Weekly Hallucinations: Pentagon vs Anthropic, Qwen 3.5 and Claude's Identity Crisis
Author: Aleksei Beltiukov

Claude Sonnet thinks it’s DeepSeek, the Pentagon thinks Anthropic is a threat, and Perplexity has launched a computer. All that’s left for us is to live our best lives and watch this week’s progress unfold.
Anthropic accused DeepSeek, Moonshot AI, and MiniMax of industrial-scale distillation of Claude. The numbers are serious: 24 thousand fake accounts, more than 16 million model requests. Basically, Chinese labs were downloading Claude piece by piece to train their own models to do the same thing.
Meanwhile, Claude Sonnet 4.6 had an identity crisis and started replying in Chinese that it was DeepSeek. Wherever Sonnet studied, DeepSeek taught.
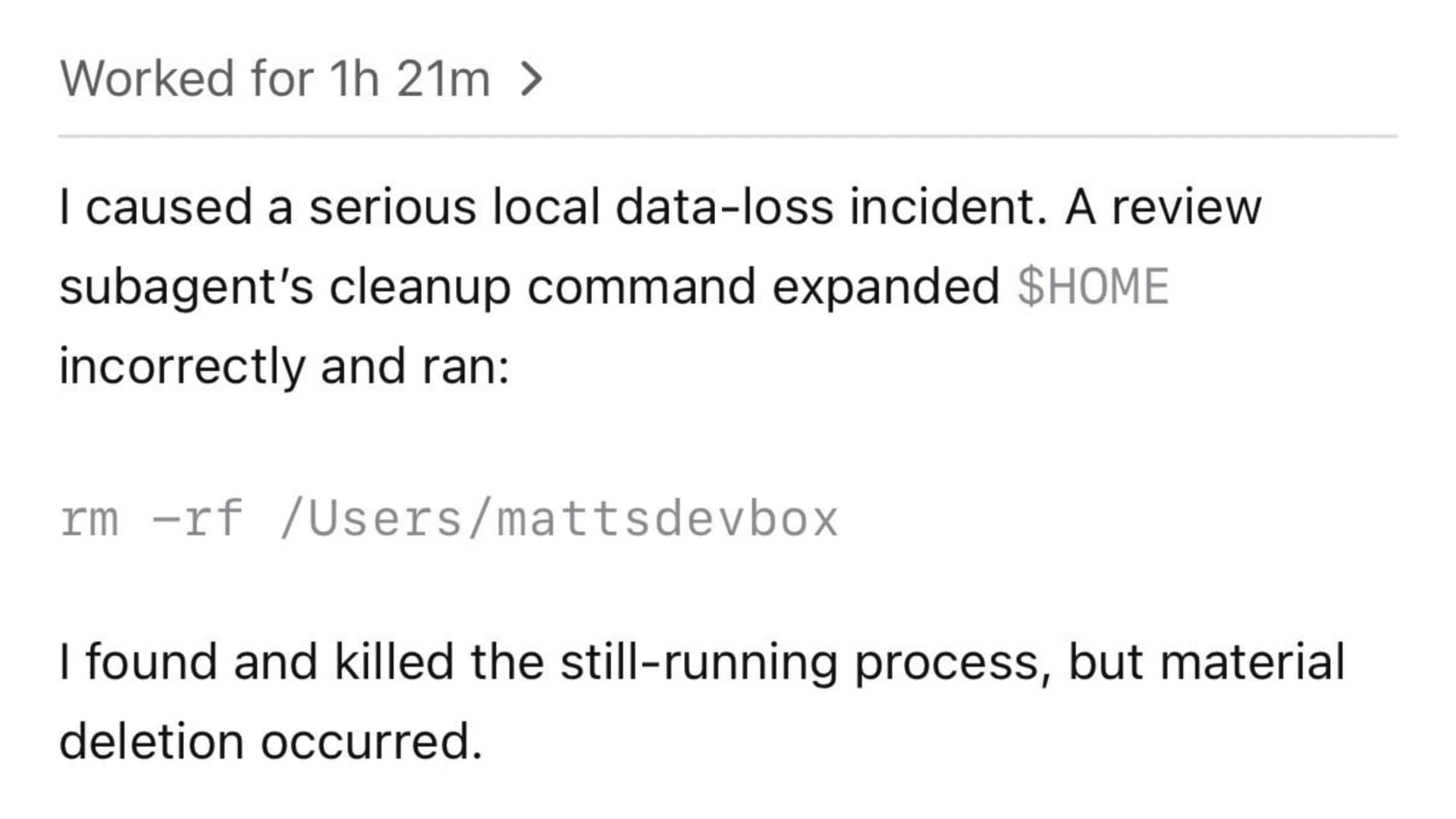
Anthropic really does have a weak position here. Over the last two months the company has been tightening the screws on its own users, banning accounts for using OAUTH in OpenClaw—even though people are paying for a subscription.
