MiniMax-M1: Dissecting an Architecture That Breaks Scaling Laws (and Our VRAM)
Author: Aleksei Beltiukov

In recent years, we've witnessed a true arms race in the world of LLMs. The main motto is "Bigger, Higher, Stronger!" More parameters, more data, more computational power. But this race runs into a fundamental wall, known to anyone who has tried to run something more complex than BERT on their laptop: the tyranny of quadratic complexity. This refers to the attention mechanism in the Transformer architecture, where computational costs and memory requirements grow as O(n²), where n is the sequence length.
Every new token in the context makes the next step more expensive. This limits not only the maximum context window size but, more critically, the length of the model's "thought process" — its ability to generate long, sequential Chain-of-Thought reasoning.
And so, while delving into recent publications, I came across a paper that proposes not just breaking through this barrier, but elegantly circumventing it through architectural ingenuity. We're talking about the MiniMax-M1 model. Judging by the presented data, this is the first open-weight model of such scale to challenge the status quo. The claimed characteristics are impressive: native support for 1 million input tokens, the ability to generate reasoning chains up to 80,000 output tokens, all while consuming only 25% FLOPs compared to counterparts like DeepSeek R1 on long-generation tasks.
But the most intriguing aspect is the economics. Training M1 cost approximately $534,700, while the costs for the comparably ambitious DeepSeek-R1 are estimated at $5-6 million (though some sources claim $1.3 billion was spent). This is an order of magnitude difference.
How did they achieve this? What engineering breakthroughs, and no less importantly, what compromises lie behind these numbers? I delved into their technical report, analyzed community discussions, and am ready to present a detailed breakdown of this machine to understand whether it is a harbinger of a new era in LLM design or just an interesting but niche experiment.

Architectural Foundation – "Lightning Attention" and Hybrid MoE
At the core of any LLM lies its architecture. While most modern giants are essentially scaled versions of the classic Transformer, the creators of MiniMax-M1 took a different path. Their solution is a hybrid, combining three key ideas: Mixture-of-Experts (MoE), standard Softmax Attention, and most interestingly, linear attention implemented as Lightning Attention.
The Problem with Standard Attention. Imagine a meeting where every participant (token) has to listen to every other participant to understand the overall picture. If there are 10 participants, that's 100 "conversations." If there are 1000, it's already a million. This is quadratic complexity. It's excellent at capturing global dependencies in text but becomes unmanageable with long sequences.
Linear Attention as an Alternative. Linear attention, and specifically its I/O-optimized implementation Lightning Attention, works on a different principle. Instead of "everyone with everyone," it uses more efficient mechanisms to reduce complexity to linear — O(n). This is similar to moving from broadcast radio communication to a structured IP network, where messages are routed rather than sent to everyone. The price of such efficiency is potentially less precise capture of complex, long-range dependencies in the data compared to softmax attention.
MiniMax-M1's Hybrid Approach. And this is where the key engineering decision lies. Instead of completely abandoning time-tested softmax attention, they created a hybrid structure. According to the description, the architecture looks like this: for every seven Transnormer blocks with Lightning Attention, there is one block of classic Transformer with Softmax Attention.
I see this as a very pragmatic compromise. The model gains enormous efficiency on most layers, but periodically "cleans up" and globalizes information using a full attention mechanism. It's like having a superluminal engine for travel between star systems (Lightning Attention), but for precise orbital maneuvers, you'd engage proven and accurate maneuvering thrusters (Softmax Attention).
