Multimodal AI in 2025: How GPT-5.1, Gemini, Claude, and Grok Learned to Understand Everything
Author: Aleksei Beltiukov

Not so long ago, you had a separate remote control for each home device: one for the TV, another for the air conditioner, a third for the music center. Each spoke its own language, and making them work together was almost impossible. The world of artificial intelligence looked much the same just five years ago – a set of powerful but disparate models, each capable of doing only one thing.
Let's go back to the not-so-distant year of 2020. The AI landscape resembled an archipelago of isolated islands, each with its own ecosystem. For text, transformers like BERT reigned supreme; for images, CNNs like ResNet; for audio, models like WaveNet, and they all lived in different worlds.
These were, if you will, different planets with their own laws of physics. Each architecture carried unique inductive biases – inherent assumptions about the nature of data. CNNs were "tuned" for spatial hierarchies, assuming that neighboring pixels were more important than distant ones. Recurrent Neural Networks (RNNs) were designed to work with sequences over time. Transformers, on the other hand, were initially optimized for semantic connections in text.
Of course, there were attempts to build bridges between these worlds. Early multimodal approaches resembled a steampunk engineering solution: researchers literally "stitched together" ready-made, pre-trained models. A typical approach looked like this: take a pre-trained (and frozen) ResNet for images, take a similar BERT for text, and train a small fusion module based on cross-attention on top of them. The models, however, don't learn to see and read simultaneously – they simply forward vectors to each other through a thin "translator."
By 2025, this modular approach has given way to a tectonic shift towards unified AI infrastructures. The zoo of highly specialized models is being replaced by a single, universal architecture that underpins the processing of all modalities. The evolution can be clearly represented in a simple table:

This transition from fragmentation to unification is the main story of modern AI. It is what allows us today to speak not just about "another version of ChatGPT," but about a paradigm shift across the entire stack.
So, what if I tell you that in 2025, GPT-5.1, Gemini 2.5, Claude Opus 4.1, and Grok-4 can simultaneously understand text, images, and video – and all are built around the same fundamental idea? An idea that was able to unite these disparate worlds.

The Revelation. Next Token Prediction: one principle to rule them all
So, we left behind the fragmented world of 2020 and asked ourselves: what single idea could unite text, images, and audio under the wing of one architecture? The answer, at first glance, may seem dishearteningly simple. This universal engine, driving GPT-5.1, Gemini 2.5, Claude Opus 4.1, and Grok-4, is called Next Token Prediction (NTP).
At its core, NTP is a painfully familiar game of "finish the sentence." Imagine you give the model a prompt: "The cat sits on the ___." The model's task is not to "understand" the cat or the chair, but merely to calculate the probability distribution for the next word from its gigantic vocabulary. For example, it might decide that with 50% probability the next word will be "lap," with 30% "floor," and with 20% "chair." Its entire training process boils down to maximizing the probability of the correct, "ground truth" token that appeared in the training data.
And this is where the revelation begins. This simple, almost childlike game turned out to be the "one ring to rule them all." As stated in a comprehensive review from late 2024, which I analyzed, "tasks from different modalities can be effectively encapsulated within NTP." The secret is that NTP is a self-supervised process. Models don't need expensive human annotations; the correct answer – the next token – is already contained within the data itself. This allows it to be fed trillions of tokens from the internet, and it will learn on its own.
"Okay," you say, "text is clear. But what about pictures and videos?" And this is where the magic lies, removing all the mystique from multimodal models. The principle extends to other modalities by transforming all data into a single format – a sequence of discrete tokens. If we can turn an image into a sequence of visual "words," and audio into a sequence of sonic "syllables," then for the transformer, the task remains the same. For example, we give the model this input: "Here's a photo of my kitchen: [image]. Describe what you see." Internally, it perceives this as one sequence of tokens:["Here's", "a", "photo", "of", "my", "kitchen", ":", <IMG>, v₁, v₂, …, vₙ, </IMG>, ".", "Describe", "what", "you", "see", "."]. For the transformer, this is just a set of tokens in a specific order – it doesn't distinguish between "text" and "visual" tokens in essence. It just keeps playing its game.
And this is not just theory. By November 2025, NTP is recognized as the "foundational paradigm" not only for language but also for vision and audio tasks. For example, the acclaimed model Emu3, released in September 2024, is capable of generating video by "simply predicting the next token in a video sequence." In the audio domain, researchers in 2025 learned to model a dialogue between two people by having the model predict a pair of tokens at each step – one for each speaker.
Technically, NTP is the training of an autoregressive model that approximates the probability distribution of the next token based on the previous context. The model parameters are adjusted to minimize the cross-entropy loss function (cross-entropy loss) between the predicted distribution and the true next token. However, behind all this mathematics lies the same simple idea – to guess what comes next.
This brings us to the main paradox. If a model can only do one thing – guess the next token – why did it suddenly become capable of explaining code, describing pictures, and commenting on conference videos? The answer lies in that very step we have taken for granted until now – the alchemy of transforming reality into tokens.

