Сначала был кремний: Почему архитектура чипов, а не код, определяет будущее AI

Мы, разработчики и AI-энтузиасты, обожаем спорить о выборе. PyTorch или TensorFlow? OpenAI или Anthropic? Развернуть на AWS, Google Cloud или поднять свой кластер? Каждый день мы принимаем десятки решений, которые, как нам кажется, определяют судьбу наших проектов. Мы чувствуем себя у руля, архитекторами сложных систем, где наш интеллект и наш код — главная движущая сила. Мы выбираем фреймворки и отстаиваем свои модели в священных войнах в комментариях. Это пьянящее чувство контроля, иллюзия всемогущества в мире, который мы сами создаем строчка за строчкой.
А теперь давайте нажмем на паузу и сменим масштаб. Что, если я скажу вам, что все эти выборы, вся эта интеллектуальная акробатика — лишь игры в песочнице? И что границы этой песочницы, ее форма и даже свойства песка были определены задолго до того, как мы написали первую строчку кода. Они были вытравлены в кремнии в стерильных лабораториях людьми, которых мы редко видим, — инженерами-аппаратчиками.
Предлагаю взглянуть на нашу профессию через метафору. Мы, разработчики, — это архитекторы. Мы проектируем элегантные здания из кода, продумываем их логику, эстетику и функциональность. Мы можем построить изящный небоскреб или уютный загородный дом. Но ни один архитектор не начинает работу, не получив отчета от геолога. Именно геолог говорит, где можно строить, а где нельзя. Он изучает состав почвы, глубину залегания твердых пород, сейсмическую активность. Он определяет фундаментальные, неизменные законы физического мира, которые архитектор обязан принять как данность. Мы не можем построить небоскреб на болоте, как бы гениален ни был наш проект.
В мире искусственного интеллекта «геология» — это архитектура чипов. Именно она определяет, какие математические операции будут быстрыми, а какие — мучительно медленными. Какие типы моделей будут процветать, а какие так и останутся красивыми теориями на бумаге. Мы можем сколько угодно спорить о преимуществах рекуррентных сетей, но если «геология» нашего GPU создана для массового параллелизма матричных умножений, то победят Трансформеры. Это не вопрос элегантности кода, это вопрос фундаментальной физики и экономики вычислений.
Эту идею лучше всего выразил человек, который, по сути, и является главным «геологом» нашей эпохи. Дженсен Хуанг, CEO NVIDIA, в этом году заметил, что ускоренные вычисления требуют «фулстек разработки, а не только чипов». В этой фразе вся суть: производительность — это не свойство одного компонента, а результат гармонии всей системы, от транзистора до программного API. Иллюзия того, что мы можем просто писать код в вакууме, разбивается о реальность кремния.
Так кто же на самом деле определяет будущее AI — мы, архитекторы кода, или они, геологи, формирующие сам ландшафт, на котором мы строим? В этой статье мы отправимся в путешествие вглубь этого вопроса, от монополии NVIDIA и вечно вторых AMD до восстания альтернативных чипов, чтобы понять, чьи законы на самом деле управляют нашей индустрией.

Наследие NVIDIA: Как «идеальный брак» создал современный AI
Итак, если мы приняли метафору «Архитектора и Геолога», то история современного AI — это история открытия одного невероятно удачного геологического пласта. Долгое время архитекторы нейросетей бродили по разным ландшафтам, пытаясь возвести свои конструкции на зыбкой или неудобной почве. Но в какой-то момент они наткнулись на идеальный фундамент — графический процессор (GPU) от NVIDIA, который оказался словно специально создан для одного конкретного архитектурного стиля. Этим стилем стал Трансформер.
Это был не просто удачный союз, это был «идеальный брак», который определил развитие индустрии на десятилетие вперед. Чтобы понять его природу, нужно взглянуть на обе стороны этого партнерства. Трансформер был гениально спроектированным ключом, но его гениальность раскрылась в полной мере лишь потому, что он идеально подошел к замку — архитектуре GPU.