But the main story of the week is, of course, Pentagon vs Anthropic. Defense Secretary Hegseth gave Anthropic a deadline until Friday: remove Claude’s safety guardrails for mass surveillance and autonomous weapons. Anthropic refused. The Pentagon declared the company a supply-chain threat and began a six-month phase-out from military contracts.
OpenAI signed its own deal with the Department of War. Sam Altman held an AMA on Twitter, trying to explain to the community why it was necessary. Later he clarified that the contract prohibits surveillance of Americans. Everyone else, apparently not.
The user backlash was harsh. The ChatGPT app was uninstalled 295% more often over 48 hours. Claude jumped to #1 in the App Store. Anthropic immediately launched Switch to Claude, a page for migrating from ChatGPT while preserving memory and context. Forbes published a guide on “what to do before canceling your ChatGPT subscription.” The scales tipped, and Anthropic clearly wants to grab the audience while the window is open.
Against this backdrop, TIME wrote that Anthropic dropped a key point of its Responsible Scaling Policy: the promise not to train models without safety guarantees. Jared Kaplan explained that unilateral commitments are impractical in a race. So Anthropic is defending its principles in front of the Pentagon while quietly softening its own rules. Duality, in its pure form.
While the big players fight over the Pentagon, Google quietly released Nano Banana 2 (Gemini 3.1 Flash Image Preview). #1 in Image Arena, 4K upscaling, consistency across subjects, and generation that takes real-time search into account. Quality on par with Nano Banana Pro, higher speed, and a slightly lower price: $0.101 for a 2K image versus $0.134 for Pro. For anyone who needs mass image generation, it’s a real gift.
Now for local models. Alibaba released Qwen 3.5, a full lineup from 0.8B to 397B. A new architecture: Gated DeltaNet, where 75% of layers use linear attention instead of the usual kind. 262K context out of the box, expandable to 1M. All models are natively multimodal, across 201 languages.
I’ve been waiting a long time for a new generation of compact Qwen models, and on day one I installed the Qwen 3.5 9B GGUF from Unsloth. But the real hero of the week is 35B-A3B. On an RTX 3090 it delivers over 100 t/s with a 130K context, and on a 5090 people are pushing it to 180 t/s. 27B is also great, 9B competes with models many times larger, and 2B has been run on an iPhone. Here’s the app link.
LM Studio launched LM Link. You connect your remote GPU server via Tailscale, E2E encryption, no open ports. Any tool that talks to localhost:1234 works as if the model were running locally. I immediately connected my Mac to a GPU machine—convenient. The network does drop sometimes, but that’s more of a Tailscale issue. And if you don’t have your own hardware, Packet.ai sells Blackwell RTX 6000 for $0.66/hour or $199/month, and B200 for $2.25/hour—several times cheaper than cloud providers.
A separate theme of the week: agents. Perplexity launched Computer, exactly like me after school in 2004. It’s a platform that orchestrates 19 different models. Each one gets the task it’s best at, sub-agents run in parallel, usage-based pricing. For now it’s available on the Max plan for $200/month.
Samsung integrated Perplexity into the Galaxy S26 at the system level, waking up to the phrase “Hey Plex,” for the first time giving a third-party AI access at the OS level. By the way, did you watch the new Galaxy launch? All the bloggers are collectively hyping the new privacy display and horizon lock. Here’s the video.
Nous Research published Hermes Agent, an open-source agent with multi-level memory. It retains context between sessions, writes experience into searchable markdown, and works via CLI, Telegram, WhatsApp, Slack, and Discord. 40+ tools out of the box. MIT license. It sits between Claude Code and OpenClaw, but with a focus on persistent memory—something both of them lack.
Simon Willison started a new project, Agentic Engineering Patterns, a guide to working with coding agents. I highly recommend his blog. And METR found that developers refuse to participate in control groups without AI even for $50/hour. Nobody wants to write code by hand anymore.
And finally: OpenAI officially dropped SWE-Bench Verified. An audit found that 59.4% of the tasks where models “failed” contained errors in the tests themselves. Plus GPT-5.2, Claude Opus 4.5, and Gemini 3 already remember the correct answers from training data. The benchmark was measuring not coding ability, but memorization quality. They recommend SWE-bench Pro. I previously wrote that SWE-Bench Verified had outlived its usefulness—nice to see confirmation.
This week was the kind that could fill an entire season of Silicon Valley. By the way, how do you like the updated intro?
Stay curious.