Alchemy. How to turn an image into a sequence of tokens
We have established that the universal language of modern AI is a sequence of tokens, and their main skill is predicting the next token in that sequence. But here lies the main trick, the real modern alchemy. How to transform something continuous, rich, and analog, like a photograph of a sunset, into a strict, discrete sequence of numbers that a model like GPT can work with?
The key to this transformation is called discrete visual tokenization. This is the process that underpins the "vision" of all modern multimodal systems. Without it, any picture for a language model is no more than an incomprehensible set of pixels. The best analogy I can offer here is creating a mosaic. Imagine you have a limited set of small colored tiles (this is our codebook). To recreate a picture, you break it down into small sections and for each section, you choose the most suitable tile in terms of color and texture from your set. In the end, you get not the picture itself, but a sequence of tile numbers from which it can be assembled. The model does not see a "photo"; it sees precisely this sequence – [tile_7, tile_83, tile_12, ...] – and learns to understand and continue it so that meaningful images are produced.
At a technical level, this process looks like this:
- An image is taken, for example, 512x512 pixels in size.
- A special encoder model (formerly more often based on CNNs, now increasingly on ViTs) "compresses" it, transforming it into a compact but still continuous latent representation.
- Then the most important step occurs – quantization. Each vector in this compressed representation is mapped to its "nearest neighbor" in a pre-learned codebook – that very set of reference "tiles."
- The output is what is needed: a sequence of discrete indices (tokens) from this codebook. Standard Transformer blocks can work with this sequence in the same way they work with text.
Pioneers of this approach included architectures such as VQ-VAE (Vector Quantized Variational Autoencoder) and, later, VQGAN, which added a GAN component to the process to make images reconstructed from tokens clearer and more realistic. However, early tokenizers suffered from serious problems: "codebook collapse," where the model used only a small fraction of available "tiles," and "semantic loss," where tokens were not "rich" enough to convey complex visual concepts.
The real breakthrough came when researchers realized that the quality of a model's "vision" directly depends on the quality and size of this visual codebook.
- The model Emu3.5 (October 2025), which is trained exclusively on next-token prediction, uses a huge visual vocabulary of 131,072 tokens. This allows it to demonstrate quality at and above stable diffusion models like SDXL on several image and video generation benchmarks.
- An absolute game-changer was the tokenizer MAGViT-v2. It uses a Lookup-Free Quantization (LFQ) approach, which allows it to work efficiently with giant vocabularies (up to 2^18 ~ 262 thousand tokens). Even more importantly, it uses a unified vocabulary of tokens for images and video, taking a huge step towards true unification.
This breakthrough formed the basis of the acclaimed scientific paper with the telling title "Language Model Beats Diffusion – Tokenizer is Key to Visual Generation." The authors proved that if a language model is given a good enough tokenizer, it can, by training on the simple NTP principle, outperform diffusion models in their own field – image and video generation.
So it's no wonder that dozens of different tokenizers for images, video, and audio have appeared in recent years. The industry is in this race not out of love for complexity, but because the quality of this "alchemical" process directly determines how well our AI models will "see" the world.
Unification. Vision Transformer + GPT = Multimodal Revolution
So, the alchemy has happened. We have learned to transform the analog world of images into discrete sequences of tokens. Now, on our desk, lie two entities: the familiar sequence of text tokens and the newly acquired visual ones. The logical question is: what's next? Do we need a completely new, "bilingual" architecture capable of simultaneously understanding both of these "languages"?
And here we are, perhaps, in for the main revelation of this whole story. It turns out that we already have such a brain, and its name is Transformer. The fundamental architecture underlying GPT proved to be surprisingly versatile. Its main mechanism, self-attention, is by its nature absolutely neutral to data type. It doesn't care what it's looking at – words in a sentence or something else. It simply looks for connections and dependencies within a sequence. All it needs are tokens.
A key step towards this realization was made back in 2020 when Google researchers introduced Vision Transformer (ViT). The idea was both audacious and elegant: what if we stop treating an image as a pixel grid requiring convolutional networks and start working with it in the same way as with text? ViT does exactly that. It takes an image and, like a waffle iron, slices it into a grid of non-overlapping patches of a fixed size (e.g., 16x16 pixels). Then each such two-dimensional patch is "flattened" into a long one-dimensional vector, linearly projected into an embedding of the desired dimension (say, 768), and supplemented with positional encoding so that the model knows exactly where in the original grid this piece was located.