Что же представлял собой этот замок? Изначально GPU не предназначались для AI. Но с появлением архитектуры Volta инженеры NVIDIA встроили в них нечто революционное — Тензорные Ядра (Tensor Cores). Представьте себе обычное ядро CUDA как универсального мастера, способного выполнять разные задачи. Тензорное ядро — это узкоспециализированный робот на конвейере, который умеет делать только одно: брать две матрицы, перемножать их и складывать с третьей (операция FMA). И делает он это с немыслимой, сверхчеловеческой скоростью. Вдобавок к этому, он научился математическому трюку под названием вычисления со смешанной точностью (mixed-precision). Это как если бы наш робот понял, что для большинства операций не нужна ювелирная точность, и начал выполнять их с форматами данных пониженной разрядности (например, FP16, BF16, TF32, FP8), накапливая итоговый результат уже в высокоточном формате (FP32). Это позволило еще больше увеличить пропускную способность.
И тут на сцену выходит ключ — архитектура Трансформера. Ее сердце, механизм внимания, по своей сути является гигантской последовательностью именно тех операций, на которые были заточены Тензорные Ядра — умножение матриц. Это было идеальное совпадение. Трансформеру не нужно было, чтобы GPU делал что-то другое. Ему нужно было, чтобы он делал одну-единственную вещь, но делал ее быстрее всего на свете.
Контраст с предыдущими архитектурами, такими как RNN и LSTM, разителен. Это был «неудачный брак». Их фундаментальная проблема — последовательная природа. Чтобы обработать пятое слово в предложении, им необходимо дождаться результата обработки четвертого. Для массово-параллельной архитектуры GPU, где тысячи ядер готовы работать одновременно, это катастрофа. Большинство «рабочих» просто простаивают, ожидая, пока завершится единственный последовательный процесс. Это все равно что пытаться использовать гигантский карьерный экскаватор для выкапывания траншеи под кабель — вся его мощь оказывается бесполезной.
Результат этого «идеального брака» был не просто эволюционным, а революционным. Это не было улучшение на 10-15%. Бенчмарки NVIDIA показали, что обучение моделей вроде BERT на GPU с Тензорными Ядрами ускорилось до четырех раз. Это был качественный скачок, который превратил теоретические исследования в инженерную реальность. Модели, на обучение которых раньше уходили недели, теперь можно было обучить за дни. Этот союз GPU и Трансформера стал тем самым твердым геологическим основанием, на котором архитекторы AI смогли, наконец, начать строить свои небоскребы. Кстати, проблемы этой архитектуры и изящные решения в виде MoE и SSM я рассматривал в этой статье.

Восстание Альтернатив: Три фронта и лобовая атака
Идеальный брак NVIDIA и Трансформеров породил целую цивилизацию, но, как и любая империя, она начала страдать от собственного успеха. Мир, построенный на GPU, оказался дорогим, дефицитным и не всегда эффективным. Когда для запуска простого чат-бота требуется кластер из железа стоимостью в десятки тысяч долларов, становится очевидно, что геологический фундамент, идеальный для небоскребов, совершенно не подходит для строительства обычных домов. Эта боль — экономическая и архитектурная — создала плодородную почву для восстания.
Но этот брак был скреплен не только в кремнии. Настоящим цементом, который намертво привязал всю индустрию к NVIDIA, стала их программная экосистема CUDA. Это не просто набор драйверов, это целый мир оптимизированных библиотек (cuDNN, TensorRT), который стал для разработчиков AI таким же привычным, как кислород. NVIDIA построила не просто замок, она вырыла вокруг него глубокий ров с крокодилами, и имя этому рву — CUDA. И любой, кто сегодня бросает вызов империи, должен штурмовать не только крепость из железа, но и этот почти непреодолимый программный ров.
И первая лобовая атака на эту крепость исходит от ее вечного соперника — AMD. В 2025 году эта битва достигла апогея с выходом ускорителя MI350X на новой архитектуре CDNA 4. AMD наносит удар по самому больному месту конкурента, делая ставку на превосходство в ключевых характеристиках: MI350X несет на борту 288 ГБ памяти HBM3E, что значительно превосходит 180 ГБ у Blackwell B200. Это не просто цифры — это возможность размещать на одном ускорителе гигантские модели, и AMD заявляет о превосходстве до 30% в задачах инференса. Однако настоящая новость заключается в том, что AMD, кажется, наконец-то избавляется от своей ахиллесовой пяты. Их исторически слабое место, программный стек ROCm, всегда был той самой причиной, по которой разработчики, даже глядя на впечатляющие характеристики железа от AMD, не спешили покидать удобную и предсказуемую «золотую клетку» CUDA. Но с версией 7.0 и интеграцией универсальных инструментов вроде Triton, ROCm впервые начинает превращаться из «вечно догоняющего» в реальную, конкурентоспособную альтернативу, предлагая рынку не только мощный кремний, но и улучшенное соотношение «токенов на доллар».