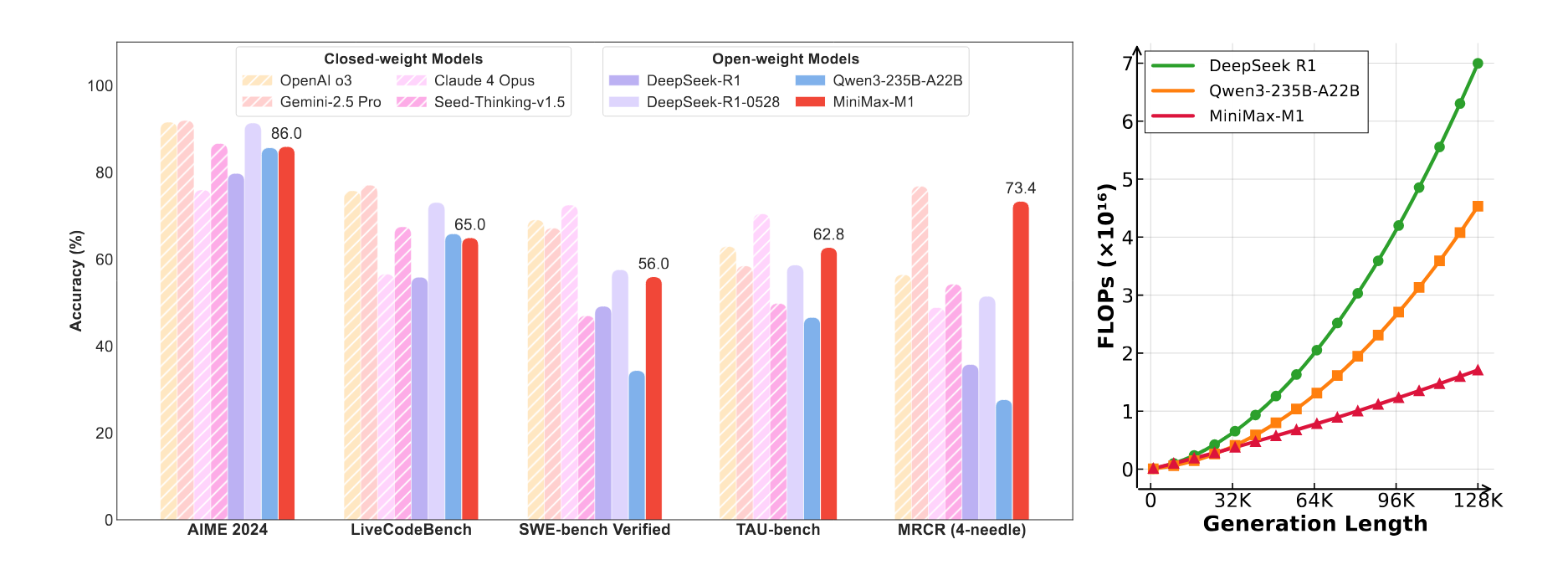
Add to this the Mixture-of-Experts (MoE) architecture, where out of 456 billion total parameters, only 45.9 billion are active at any given moment, and we get a monster that is, on one hand, enormous, and on the other, surprisingly computationally efficient. It is this architecture that allows the model not to choke when generating tens of thousands of tokens and to process gigantic input contexts. The graph showing FLOPs dependence on generation length speaks for itself: where DeepSeek R1 begins to consume astronomical resources, M1 moves along a much gentler curve.

Training the Beast – A New Look at RL with CISPO
Having an efficient architecture is only half the battle. For a model to learn to "think," i.e., solve complex problems, it needs to be properly trained. Today, Reinforcement Learning (RL) is the gold standard for this.
Standard algorithms, such as PPO (Proximal Policy Optimization) and its derivatives (e.g., GRPO), have one peculiarity that, as MiniMax researchers discovered, became a stumbling block for them. These algorithms use a clipping mechanism to stabilize training. The problem is that in the early stages of training, the model begins to discover new, useful reasoning patterns, often expressed in "reflexive" tokens ("Hmm, let's think...", "Let me check again", "However"). These tokens are rare, and the base model assigns them a low probability.
When the PPO algorithm sees such a low-probability but useful token, the ratio of probabilities between the new and old policies (r_t(θ)) for this token becomes very large. The clipping mechanism perceives this as an outlier and "cuts off" the gradient update. As a result, as the authors write, the model is effectively penalized for discovering new, effective reasoning paths.