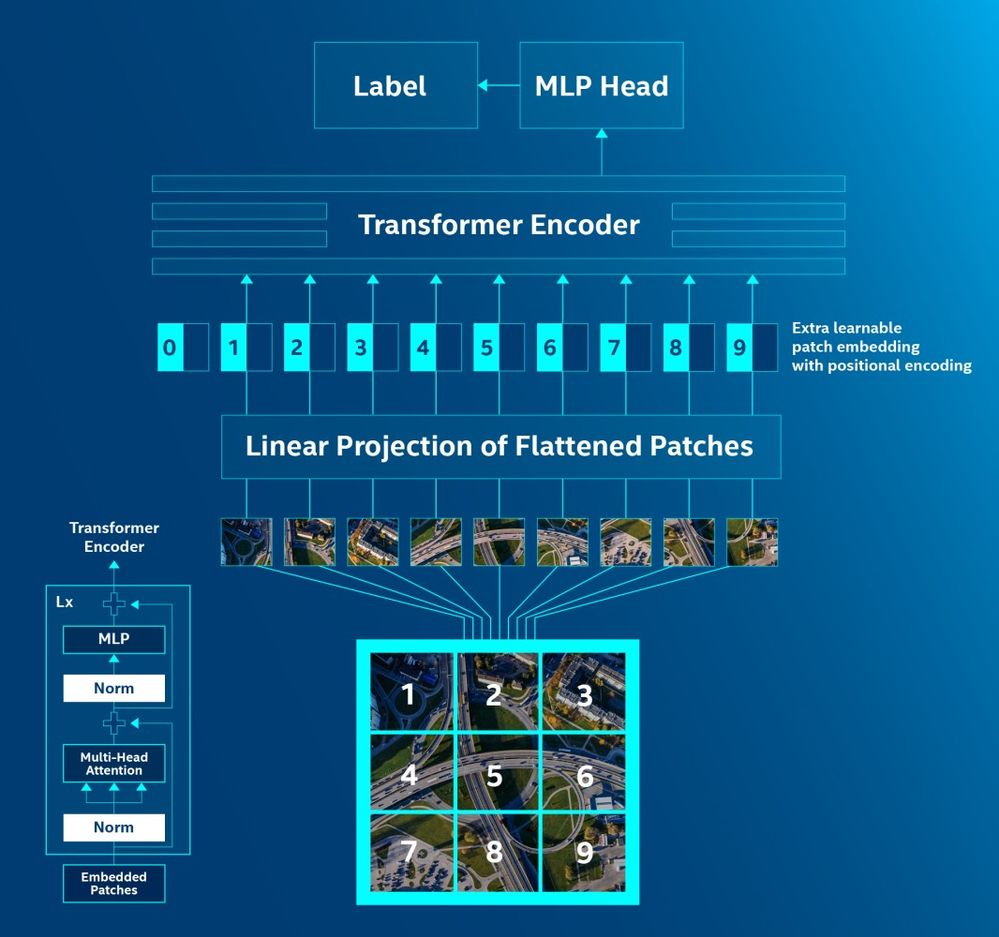
The result? For a standard Transformer encoder, the input is a sequence of, for example, 196 patch tokens, which looks exactly the same to it as tokens in NLP. It begins to apply its standard self-attention blocks to them, finding connections between the "sky patch in the upper left corner" and the "grass patch in the lower right." Vision has become a sequence processing task.
Great, now we have two sequences of tokens that the same architecture understands. How do we make them "talk" to each other within a single model? This is the central task of modality fusion, and here engineers have taken two paths.
Path one: simple but dangerous. The most direct way is to simply "glue" the sequences together. We take visual tokens from a ViT-like encoder, text tokens from a standard tokenizer, pass the visual ones through a small adapter (often a simple MLP projector to "align" their dimensionality with text), and concatenate them into a single stream. Simple, fast, and it even works. But, as practice has shown, this approach is a key factor in object hallucinations. Research published in May 2025 showed that such simple architectures often fail to distinguish semantically matching and non-matching image-text pairs. The model sees the word "banana" in the text and may start "imagining" it in the picture, even if it's not there, because the connection between modalities is too weak.
Path two: elegant and reliable. This is where a more complex mechanism comes into play – cross-attention. Unlike self-attention, where all tokens "look" at each other, here modalities are given different roles. For example, text tokens can form "Queries," and visual patches can provide "Keys" and "Values." Intuitively, this looks like this: each text token "queries" all parts of the image: "which of you relate to me?" After that, it "pulls" the necessary pieces of visual information and enriches its representation with the picture. New architectures, such as AGE-VLM (May 2025), use alternating layers of cross-attention to literally force the model to "look at the correct areas of the image." The result? A significant reduction in those very hallucinations.
It is this combination – the versatility of Transformer, the ability of ViT to turn pictures into sequences, and the elegance of cross-attention for their fusion – that has driven the multimodal revolution. Remember the days when there was one stack for text, one for computer vision, and a third for audio? In 2025, all of this is increasingly turning into the same set of transformer blocks with different "adapters." Our "universal processor" has learned to work with any data, and now we are ready to see how exactly GPT-5.1, Gemini 2.5, Claude Opus 4.1, and Grok-4 use it in real-world tasks.

Evidence. What GPT-5.1, Gemini, Claude, and Grok can do right now
All this talk about architectures, tokens, and fusion mechanisms is certainly fascinating. But it's like admiring the blueprints of a new hyperdrive. Sooner or later, the main question arises: does this thing even fly? And if so, how fast and how far? By the end of 2025, we finally have exhaustive answers. Flagship models have ceased to be laboratory experiments and demonstrate unprecedented, but characteristically specialized, capabilities in production. We see not one universal champion, but a pantheon of titans, each strong in its element.
