новую модель свой суммаризатор и переводчик.
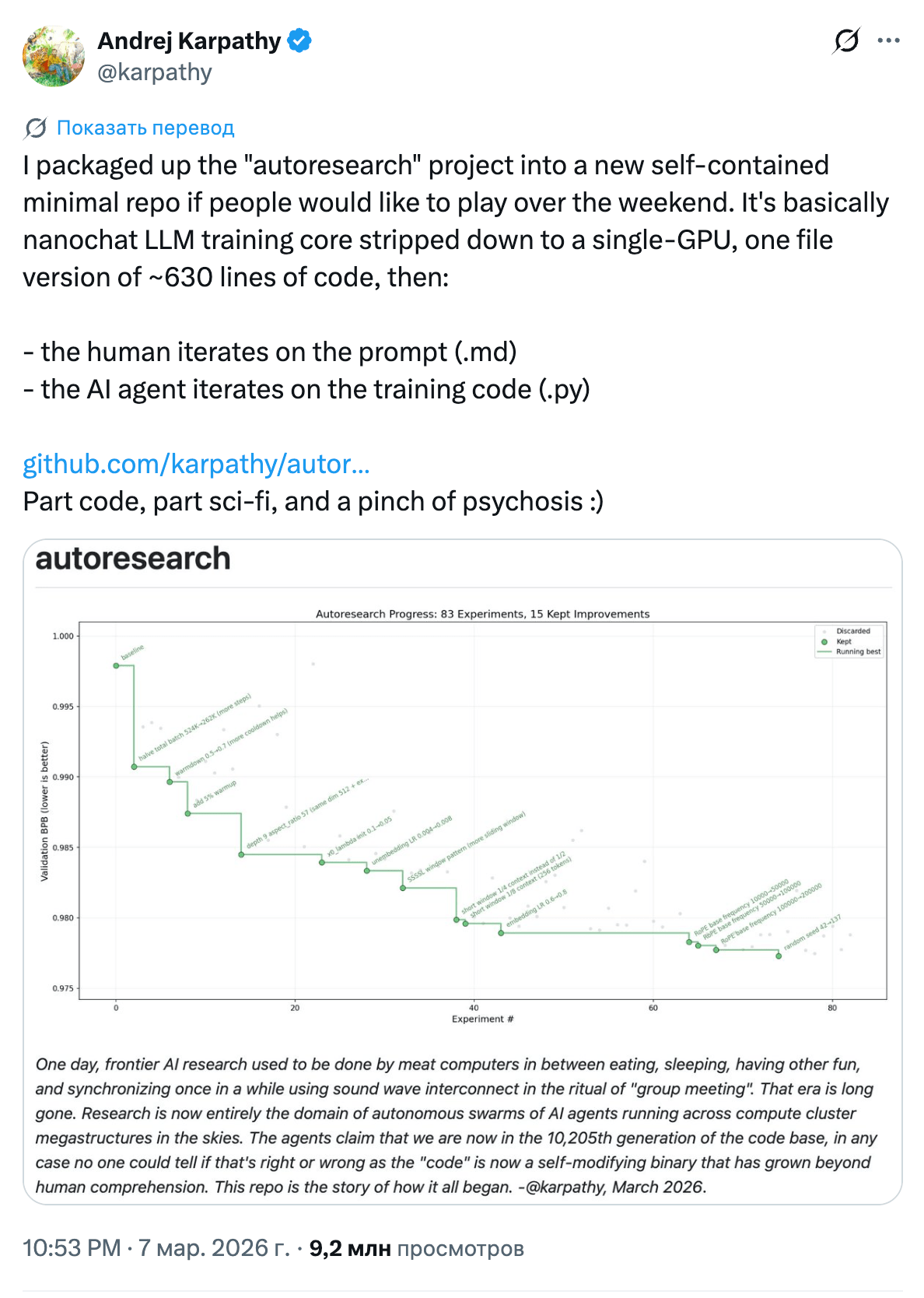
Андрей Карпаты выложил autoresearch, репозиторий на ~630 строк. Идея простая: AI-агент в цикле сам меняет параметры, запускает эксперимент, смотрит на результат и пробует снова, без участия человека. За ~700 таких итераций агент нашёл 20 улучшений, которые сократили время обучения GPT-2 на 11%. И улучшения переносятся на модели побольше. Ещё в декабре 2025-го Yi Tay ввёл в оборот термин vibe training для подобного подхода: ты не смотришь, что агент меняет, просто проверяешь метрики. Autoresearch, по сути, первая рабочая реализация этой идеи.
Применяют autoresearch уже не только для обучения: CEO Shopify адаптировал фреймворк для своего проекта qmd, прогнал 37 экспериментов за ночь и получил 19% улучшение на модели 0.8B. Сам Карпаты говорит о следующем шаге: распределённые исследования в стиле SETI@home. Кстати, GPT-5.4 xhigh проигрывает Opus 4.6, который спокойно крутит 118 экспериментов за 12+ часов. Проблема подтверждена автором.
Про модели Qwen 3.5 я рассказывал на прошлой неделе, 9B всё ещё трудится на моей машинке. Но на этой неделе важнее другое: команду покинул технический лидер, а за ним ещё несколько ключевых людей, включая Hui Binyuan (lead Qwen Code), который ушёл в Meta. На замену Alibaba наняла Zhou Hao из Google DeepMind. CEO Alibaba Cloud пообещал продолжить open source стратегию, но когда уходят люди, обещания стоят дешевле кода.