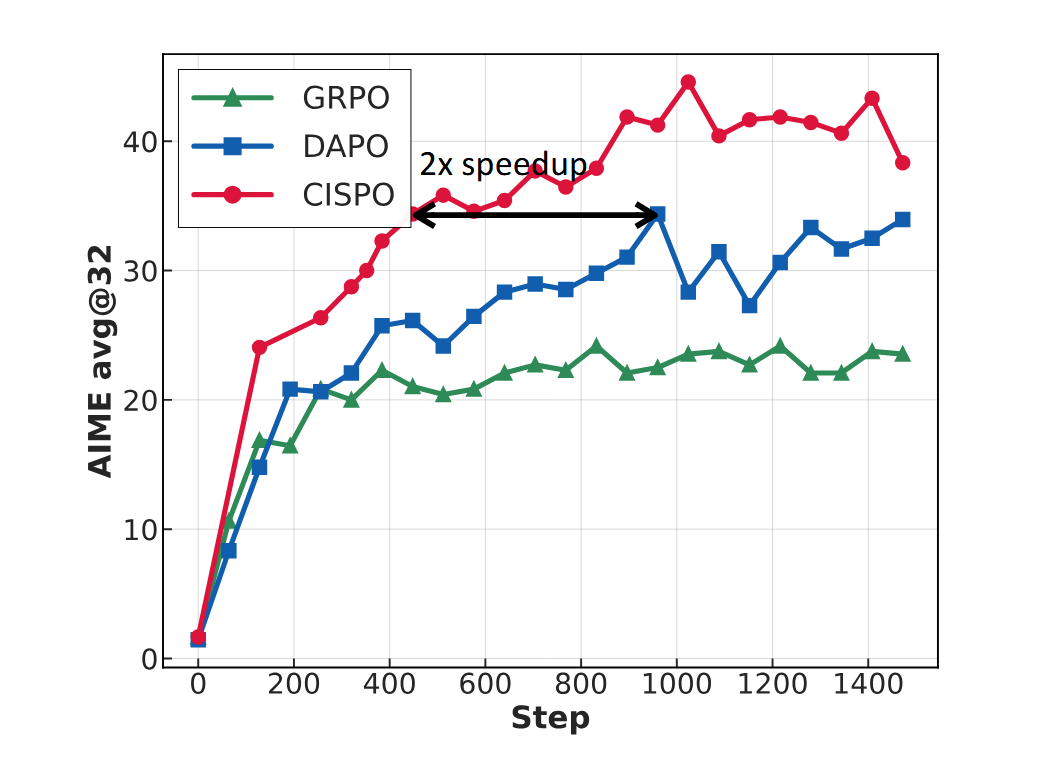
The Solution: CISPO. The MiniMax team proposed their algorithm — CISPO (Clipped Importance-Sampling-weight Policy Optimization). The idea is elegant: instead of clipping the gradient update itself, CISPO clips the importance sampling weights.
The formula looks like this:
ˆr_i,t(θ) = clip( r_i,t(θ), 1 - ε_low, 1 + ε_high )
This means that even if a token was very unexpected, its contribution to the gradient is not nullified but only softly constrained. All tokens continue to contribute to the training. The effectiveness of this approach is confirmed by their internal tests: on the AIME 2024 mathematical reasoning task, training the Qwen2.5-32B model, CISPO achieved the same performance as the advanced DAPO algorithm, but in half the number of training steps.

In the Engineering Trenches – Real Problems and Their Solutions
No major project is without its challenges. What I particularly appreciate about the report is the honest description of the problems the team encountered.