GPT-5.1: Adaptive Intellectual and Code Master
Released just recently, GPT-5.1 from OpenAI has become the embodiment of the idea of a "thinking" model. Its key technology is "Adaptive Reasoning." This is not just a marketing term, but a commercial implementation of the Test-Time Compute paradigm. The model has learned to independently assess the complexity of a task. For a simple question, it responds in "Instant" mode, working 2-3 times faster and more economically. But if the task requires deep analysis, it automatically switches to "Thinking" mode, allocating significantly more computation to find a solution.
It's like an experienced engineer colleague who answers simple questions on the fly, but when faced with a truly complex bug, says, "Okay, I need to think," and then returns with a detailed solution. And the results speak for themselves.
- In coding: GPT-5.1 achieved 76.3% on the SWE-bench Verified benchmark, which tests the ability to solve real problems from GitHub. This is a new industry standard. The API even introduced specialized tools, such as
apply_patchfor iterative code editing. - In science and mathematics: The model demonstrates frighteningly "human" levels of reasoning, scoring 88.1% on GPQA Diamond (PhD-level questions in physics, chemistry, and biology) and achieving 94% on the challenging AIME 2025 math olympiad.
- In multimodal scenarios, GPT-5.1 can analyze screenshots, PDF documentation, and even drafts in photos, linking them with code and text in a single dialogue.
Gemini 2.5 Pro: Master of Long Context and Video
Google, with its Gemini 2.5 Pro, bet on another superpower – long context and native multimodality. Its architecture was originally created to process giant volumes of mixed information. The standard window of 1 million tokens, expandable to 2 million, is not just a big number. It's the ability to do things that were previously unthinkable.
The most striking example is working with video. Gemini 2.5 Pro can "watch" and analyze several hours of video (in Google's experiments – up to 3-6 hours, depending on settings and resolution). You can upload a multi-hour conference recording and ask: "Find all moments where Q4 strategy was discussed and summarize it." This ability, multiplied by the highest accuracy in high-stakes areas (the model scored a record 97.2% on the Japanese National Medical Examination), makes Gemini an indispensable tool for analyzing huge amounts of data. However, unlike GPT-5.1, its coding results are significantly more modest (63.8% on SWE-bench), which again emphasizes the idea of specialization. Besides video, Gemini 2.5 Pro "digests" text, screenshots, tables, and audio in a single context – which is convenient when a report, presentation, and meeting recording arrive in different formats.
Claude Opus 4.1: Reliable Corporate Expert with a "Blind Spot"
Anthropic, with its Claude Opus 4.1 model, continues its strategy, focusing on reliability, safety, and enterprise tasks. This model is positioned as an ideal tool for areas where the cost of error is high – law, medicine, compliance. And these are not empty words: a result of 96.1% on the same Japanese medical exam confirms its highest reliability.
Moreover, Claude Opus 4.1 proved to be an unexpectedly strong programmer, scoring 74.5% on SWE-bench, but noticeably lagging behind leaders in olympiad mathematics (AIME 2025), where GPT-5 and other models demonstrate almost flawless performance. Anthropic primarily optimizes Claude for reliability and safety in real business scenarios, even if it sometimes means lagging behind in purely competitive mathematical tasks.
Grok-4 Heavy: Extreme Intelligence for STEM and Instrumental Reasoning
The fourth giant in this story is Grok-4 from xAI, which was purposefully built as an "engine for complex tasks with tools and the internet." Unlike classic LLMs, Grok-4 was trained from the outset to actively use external tools – a code interpreter, web search, access to X data and Tesla telemetry – and combine them in multi-step chains.
If GPT-5.1 is an experienced engineer who can think longer, then Grok-4 Heavy is an entire team of engineers consulting each other. Internally, it uses multi-agent parallel test-time compute: instead of one line of thought, several hypotheses are launched simultaneously, which are then assembled into a final answer. On complex tasks, this provides a noticeable advantage.
- In olympiad mathematics: Grok-4 Heavy achieved 100% on AIME 2025, while the base Grok-4 scored 91.7%, consistently outperforming most competitors. At the even tougher USAMO’25 level, Grok-4 Heavy scores 61.9%, leaving other closed models behind.
- In advanced reasoning benchmarks: Grok-4 Heavy was the first to cross the 50% mark on Humanity's Last Exam, a "final" academic benchmark of PhD-level problems. On ARC-AGI V2, it shows about 15.9%, almost doubling Opus 4's score on this test.
- In real-time: Thanks to deep integration with X and Tesla sensor data, Grok-4 excels where both reasoning and up-to-date data are needed – from market analysis to fleet technical support.
It is important to understand that these records come at a cost: Grok-4 Heavy is noticeably heavier and slower than GPT-5.1 and Gemini 2.5 Pro, and it will not always be the best choice for "everyday chat." However, where extreme depth of reasoning and tight integration with tools are needed, it is currently one of the main contenders for the crown.