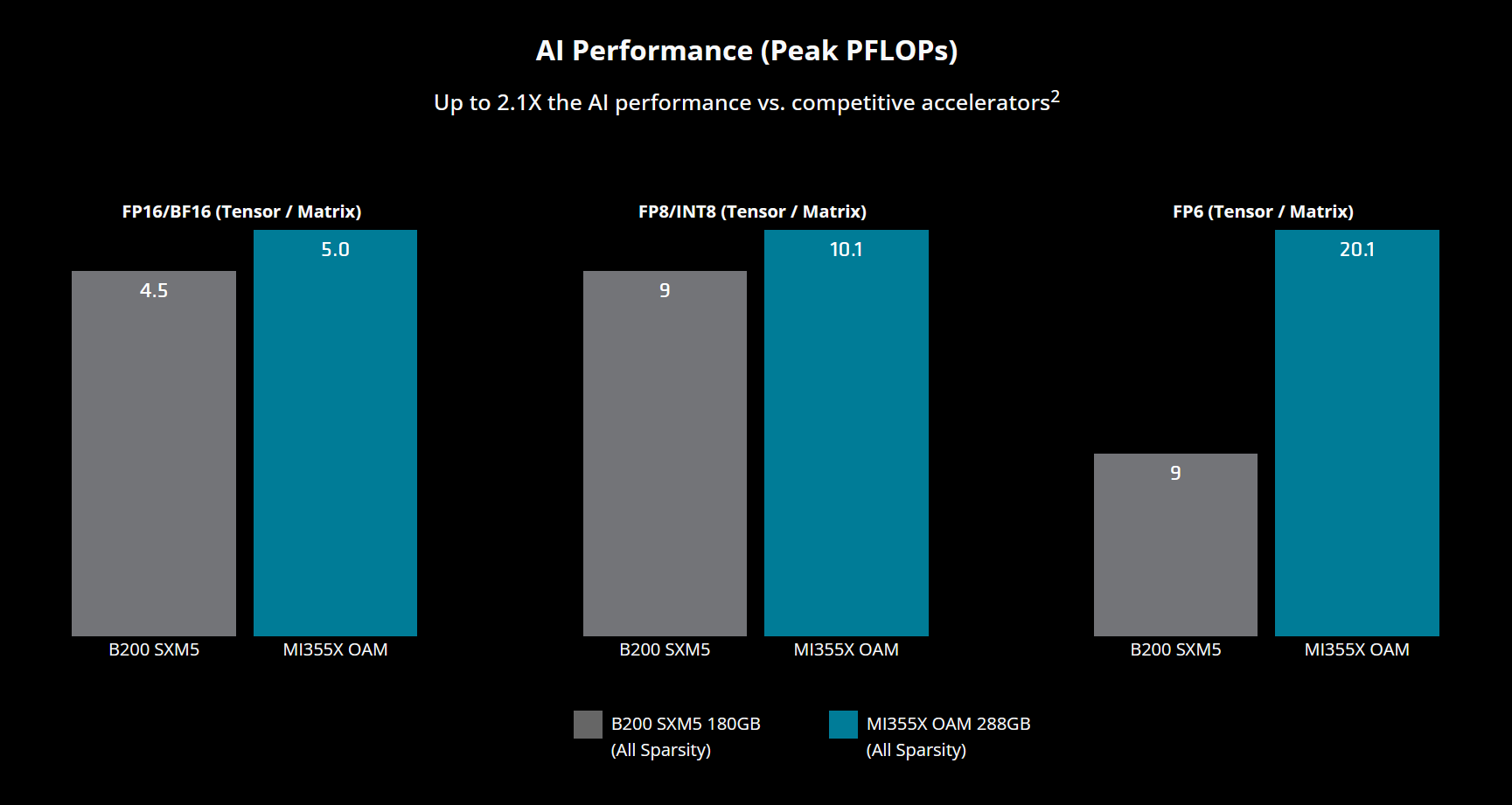
Лобовая атака — не единственный способ вести войну. Другие компании выбрали асимметричные стратегии, создавая узкоспециализированные инструменты для конкретных задач на трех основных фронтах.