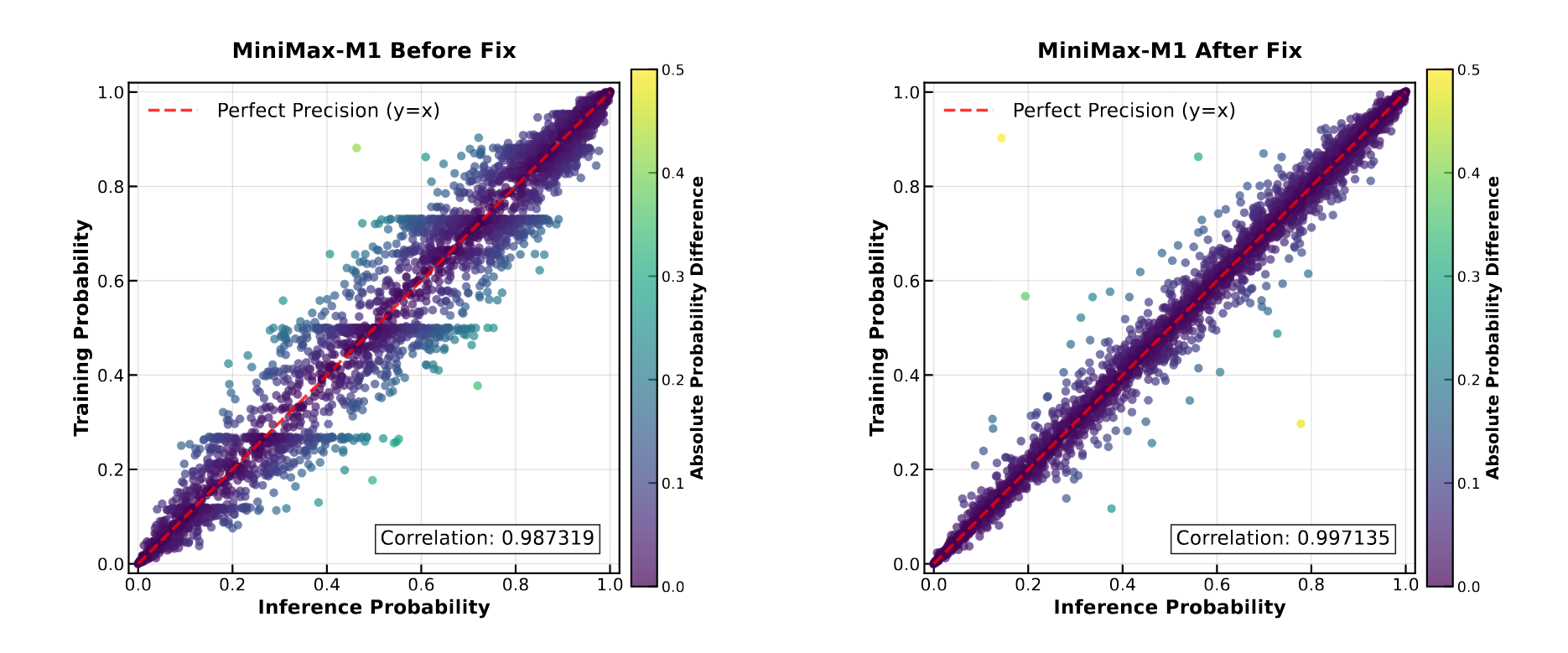
Problem #1: Numerical Precision Mismatch. During RL training, the team noticed that token probabilities in training mode differed significantly from probabilities in inference mode. The correlation was around 0.987, although it should have been ideal. The culprit turned out to be high-magnitude activations in the last layer of the model (LM head). Standard computational precision (FP16/BF16) couldn't handle it, leading to rounding errors. Solution: performing computations in the LM head using FP32, which raised the correlation to 0.997.
Problem #2: Pathological Repetition Cycles. The model sometimes fell into a "rut" — it started generating meaningless sequences of repeating tokens, creating enormous gradients. Solution: a heuristic based on the observation that in such cycles, the model's confidence in each token skyrockets. Generation is forcibly stopped if 3000 consecutive tokens have a probability above 0.99.
Problem #3: The Unruly AdamW Optimizer. Training proved extremely sensitive to AdamW hyperparameters. The team discovered that M1's gradients have a colossal dynamic range (from 1e-18 to 1e-5), and the correlation between gradients on adjacent iterations is weak. This required meticulous tuning: β₁=0.9, β₂=0.95, eps=1e-15. Standard values led to divergence. This is a valuable lesson for anyone working with non-standard architectures.

Reality – Benchmarks, Feedback, and Practical Limitations
So, we have a unique architecture, a new training algorithm, and a set of engineering solutions. What can this machine do in practice? The picture is nuanced.
Strengths: A Marathon Specialist
M1's strength is revealed where its main superpower is required — long-form reasoning and handling huge contexts.
- Software Engineering (SWE-bench): A result of 56.0% is comparable to the best models, which is not surprising, as RL training took place in a sandbox with actual code execution.
- Long Context (OpenAI-MRCR): On tasks involving fact extraction from 128k tokens, M1-80k shows 73.4%, surpassing OpenAI o3 and Claude 4 Opus.
- Agentic Tool Use (TAU-bench): In API usage tasks, M1-40k outperforms all, including Gemini 2.5 Pro, highlighting the importance of long reasoning for planning.
