Prompt caching: оптимизация, которая наказывает молчанием
Автор: Алексей Бельтюков
TL;DR: Prompt caching переиспользует уже обработанное начало промпта: провайдер сохраняет внутренние вычисления (KV-тензоры), и повторные входные токены стоят примерно в 10 раз дешевле, а ответ приходит быстрее. Кэш срабатывает только при точном совпадении префикса, отсюда главное правило: стабильное в начало, изменчивое в хвост. Поломка не даёт ошибок, её видно только в usage-полях API.
Из всех способов сэкономить на работе с LLM prompt caching самый коварный. Сложным его не назовёшь, дело в другом: он тихий. Почти любая оптимизация, если ты её сломал, даёт о себе знать: падает тест, краснеет лог, валится метрика. Кэш так не делает. Он не падает с ошибкой, он просто молча перестаёт срабатывать. И единственное, что меняется, это счёт в конце месяца и пара лишних секунд на каждый ответ.

Я собираю своего агента поверх моделей OpenAI и довольно долго про кэш вообще не думал. У OpenAI он включается сам, автоматически, без единого флага, и за запись денег не берёт. Идеальные условия, чтобы расслабиться. Кажется, думать не о чем, провайдер всё сделает за тебя. Ловушка ровно в этом удобстве: автоматический кэш снимает с тебя работу до того момента, когда ты сам, из лучших побуждений, добавляешь в промпт пару полезных строчек и тихо его ломаешь. Никто тебе про это не скажет.
Хорошая новость: вся дисциплина кэша сводится к одному простому правилу, стабильное в начало, изменчивое в хвост. Плохая: правило хрупкое, нарушить его легко, а на агентах цена ошибки выше, чем кажется. Дальше разберём, что такое prompt caching на самом деле, чем отличаются три провайдера, как выглядит правильно собранный промпт и как убедиться, что кэш реально работает, а не числится в документации.
Почему на агентах кэш это воздух, а не бонус
Чтобы понять, почему кэш для агента критичен, надо вспомнить, как агент устроен. Сама модель ничего не помнит, она stateless. Память держит обвязка. Каждый ход она заново собирает в один запрос системные инструкции, описания всех инструментов, всю историю прошлых действий и свежий ввод. Даже когда состояние хранит сам провайдер, как Responses API у OpenAI с его previous_response_id, памяти у модели не прибавляется: диалог лежит у сервиса, а контекст всё равно прочитывается заново на каждом ходу. Такой режим экономит сеть, но не prefill, поэтому кэш он не заменяет. Большая часть этого контекста, как формулирует Lance Martin, от хода к ходу одна и та же, и без кэша ты платишь за неё целиком каждый раз заново. Почему такая "память" это дорогая вычислительная работа, а не пассивный склад, я разбирал в анатомии памяти LLM и инженерии контекста.

Насколько перекошен баланс, лучше всего показывает Manus: у их агента отношение входных токенов к выходным держится около 100 к 1. На один короткий ответ приходятся десятки тысяч токенов контекста, и почти весь он повторяется ход за ходом. Для обычного чата это мелочь. Для агента вроде моего, который крутится в цикле по двадцать-тридцать ходов, основная статья расходов.
Вот сюда и бьёт кэш. У всех трёх крупных провайдеров чтение из кэша стоит примерно в десять раз дешевле обычного входного токена. На июнь 2026 вход в GPT-5.4 у OpenAI стоит $2.50 за миллион токенов, а тот же токен из кэша $0.25; у Anthropic для Opus 4.8 это $5.00 против $0.50; у Google для Gemini 3.1 Pro $2.00 против $0.20. И флагманы дорожают: новый GPT-5.5 у OpenAI поднялся до $5.00 за миллион входных токенов, вровень с Opus и вдвое к GPT-5.4. Но какой бы ни была абсолютная цифра, кэш режет именно её, и когда на входе сто токенов на каждый токен ответа, эта скидка на повторяющейся сотне меняет экономику продукта целиком.
С кэшем так же резко падает и латенси: Anthropic заявляет снижение времени ответа до 85% на длинных повторяющихся префиксах, OpenAI про 80%. Это разница между агентом, который отвечает мгновенно, и тем, что думает по десять секунд перед каждым ходом, заново перечитывая весь контекст.