So, the landscape has been defined. We have the brilliant mathematician and coder GPT-5.1, the marathoner Gemini 2.5 Pro, capable of processing gigabytes of multimedia data, the reliable corporate expert Claude Opus 4.1, and the extreme "olympic brain" Grok-4 Heavy for tasks at the frontier of human capabilities. The theory of unification has led us to the practice of specialization: instead of one "best model," we have received a whole set of tools, each of which is optimal in its zone. But so far, we have mostly talked about static data and offline tasks. What happens when time seriously enters the game – in sound and video?

The Magic of Audio and Video. From Static to Dynamic
We have just seen how industry titans solve complex problems with code, medical texts, and giant databases. But all of this, for the most part, was working with static data. What about modalities that have a fourth dimension – time? How does our simple and elegant next-token prediction principle cope with the chaos of a moving image or a continuous stream of human speech?
The answer, strangely enough, we already know. The extension of the NTP paradigm to dynamic modalities became possible not thanks to some new, revolutionary architecture, but thanks to those very breakthroughs in tokenization that we discussed in the third part of the article. If text is a string of words, then video is simply a very, very long string of "frame" tokens. The model's task remains the same: to continue or understand this giant string, as if it were one enormous sentence.
The main difficulty, of course, was to create a tokenizer capable of capturing not only spatial information (what is where in the frame) but also temporal information (how it changes). And here, MAGViT-v2 again comes to the forefront. Its architecture, built on "causal 3D CNN," is initially designed to work not with a flat picture (x, y) but with a three-dimensional "chunk" of video (x, y, t), capturing movement and changes over time.
But the real breakthrough of MAGViT-v2 is that it uses a "common vocabulary of tokens" for images and video. This is an incredibly elegant solution. Models no longer need to learn two different "languages" for static and dynamic data. A token encoding a "golden retriever" in a static photograph can be reused to encode the same retriever running on a beach in a video. This is unification in action.
This very approach allowed NTP-based models to invade territory where other paradigms seemed to reign supreme.
- Models from the Emu3 / Emu3.5 line generate video exactly like a language model: causally, by predicting the next token in a video sequence and gradually "playing" the video forward frame by frame.
- This is in direct contrast to the approach of models like Sora, which are "video diffusion models." They start with a noisy latent representation and iteratively "clean" it until a sequence of realistic frames emerges from the noise.
In autumn 2025, Sora 2 appeared. Essentially, it's the same diffusion text-to-video model, but with important evolutionary upgrades:
- native generation of synchronous audio (speech, background, effects), so videos are no longer "silent" and do not require external sound design;
- noticeably more plausible physics and movement: fewer "floating" objects, strange collisions, and violations of the laws of mechanics;
- more accurate prompt following and improved control – from camera and style to character continuity in multi-shot scenes.
It would seem like two completely different approaches. But the facts are stubborn: in the article introducing MAGViT-v2, it is written in black and white that language models equipped with this tokenizer outperform diffusion models on standard video generation (Kinetics) and image generation (ImageNet) benchmarks. Good old NTP proved competitive even here.
Of course, a lot of engineering tricks are hidden behind the scenes. For example, for the model to understand the order of frames in a long video, advanced positional encoding schemes are used, such as "Interleaved-MRoPE" in the Qwen3-VL model, which encode information simultaneously across time, width, and height of the frame. And on the horizon, the next goal is already looming – universal tokenizers like "Harmonizer", capable of seamlessly transforming text, audio, video, and even sensor data into a single stream of tokens.