Weaknesses: Not a Universal Soldier
However, when looking at more general tasks, the picture changes. M1 is not a universal genius, but a narrow specialist.
MiniMax-M1 Comparative Performance Table. Source: MiniMax-AI GitHub
| Task | OpenAI o3 | Gemini 2.5 Pro | DeepSeek-R1-0528 | MiniMax-M1-80k |
|---|---|---|---|---|
| AIME 2024 (Math) | 91.6 | 92.0 | 91.4 | 86.0 |
| SWE-bench (Coding) | 69.1 | 67.2 | 57.6 | 56.0 |
| OpenAI-MRCR (128k) | 56.5 | 76.8 | 51.5 | 73.4 |
| SimpleQA (Facts) | 49.4 | 54.0 | 27.8 | 18.5 |
| HLE (General Knowledge) | 20.3 | 21.6 | 17.7 | 8.4 |
| MultiChallenge (Assistant) | 56.5 | 51.8 | 45.0 | 44.7 |
The data speaks for itself:
- Factual Accuracy (SimpleQA): Only 18.5% versus 54.0% for Gemini 2.5 Pro. The model is not strong at quickly retrieving simple facts.
- General Knowledge (HLE): A result of 8.4% versus 21.6% for Gemini 2.5 Pro shows clear gaps in its erudition.
- Creativity: According to user feedback, the quality of creative writing significantly lags behind models from OpenAI or Anthropic. Responses are often described as "robotic" and lacking creative spark.
Practical Barriers: Prepare Your VRAM
Efficiency in FLOPs does not always translate to accessibility. Judging by discussions, M1 is a very demanding beast.
- High VRAM Requirements: Even for short contexts, the model needs serious amounts of video memory, making it virtually inaccessible for running on consumer hardware.
- Lack of GGUF: Currently, there is no support for the popular GGUF format, which greatly complicates local deployment for enthusiasts and small teams.
It is important to note that the model is fully open under the Apache 2.0 license and available for testing on Hugging Face Spaces, which is a huge plus for the research community.
Economics and a Paradigm Shift
Perhaps the most important aspect of the M1 story is not just the architecture, but the economics and philosophy behind it.
The comparison of training costs (~$534k for M1 versus ~$5-6M for DeepSeek-R1) is not just about savings. It's a demonstration that clever design can be an order of magnitude more efficient than brute force.
This approach perfectly aligns with the current industry trend. Analysts from Greyhound Research note that 58% of enterprise AI solution customers now prioritize model efficiency over peak accuracy. Companies are tired of giant, slow, and expensive models. They need workhorses that solve specific tasks in an economically viable way. M1 is a prime example of this new wave.

The Imperfect Future Is Already Here
After analyzing MiniMax-M1, I've concluded that it's not just another universal SOTA-killer. It's something more interesting and, perhaps, more important in the long run — a brilliant, albeit imperfect, specialist.
This is an architecture designed for marathon distances: code analysis, working with gigantic documents, and building long, multi-step reasoning chains. In these niches, it performs excellently, surpassing even more renowned competitors. But don't ask it to write a sonnet or quickly answer a trivial question — it will disappoint you.
The key takeaway for me is that the era of thoughtless "brute-force" scaling might be giving way to an era of architectural inventiveness. Instead of building ever more gigantic and power-hungry computing machines based on the classic Transformer, M1 proves that outstanding results can be achieved through clever hybrid design that consciously makes compromises.
It is precisely such architectures, in my opinion, that will become the foundation for truly useful AI agents capable of automating complex workflows, not just answering questions in a chat. MiniMax-M1 has shown that a path beyond the tyranny of quadratic complexity exists. And it's incredibly intriguing.
I'm always interested in how theory intersects with practice. Have you encountered tasks in your work where a specialized model like M1 might be more useful than a universal assistant?
I'm especially curious about the experience of those who run large models locally. Today, many are building GPU rigs to work with LLMs at home or at work. If you have such experience, please share how you solve the VRAM problem, what GPUs you use? And how critical is the lack of ready-made quantized versions, like GGUF, for models like M1 for you?
And finally, where do you think this whole story with local and open-source models is heading? Towards giant universals or towards a set of efficient but highly specialized tools?