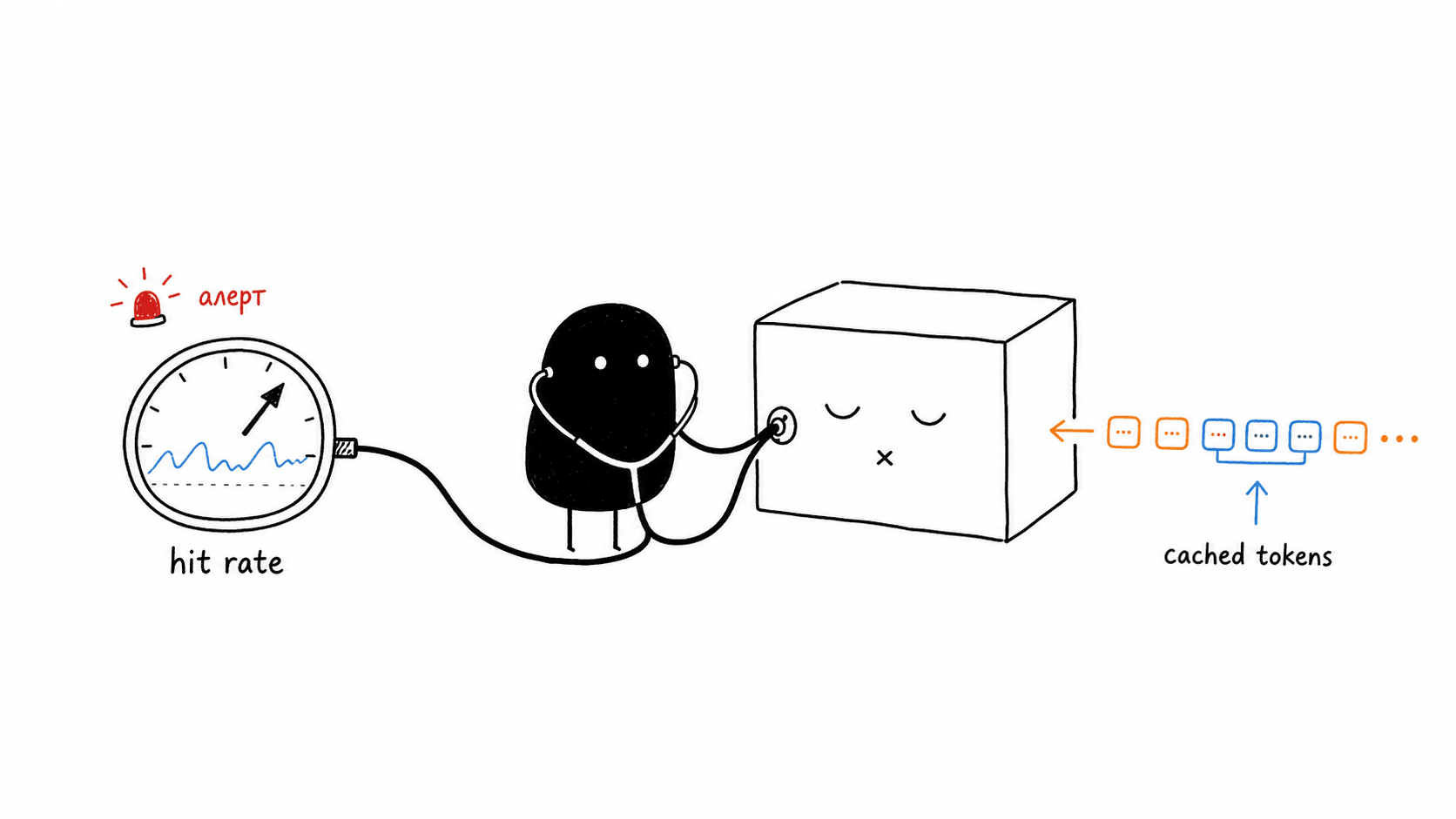
И весь этот перерасход, если кэш не сработал, утекает бесшумно: агент отвечает правильно, тесты зелёные, ошибок нет, просто каждый ход обходится кратно дороже и тянется дольше. Поэтому для продукта на агентах cache hit rate, доля входных токенов из кэша, перестаёт быть тщеславной цифрой из дашборда и становится метрикой, от которой зависит, сходится ли юнит-экономика. Про то, как вообще считается экономика продуктов на AI-агентах, у меня есть отдельный разбор.