Битва за задержку
Здесь главный бунтарь — компания Groq со своим Language Processing Unit (LPU). Их философия — это прямой вызов хаосу тысяч ядер GPU. Groq утверждает, что для приложений реального времени, таких как живой диалог с AI, важна не столько пиковая пропускная способность, сколько детерминизм и предсказуемость. Когда вы разговариваете с ассистентом, мучительная пауза в полсекунды убивает весь опыт. Архитектура GPU, с ее сложными планировщиками и борьбой за ресурсы, по своей природе непредсказуема.
LPU — это анти-GPU. Вместо тысяч мелких ядер у него одно огромное, но полностью управляемое. Каждая операция, каждое перемещение данных заранее планируется компилятором. Это похоже на разницу между оживленным перекрестком в час пик и идеально синхронизированным конвейером на заводе. Результат — стабильная, повторяемая и сверхнизкая задержка. Groq не пытается превзойти NVIDIA в обучении гигантских моделей; они создали скальпель для одной конкретной операции — мгновенного инференса.
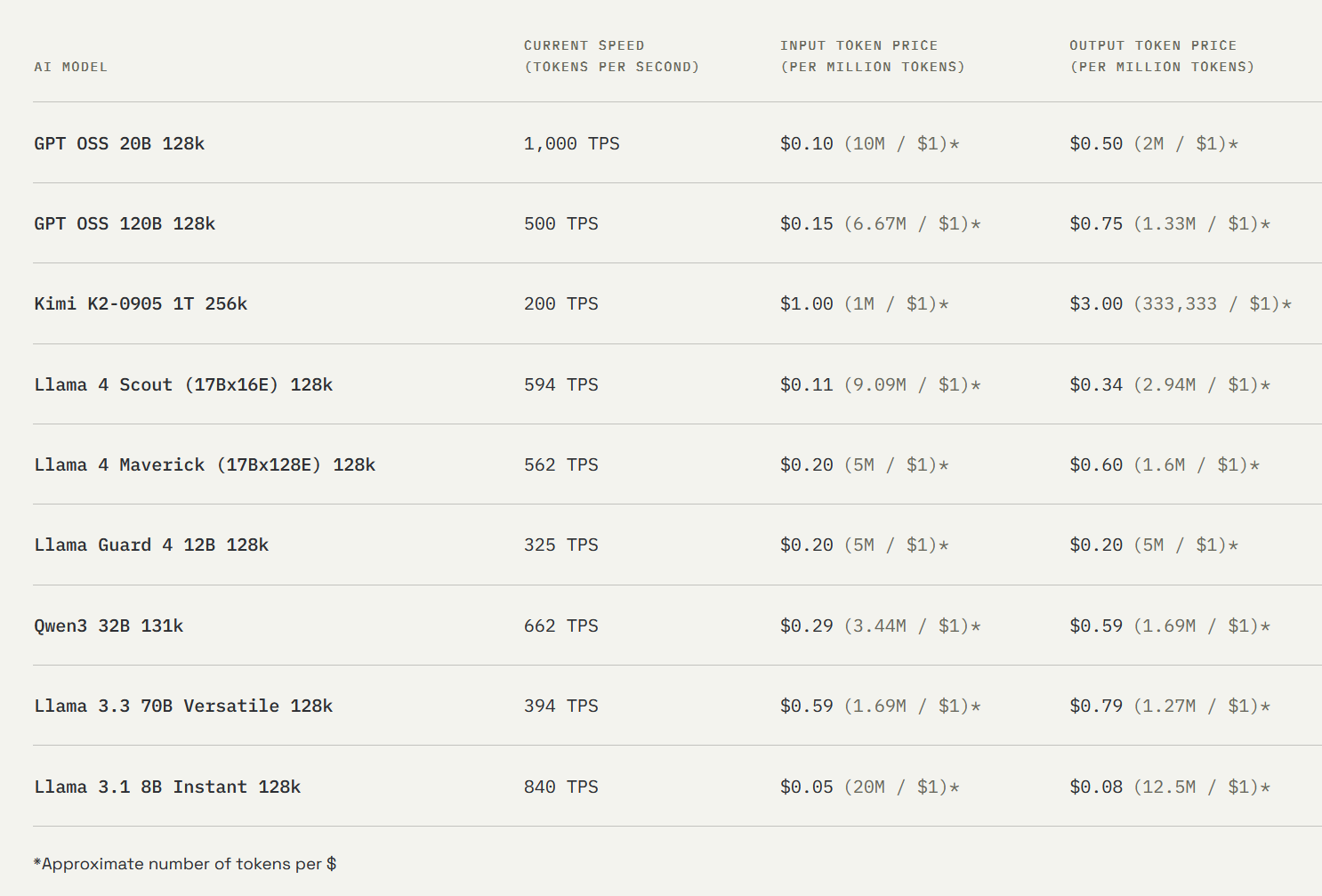
Битва за масштаб
На этом фронте сражается титан по имени Cerebras. Если Groq — это хирург, то Cerebras — это инженер, строящий космический лифт. Их враг — не скорость вычислений на одном чипе, а задержки при обмене данными между чипами. Любой, кто строил большой кластер из GPU, знает, что самое узкое место — это соединения.