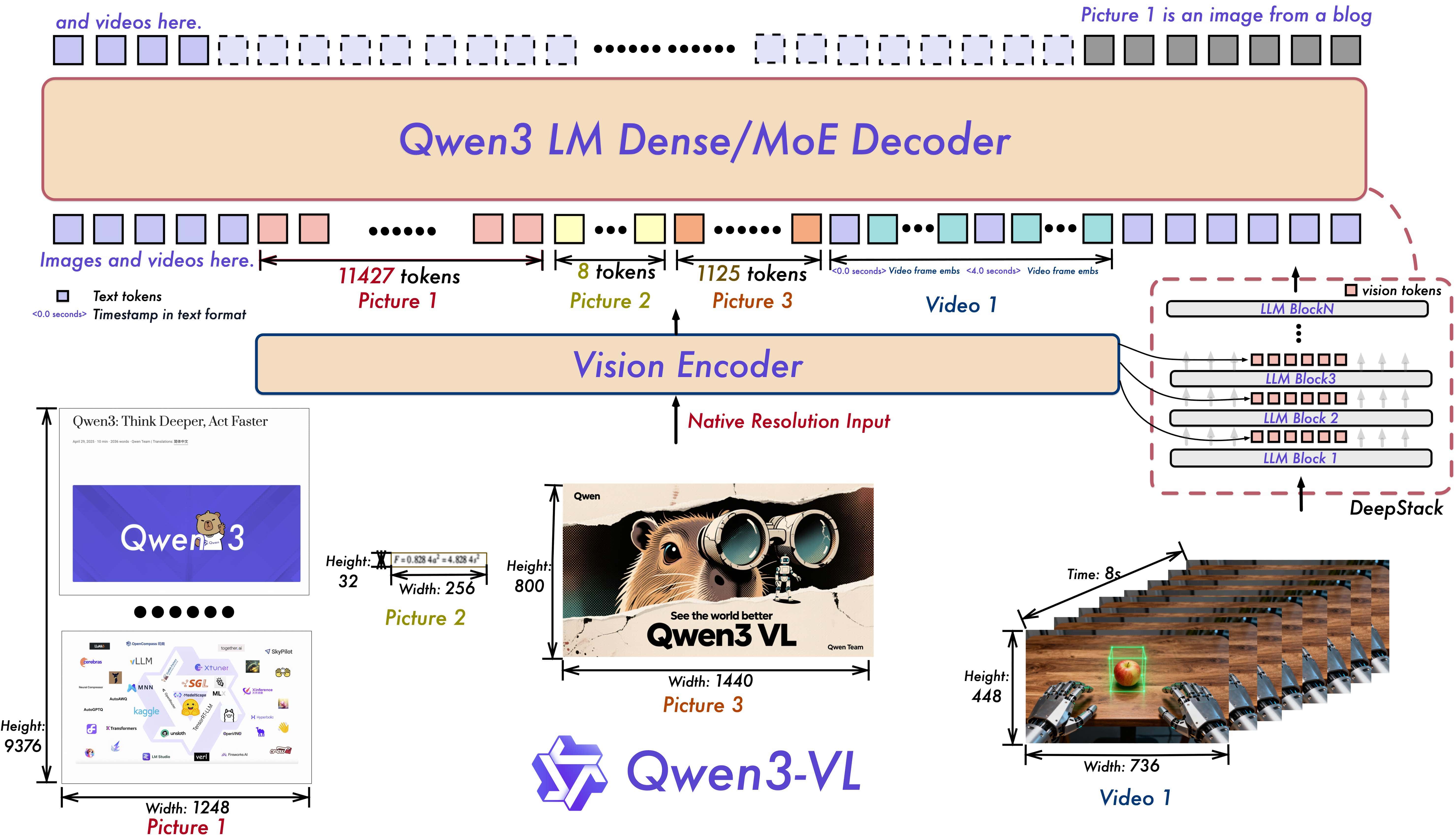
But the main idea remains unchanged. When Emu3 generates a minute-long video, under the hood it really predicts tens, or even hundreds of thousands of visual tokens in a row – all the same next-token engine, just in a spatiotemporal format. Sora 2 goes a different way: it performs dozens of steps of diffusion denoising on a huge tensor to always approach a plausible video with consistent physics, light, and motion. But in both cases, the complex machinery is controlled by a familiar probabilistic model, not something mystical – and this brings us to the deepest and most uncomfortable question.

The Philosophical Turn. Is NTP enough for AGI?
After all this splendor – models solving PhD-level problems, writing code better than humans, and analyzing multi-hour videos – an almost heretical question arises. If next token prediction has proven so powerful, isn't it the universal principle that will ultimately lead us to AGI? It seems we are on the threshold, but precisely here, at the peak of technological optimism, I stumbled upon a number of 2025 studies that force us to take a step back and ask some uncomfortable questions.
Despite all these additions on top of NTP (RLHF, tools, TTC), the NTP paradigm itself in its pure form demonstrates fundamental limitations. Today's models are brilliant improvisers. They can pick up and continue almost any "melody" of text, code, or images that you give them. But writing a well-structured symphony from scratch with a clear internal structure and long-term design is still very difficult for them. They are masters of recombining patterns extracted from giant volumes of data, but they lack a true understanding of the world that would allow them to go beyond this data and generate genuinely new ideas.
And these are not just philosophical musings. New, tricky benchmarks from 2025 have revealed two deep cracks in the monolith of NTP.
Crack one: Spatial reasoning. A new benchmark SpatialViz-Bench (September 2025) was created not to test how models recognize objects, but to evaluate their "visual imagination": the ability to mentally manipulate 3D objects, understand their relative positions, and physical interactions. A typical task in such a benchmark is to mentally rotate an object, understand if it will be visible from another point, or predict which cube will be on top after a series of rotations. And the results, to put it mildly, are sobering. Researchers found a sharp drop in performance when transitioning from 2D to 3D. But the most shocking conclusion I saw in this report is different: many open-source models showed a degradation in performance from Chain-of-Thought (CoT) style prompting. Think about it. We ask the model to "reason aloud" to improve the answer, and it starts making even more mistakes – a sign that it brilliantly copies the form of reasoning but lacks true spatial imagination.
Crack two: Embodied AI. It's one thing to reason about physics in a text chat, and quite another to plan and execute a sequence of actions for a robot to pick up a cup from a table. For example, an LLM can perfectly describe how to carefully place a glass on a table, but a real robot controlled by this model will still knock it over due to errors in perception, trajectory planning, and motor control. It's no surprise that workshops on Embodied AI at major 2025 conferences, such as NeurIPS and CVPR, became some of the most popular. This is an industry acknowledgment that a chasm lies between the digital intelligence of LLMs and the physical intelligence of robots.
So, is Next Token Prediction a dead end? Not at all. It's more an acknowledgment that NTP is an incredibly powerful, but likely not the only necessary component. And the reaction of the industry and the scientific community has already followed two main directions.