Покажу на своих счетах. Мой агент крутится на gpt-5.5, и за последние недели в среднем уходит $50–70 в день. Это с работающим кэшем: у OpenAI он включён по умолчанию.
Agent stateless, поэтому каждый ход harness шлёт заново весь контекст: системный промпт, инструменты, всю историю и свежий ввод. Запрос не уменьшается, он растёт ход от хода. Кэш тут означает, что всё, что модель уже видела на прошлом ходу, читается из кэша за десятую часть цены, а по полной я плачу только за новые токены хода, тысяч десять-двадцать.
Насколько кэш тащит счёт, видно прямо из биллинга. Если поделить дневной счёт на все токены за день, мой средний токен на gpt-5.5 выходит примерно в $0.78 за миллион. Чтение из кэша стоит $0.50, обычный вход $5, и то, что среднее почти упёрлось в цену кэша, значит главное: львиная доля токенов уходит дешёвыми чтениями префикса. Выключи кэш, и эта масса пойдёт по $5, а счёт вырастет в районе семи раз. Обычный день за полсотни долларов стал бы днём за несколько сотен, при том же поведении агента: те же ответы, зелёные тесты, ноль ошибок в логах.
То же самое в повседневном кодинге на Claude. На Opus средний токен выходит около $0.88 за миллион при той же цене чтения $0.50 и входе $5, хотя у Anthropic ещё и запись платная. Другой провайдер, другой инструмент, а вывод один: счёт держит кэш.
| Цена за миллион токенов | gpt-5.4 (OpenAI) | gpt-5.5 (OpenAI) | Opus 4.7/4.8 (Anthropic) |
|---|---|---|---|
| Обычный вход | $2.50 | $5.00 | $5.00 |
| Чтение из кэша | $0.25 | $0.50 | $0.50 |
| Мой средний токен (факт со счёта) | ~$0.39 | ~$0.78 | ~$0.88 |
Что на самом деле кэшируется и почему один символ всё ломает
Первое, что ломает интуицию: кэшируется не текст промпта и не готовый ответ модели. Кажется, что это словарь, где по тексту запроса лежит готовый ответ. Картинка неверная, и из-за неё потом непонятно, почему всё так хрупко.
На самом деле, прежде чем выдать первое слово ответа, модель читает промпт, и это чтение не беглый просмотр, а дорогая вычислительная работа: каждый токен она прогоняет через свои слои и превращает в гору промежуточных чисел. Эти черновые вычисления и сохраняются. У них есть техническое имя, key/value-тензоры, они же KV cache, внутреннее представление прочитанного. Сам этап чтения промпта называется prefill, и для длинного контекста именно он дорогой и медленный, а генерация ответа по токену идёт уже после и тарифицируется отдельно. Кэш позволяет пропустить prefill для той части промпта, которую модель уже видела: тензоры для неё посчитаны и лежат готовые. Как устроен весь этот путь от токенизации до первого слова ответа, я подробно разбирал в путешествии промпта под капотом LLM.