Решение Cerebras одновременно безумно и гениально: избавиться от соединений, поместив весь компьютер на одну гигантскую кремниевую пластину. Их чип Wafer-Scale Engine 3 (WSE-3) — это монстр с 4 триллионами транзисторов и 900 000 AI-ядер. Это позволяет загружать целые слои нейросети на один кристалл, устраняя необходимость в медленном обмене данными между тысячами отдельных GPU. Их партнерство с Meta для поддержки Llama и недавние заявления о том, что их система CS-3 превосходит NVIDIA Blackwell при инференсе гигантских моделей, показывают серьезность их амбиций. Cerebras создает скальпель размером с меч, предназначенный для рассечения самых больших и сложных моделей, которые только существуют.
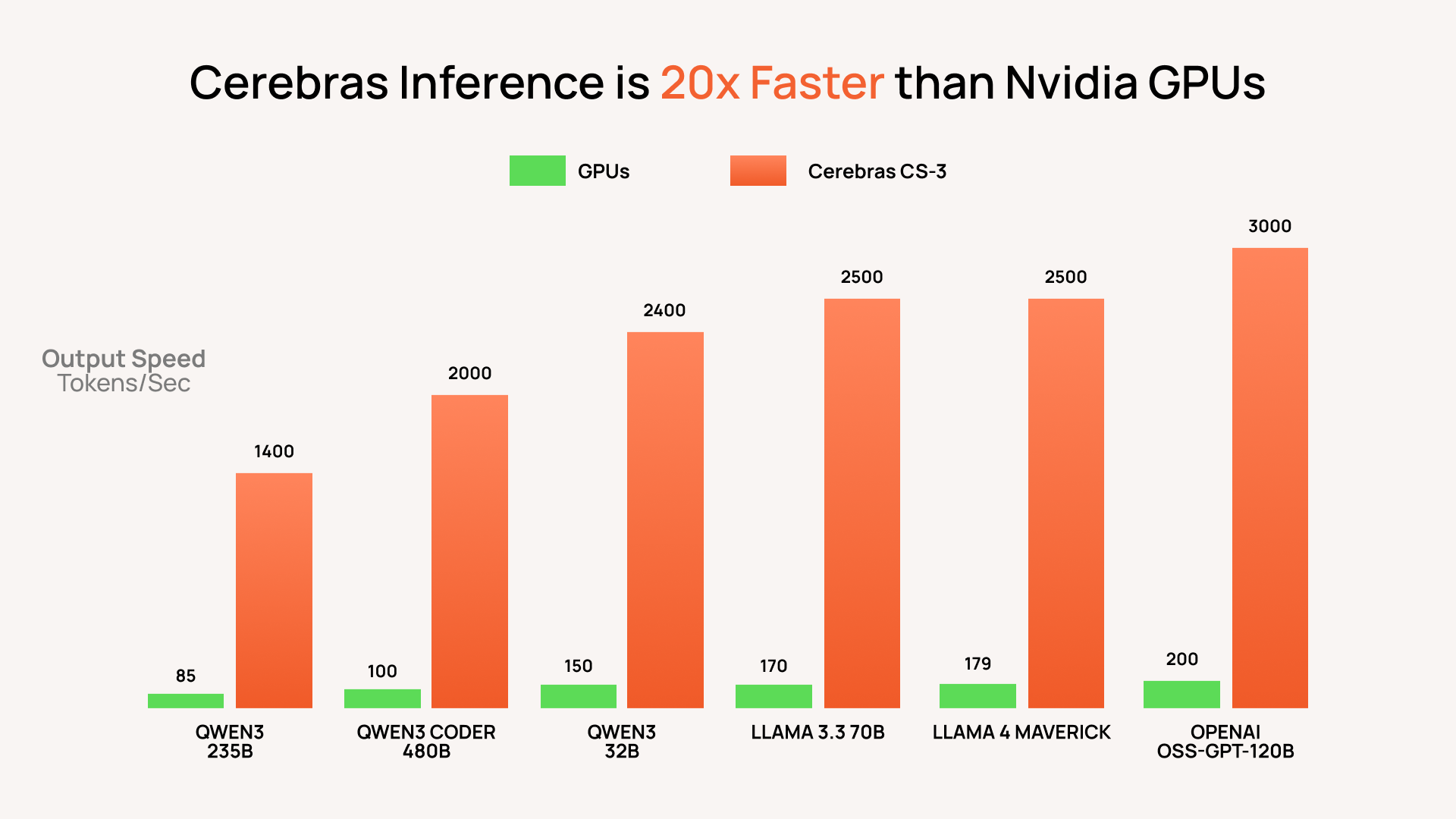
Битва за эффективность
Третий фронт — самый тихий, но, возможно, самый важный. Это битва за периферийный ИИ (Edge AI). Здесь цель — не максимальная производительность, а максимальная эффективность на ватт энергии. Речь идет о создании маленьких, холодных и дешевых «мозгов» для миллиардов устройств, которые нас окружают: от камер на заводе до вашего смартфона. Такие компании, как Google (Coral Dev Board), Qualcomm и Hailo, создают чипы, которые потребляют всего несколько ватт. Их философия — не тащить гигабайты данных в облако к огромному AI, а принести крошечный, но достаточно умный AI прямо к источнику данных. Это не просто инженерный компромисс; это фундаментальный сдвиг в архитектуре, продиктованный законами физики и экономики для мира интернета вещей.
Чтобы лучше понять расстановку сил на этом новом поле боя, давайте взглянем на карту.


Корпоративные «крепости»: Google, Amazon и Apple