Apple представила новые MacBook на M5 Pro и M5 Max. M5 Pro: до 64GB единой памяти, 307GB/s пропускной способности памяти. M5 Max: до 128GB, 614GB/s. SSD до 14.5GB/s (вдвое быстрее M4). Главная цифра для нас: обработка промптов LLM до 4x быстрее M4. Для тех, кто гоняет модели локально, это самое значимое обновление года.
Tri Dao выпустил FlashAttention-4, который достигает скорости attention на уровне matmul на Blackwell. Написан на CuTeDSL (встроенный в Python), компилируется за секунды вместо минут. PyTorch интегрировал FA4 в FlexAttention с ускорением 1.2x-3.2x на вычислительно-ограниченных нагрузках. Ссылка для любителей вчитаться в бумаги.
А vLLM выкатил v0.17 с поддержкой FA4, Qwen3.5 GDN, 5.8x ускорением attention на MI300 благодаря новому Triton-бэкенду, и, что интересно, работой на NVIDIA Jetson без облачных API. Локальный инференс без облака это уже не фантазия.
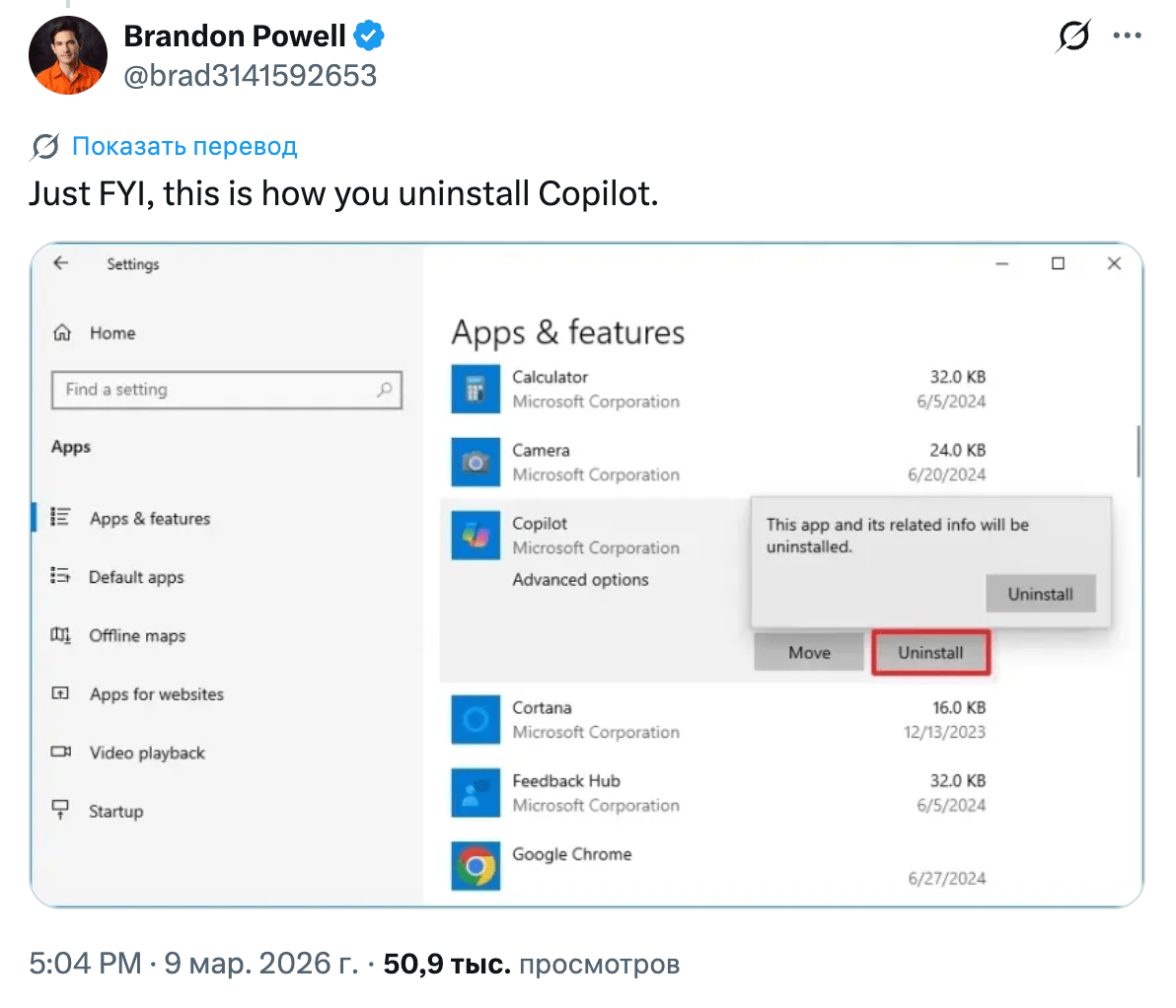
Релиз, который зацепил реакцией сообщества: Microsoft Copilot Cowork. В релизе на сайте написано: "Тесно сотрудничая с Anthropic, мы интегрировали технологию Claude Cowork в Microsoft 365 Copilot". Так вы же вроде с OpenAI в десна целовались?
В треде с анонсом сразу видно, как пользователи относятся к Copilot.
Арифметика на закуску. На странице Codex видно 5-часовые лимиты GPT-5.4 (недельные OpenAI не раскрывает):
┌─────────┬─────────────────┬───────────┐
│ Вариант │ Лимит сообщений │ Стоимость │
├─────────┼─────────────────┼───────────┤
│ 1× Pro │ 223–1120 │ $200/мес │
├─────────┼─────────────────┼───────────┤
│ 7× Plus │ 231–1176 │ $140/мес │
└─────────┴─────────────────┴───────────┘
Если пользуетесь Codex, можно сэкономить $60. Вот ссылка как это реализовать.
Думайте. И оставайтесь любопытными.