- The pragmatic path: Test-Time Compute (TTC). Instead of relying on one quick, "intuitive" answer, this paradigm allows the model to "think longer" and allocate more computation during operation. And you already know its commercial implementations. This is the very "Adaptive Reasoning" in GPT-5.1 and "multi-agent parallel test-time compute" in Grok-4 Heavy. The industry is already building "crutches" to bypass the inherent impulsiveness of NTP.
- The fundamental path: Neuro-symbolic AI. This is a deeper research direction that seeks to combine the strengths of statistical AI (learning from data) with the power of structured, symbolic reasoning. The idea is to give models not only intuition based on patterns but also a strict logical apparatus. In the simplest scenario, an LLM is responsible for interpreting the task and generating candidates, while a strict symbolic core (e.g., a SAT/SMT solver or a logical planner) checks their correctness and constructs a formal solution.
If GPT-5.1 is already winning gold at math olympiads but still gets confused in the three-dimensional world and long-term plans, doesn't that mean that NTP is just the foundation, not the whole house called AGI? And it seems we are now entering an era where new, more complex floors are being built on this foundation.

A Look into the Future. The Era of Omni-models: Cloud and On-device
So, we have established that Next Token Prediction is a powerful foundation, but to build true AGI, new, more complex structures like Test-Time Compute are already being erected upon it. This is a philosophical look at tomorrow. But what does this foundation, with all its new reinforcements, give us right here and now, at the end of 2025?
The answer is a surprisingly mature and clearly segmented market. The era when one model tried to be "the best at everything" has ended. Instead, we have a vibrant, two-pole world: on one side, hyperspecialized flagships in the cloud, and on the other, a powerful and democratic revolution on "your own hardware."
Cloud Flagships: Choosing a Machine from the Fleet
Instead of a race for the single "king of the hill," we are observing the formation of a "cloud fleet," where each flagship model has a clearly defined strategic niche. It's no longer a question of "which model is better?", but a question of "which portfolio of models is optimal for my stack of tasks?". We have already analyzed their individual strengths through benchmarks; now let's look at this from a market strategy perspective.
- GPT-5.1 is OpenAI's bet on agentic workflows. Its dominance in coding and complex reasoning is not accidental, but a deliberate development towards creating autonomous systems capable of performing multi-step tasks. Adaptive Reasoning is the mechanism that makes such agents economically viable. By choosing GPT-5.1, you are investing in an ecosystem for automating complex processes.
A typical stack: GPT-5.1 handles complex tickets from Jira and GitHub, corrects code, runs tests itself through connected tools, and prepares a report for the developer. In business scenarios, the same scheme works for automating contract approvals, preparing analytical notes, and multi-step financial calculations based on internal reports. - Gemini 2.5 Pro is Google's moat dug on data scale. Their key advantage is the ability to process giant, multimodal streams of information. A context of 1-2 million tokens and native video analysis are not just features, but a strategic asset for companies whose business is built on analyzing huge, unstructured datasets – from media archives to medical records.
In practice, this looks like a media holding feeding Gemini years of broadcast archives and asking it to find recurring themes, sentiment, and speaker quotes for any query. In medicine, the model is connected to PACS, EHR, and research databases – it can simultaneously account for text conclusions, images, excerpts, and multi-hour consultation recordings, providing the doctor with a concise answer, including the source of each conclusion. - Claude Opus 4.1 is Anthropic's focus on the enterprise trust layer. In a world where AI hallucinations and unpredictability are the main barriers to adoption in regulated industries (finance, law, medicine), Claude positions itself as the most reliable and predictable tool. Its strength is not in benchmark records, but in minimizing business risks.
A typical use case is a legal or compliance department of a large company that runs draft contracts, internal policies, and correspondence with regulators through Claude, receiving notes on risks, inconsistencies, and debatable wording. In support services, Claude is used as a "second opinion" on already generated responses: it cleans up aggressive phrasing, monitors compliance with regulatory requirements and corporate tone. - Grok-4 Heavy is xAI's play in the field of real-time intelligence. Its uniqueness lies not only in its mathematical power but also in its native integration with live, dynamic data streams from X and Tesla. This model is not for writing poetry, but for making decisions in conditions of constantly changing information, making it an ideal tool for trading, analyzing market sentiment, and scientific research.
Real scenarios are teams that need a combination of "deep reasoning + live data." Trading firms use Grok-4 Heavy to analyze the X feed, company reports, and market telemetry in real time, building hypotheses and immediately testing them against historical data. Tesla engineers use it as an "analyst's brain" that can parse large logs from the autopilot, identify anomalies in machine behavior, and suggest changes to algorithms.
In 2023, we debated who was better – GPT-4 or Claude 2. In late 2025, a competent CTO builds a multimodal stack where GPT-5.1 is responsible for development, Gemini 2.5 for data analytics, and Claude 4.1 for customer interaction and legal checks. Welcome to the era of portfolio AI strategies.