Если на предыдущих фронтах мы наблюдали восстание внешних «бунтарей» против империи NVIDIA, то теперь мы видим нечто более фундаментальное — великий раскол внутри самих империй. Технологические гиганты, которые долгое время были крупнейшими покупателями чипов, пришли к выводу, который рано или поздно делает любой крупный потребитель: зачем покупать на рынке то, что можно вырастить самому?
Представьте, что вы — владелец сети ресторанов мирового класса. Долгое время вы закупали лучшие ингредиенты на открытом рынке. Но рынок нестабилен: цены скачут, поставки срываются, а ваш главный поставщик (NVIDIA) диктует условия всем. В какой-то момент вы решаете, что для контроля качества, снижения издержек и создания уникальных блюд вам нужна собственная ферма. Вы начинаете контролировать все: от семян и почвы до рецепта на тарелке. Именно этим сейчас и занимаются Google, Amazon и Apple. Они строят свои кремниевые «фермы», чтобы перестать зависеть от внешнего рынка и создать полностью контролируемый, вертикально-интегрированный конвейер от транзистора до конечного пользователя.
Стратегия Google: Двойной удар
- Бизнес-модель: Google ведет войну на двух фронтах — в облаке (Google Cloud Platform) и на потребительском рынке (устройства Pixel).
- Стратегия в кремнии: Их подход — это зеркальное отражение бизнес-модели. Для облачной войны у них есть тяжелая артиллерия — Ironwood TPU, седьмое поколение их тензорных процессоров, заточенных под сверхмасштабный инференс. Это их способ сказать клиентам GCP: «Вам не обязательно платить NVIDIA, у нас есть своя, более эффективная и дешевая альтернатива». А для войны в карманах пользователей у них есть Tensor G5, мозг смартфонов Pixel. Этот чип, созданный для локального выполнения моделей вроде Gemini Nano, позволяет реализовать уникальные AI-функции прямо на устройстве. Это не просто два разных чипа; это единая стратегия по захвату контроля над всей AI-экосистемой, от дата-центра до вашего смартфона.