Open-weight Revolution: Multimodal Models in Your Garage
But while cloud giants built their elite fleets, another, no less important revolution was happening in parallel, in enthusiast garages and labs around the world. Open-weight models stopped being "cheap alternatives" and in some areas became trendsetters themselves.
If GPT-5.1 is renting a Ferrari with a driver by subscription, then Qwen3-VL or InternVL 3.5 is your own Tesla in your garage: a little less ostentatious luxury, but complete freedom of route, tuning, and, most importantly, privacy.
- Qwen3-VL (Alibaba): A true Swiss Army knife. Native context up to 1M tokens, advanced OCR in 32 languages, and most importantly, a "Visual Agent" function capable of controlling your PC or smartphone's graphical interface.
In real tasks, Qwen3-VL is conveniently placed next to corporate document repositories: it parses scanned contracts, presentations, tables, and email attachments without sending them to an external cloud. In visual agent mode, it is connected to internal web panels and desktop applications: the model itself clicks buttons, fills out forms, and collects the necessary reports, working as an automated office employee on your PC or server. - LLaMA 4 Scout (Meta): A context monster. This model offers an unprecedented window of 10 million tokens, allowing it to analyze entire code repositories in one pass, and can still run on a single H100 GPU.
A typical local use scenario is analyzing a monorepo or large legacy code: Scout keeps the entire module (or even several services) in context, answers questions about architecture, finds duplicates, and suggests a refactoring plan. Outside of development, it is placed next to logging and monitoring systems: the model gains access to giant logs from months of operation and helps find non-trivial patterns and root causes of incidents. - InternVL 3.5 (OpenGVLab): Catching up with the champion. This model is openly positioned as "bridging the performance gap with GPT-5" and also has GUI-agent capabilities, creating healthy competition in the open-source community.
In production, InternVL 3.5 performs well where it is necessary to simultaneously understand text and images: from retail (reading price tags and displays, checking compliance of display layouts with planograms) to technical support (parsing error screenshots and user screen videos). Thanks to its GUI agent capabilities, it is used as "eyes and hands" for internal admin panels: the model itself goes to the necessary sections, checks system statuses, and performs routine operations according to regulations.
And these are not just theoretical studies. Thanks to tools like vLLM, SGLang, llama.cpp, and Ollama, deploying these systems has become a trivial task. Now you can run Qwen3-VL-8B or InternVL 3.5-8B on a single consumer RTX 4090/5090 or in the cloud and get a multimodal assistant that understands text, pictures, and video – without a single request to an external API.
In real systems, a hybrid approach almost always wins: the cloud handles the heaviest reasoning tasks and rare queries, while local models serve private data, online prompts, and part of the RAG contour. In practice, this looks like heavy, rare queries going to GPT-5.1, Gemini, or Grok-4, while everyday tasks – searching internal data, parsing screenshots, helping with code – are handled by Qwen3-VL, LLaMA 4 Scout, or InternVL 3.5, running directly on the company's server or a developer's workstation.
The world of AI has finally split into two powerful streams, and the choice between them is no longer a matter of "better/worse," but a strategic decision based on the balance between power, control, cost, and privacy.

Key Takeaways
Here we are at the end of our journey. In just five years, we have gone from a "zoo" of disparate, isolated models like BERT and ResNet to a unified, elegant paradigm that permeates the entire landscape of artificial intelligence in 2025. We have seen how this unification has given rise to both hyperspecialized cloud giants and incredibly powerful open-weight models that can be run in your own "garage."
If we condense this complex history into a few crystal-clear theses that can be retold to a colleague over coffee, they would sound like this:
- Everything is tokens and next-token prediction (NTP). The simple idea of "continue the sequence" proved so universal that it could become the basis for working with text, code, images, audio, and video. Moreover, this paradigm proved powerful enough that, given a good "translator," NTP-based language models were able to reach and in some benchmarks surpass diffusion models in generating visual content.
- Universal engine = Transformer + good tokenizer. The technical heart of this revolution was the combination of two key components. First, the Transformer architecture itself, which proved to be "data-neutral" by nature and capable of finding connections in any sequence. Second, breakthroughs in discrete tokenization (such as MAGViT-v2), which taught us how to transform the real world into semantically rich sequences understandable to the transformer. The quality of "vision" and "hearing" of modern models is largely determined by the quality of their tokenizers and training data – with the same transformer, a good tokenizer provides a qualitative leap.
- The future is a hybrid of cloud and local solutions. The 2025 landscape has finally taken shape. This is not a world of one winner, but an ecosystem where there is room for both cloud Omni-models offering state-of-the-art solutions for niche tasks (Grok-4's mathematics, Gemini 2.5's video analysis), and for powerful open-weight systems (LLaMA 4 with 10M context, Qwen3-VL with GUI agent and advanced multimodal "vision"), which provide unprecedented control, privacy, and customization capabilities. Choosing a stack is now not about finding the "best" model, but about consciously building a hybrid architecture.
Perhaps Next Token Prediction is not only a way to complete text, but the germ of a universal "pattern language" that both machines and humans will one day learn to think in. The only question is what we will build with this language next.
Stay curious.