Стратегия Amazon: Холодный экономический расчет
- Бизнес-модель: Amazon Web Services (AWS) — это не просто игрок на облачном рынке, это сам рынок. Их главная задача — удержать и расширить свое доминирование.
- Стратегия в кремнии: В отличие от Google, стратегия Amazon носит менее технологический и более экономический характер. Разрабатывая собственные чипы, такие как Trainium для обучения и Inferentia для инференса, они создают главный рычаг давления в облачной войне — цену. Предлагая своим клиентам (среди которых такие гиганты, как Anthropic) более выгодное соотношение цены и производительности, они делают миграцию на другую платформу экономически невыгодной. Это не столько гонка за производительностью, сколько создание «золотой клетки». AWS строит свою кремниевую ферму не для гурманских изысков, а для того, чтобы сделать свои «продукты» самыми доступными на рынке, тем самым вытесняя конкурентов.
Стратегия Apple: Крепость приватности
- Бизнес-модель: Apple не продает облака или поисковые запросы. Они продают премиальные устройства, где ключевыми ценностями являются пользовательский опыт и конфиденциальность.
- Стратегия в кремнии: Их подход полностью подчинен этой модели. Вся мощь их Neural Engine, который в чипе A19 Pro и грядущем M5 станет еще совершеннее, направлена на одно — максимальную обработку данных на устройстве (on-device processing). Apple строит свою крепость не в облаке, а прямо в вашем iPhone. Зачем? Во-первых, это приватность, краеугольный камень их бренда. Ваши данные не покидают устройство. Во-вторых, это пользовательский опыт. Локальная обработка означает мгновенный отклик и глубокую интеграцию AI-функций без зависимости от интернет-соединения. Apple не пытается выиграть гонку за самый большой AI в дата-центре; они выигрывают гонку за самый умный, быстрый и безопасный AI в вашем кармане.
Этот раскол — не просто техническая диверсификация. Это фундаментальная перестройка индустрии. Гиганты больше не хотят быть просто «архитекторами», работающими на чужой «геологии». Они сами становятся геологами, создавая идеальный ландшафт для своих программных амбиций и строя неприступные кремниевые крепости, чтобы защитить свои бизнес-империи.

Поле битвы, которое мы не видим
Но если вы думаете, что эти корпоративные «крепости» — это самый большой раскол в мире технологий, то вы смотрите не на ту карту. Настоящая, тектоническая трещина проходит не между Купертино и Маунтин-Вью. Она разделяет сверхдержавы. Настоящая война за будущее AI идет не в залах для презентаций, а в тишине правительственных кабинетов, и ее оружие — это экспортные регуляции и списки санкций.
То, что мы наблюдаем, — это полноценная технологическая осадная война. Соединенные Штаты планомерно возводят «осадную стену» вокруг Китая, стремясь отрезать его от поставок самого передового оружия нашей эпохи. Речь идет не только о готовых чипах, таких как специально созданный для обхода ограничений NVIDIA H20, который все равно попал под санкции. Удары наносятся по самому фундаменту производства — по литографическим машинам от таких компаний, как ASML, без которых невозможно создавать современные полупроводники. Заявленная цель — замедлить технологическое и военное развитие Китая. Реальный результат — раскол мира на две технологические вселенные.
Как на это отвечает Китай? Прямой штурм «осажденной стены» пока невозможен. Несмотря на гигантские государственные инвестиции в компании вроде SMIC и Huawei, создать полный аналог NVIDIA H100 в условиях изоляции — задача на грани фантастики. Поэтому Китай прибег к блестящему асимметричному ответу. Он перенес поле битвы туда, где технологические стены не работают.
И здесь мы подходим к главному парадоксу этой новой холодной войны — парадоксу Open-Source. За последний год мы видим, как китайские компании и лаборатории (Alibaba, DeepSeek, Z.ai) становятся доминирующей силой в мире моделей с открытым весом (open-weight). Это не совпадение, это стратегия. Логика этого маневра гениальна в своей простоте: «Вы не даете нам строить самые большие и мощные „линкоры“ (гигантские закрытые модели)? Отлично. Мы наводним мировой океан тысячами быстрых, маневренных и бесплатных „эсминцев“ (эффективные open-source модели). Каждый из них, возможно, слабее вашего флагмана, но вместе они завоюют симпатии всего мирового флота разработчиков и сделают наши технологии новым стандартом».
Эта геополитическая игра перестает быть абстракцией и напрямую влияет на каждого из нас. Когда вы, как разработчик, сегодня выбираете между закрытой API от американской лаборатории и высокопроизводительной открытой моделью от Alibaba, ваш выбор — это уже не просто техническое решение. Это крошечное эхо большой геополитической борьбы. Вы голосуете за одну из двух формирующихся экосистем, вольно или невольно принимая сторону в битве, которая идет на поле, которого мы даже не видим.

Новый закон для AI-архитектора
Итак, к чему мы пришли, пройдя путь от монолитной империи NVIDIA до раздробленных, но амбициозных княжеств Groq, Cerebras и Big Tech? Мы пришли к простому, но фундаментальному выводу: эпоха, когда можно было игнорировать «геологию», закончилась. «Идеальный брак» Трансформера и GPU, этот надежный фундамент, на котором выросли все современные AI-небоскребы, больше не является единственно возможным. Эпоха универсального швейцарского ножа сменяется эпохой набора хирургических скальпелей.
И это не просто мое умозаключение. Это объективный тренд, подтвержденный самым убедительным из всех аргументов — сухим языком денег. Прогнозы аналитиков рисуют картину тектонического сдвига. Мировой рынок AI-чипов готовится вырасти с $53 миллиардов в 2024 году до ошеломляющих $296 миллиардов к 2030 году. Но самое интересное — не общий рост, а его структура. Сегмент специализированных чипов (ASIC) в 2025 году должен занять 37% рынка инференса в дата-центрах, напрямую отбирая долю у универсальных GPU. А тихий фронт периферийных вычислений превратится в гигантский рынок объемом $14.1 миллиарда уже в следующем году. Деньги инвесторов и стратегов утекают от универсальности к специализации.
Что это означает для нас, архитекторов кода? Это означает, что наша старая ментальная модель устарела. Мы больше не можем думать о железе как о чем-то, что «просто работает» где-то там, в облаке. Выбор аппаратной платформы перестает быть вопросом для DevOps-инженера на последнем этапе проекта. Он становится одним из первых и самых важных архитектурных решений. Чтобы выжить и преуспеть в этой новой эре, нам нужен новый свод правил.
- Правило №1: Думай о железе в первый день, а не в последний. Выбор между инференсом на Groq LPU, обучением на Cerebras или развертыванием на Edge-устройстве с чипом от Hailo фундаментально меняет архитектуру вашей модели, экономику вашего продукта и пользовательский опыт. Это решение нужно принимать на этапе проектирования, а не на этапе деплоя.
- Правило №2: Подбирай чип под задачу, а не задачу под чип. Эпоха «один размер для всех» прошла. Если вы создаете диалогового ассистента, где важна каждая миллисекунда задержки, ваш выбор — LPU. Если вы тренируете модель с триллионом параметров, ваш путь лежит к Wafer-Scale архитектуре. Пытаться решить обе задачи с помощью одного и того же универсального GPU — значит сознательно идти на компромисс в производительности и стоимости.
- Правило №3: Понимай экономику, а не только технологию. Выбор аппаратной платформы — это в первую очередь экономическое решение. Сколько стоит токен? Какова стоимость владения (TCO) для вашего клиента? Как выбор чипа повлияет на энергопотребление и, следовательно, на операционные расходы? В мире, где AI становится товаром, победит тот, кто лучше считает юнит-экономику. И помните: эхо геополитической битвы теперь слышно в каждом техническом решении. Выбор между открытой азиатской моделью и закрытой американской — это уже не только вопрос производительности, но и стратегическая ставка в глобальной игре.
Иллюзия выбора, с которой мы начали, действительно закончилась. Но на смену ей приходит не диктатура кремния, а эпоха осознанного выбора. Мы больше не можем позволить себе быть просто архитекторами, не знающими основ геологии. Настало время, когда геолог и архитектор должны научиться говорить на одном языке.
Оставайтесь любопытными.