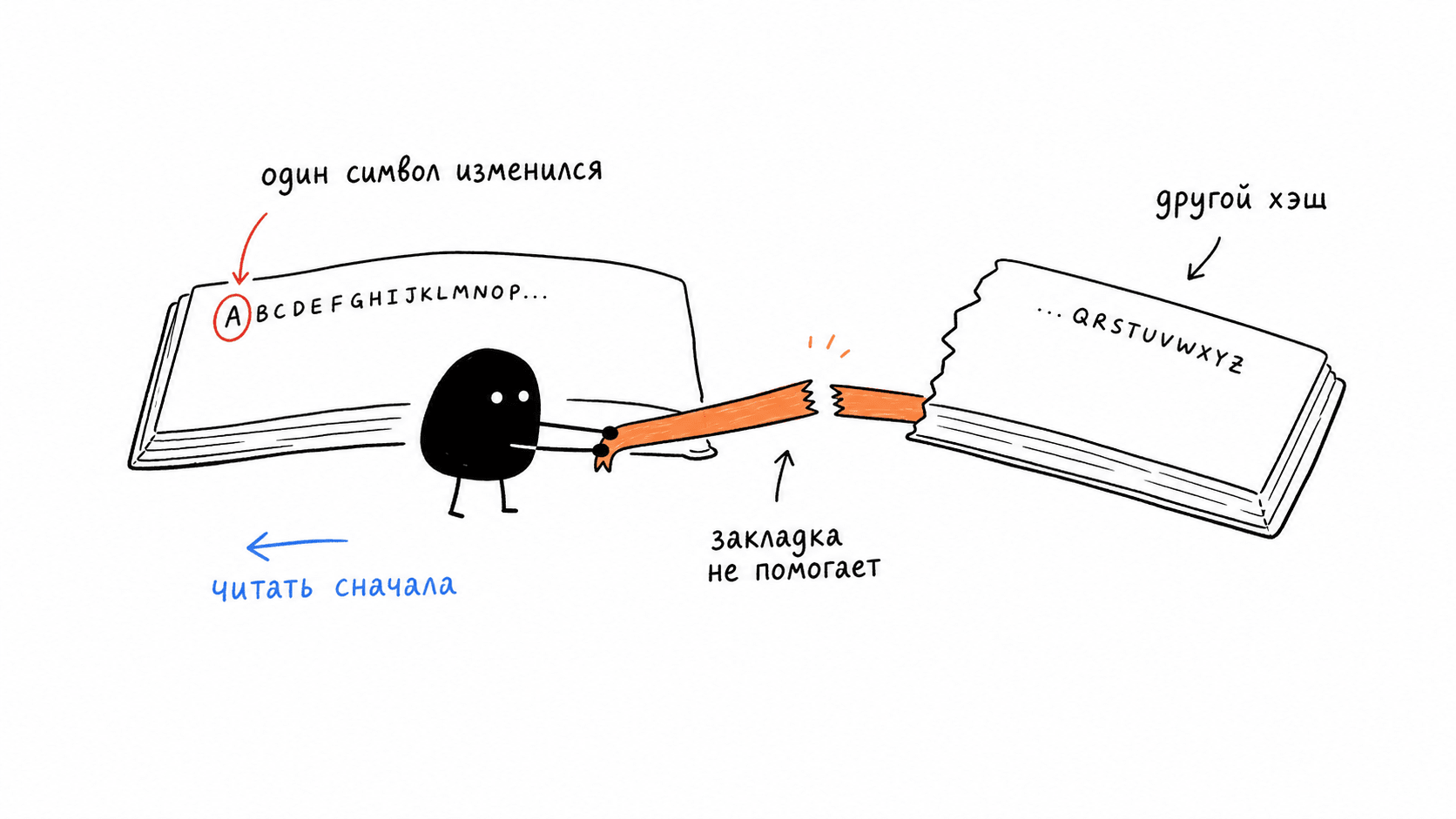
Каждый такой тензор зависит от всего текста до него, от первого символа промпта до этого места. Не от похожего текста, а ровно от этого, до символа. Поэтому переиспользовать можно только общее начало запроса, его префикс. Как только в начале что-то изменилось, все тензоры после точки изменения уже другие, и кэш для них недействителен.
Самая близкая аналогия это закладка в книге, которая работает, только если весь текст до неё не менялся. Можешь открыть страницу 200 и продолжить с заложенного места, но лишь если страницы с 1 по 199 остались слово в слово прежними. Поменял одно слово на странице 1, и закладка на странице 200 бесполезна: дальше уже другая книга, читать сначала. Кэш работает ровно так же. Совпадение префикса проверяется по криптографическому хэшу, и разница в один символ даёт другой хэш и полный промах. Это не фигура речи и не "ну почти совпало".
На кэш не влияет temperature, хотя интуиция подсказывает обратное. Кажется, если каждый раз просить модель отвечать чуть иначе, то и кэшу взяться неоткуда. Но temperature крутит выбор токена уже после того, как тензоры посчитаны, на самом последнем шаге, так что меняй её как угодно, кэш не сдвинется.
Prompt caching у OpenAI, Anthropic и Gemini: сколько каждый думает за тебя
Сама механика у всех одна, тот же prefix matching, но обёртку над ней три провайдера сделали очень по-разному. Удобно смотреть на это как на шкалу: сколько провайдер решает за тебя и сколько ручек оставляет в твоих руках.
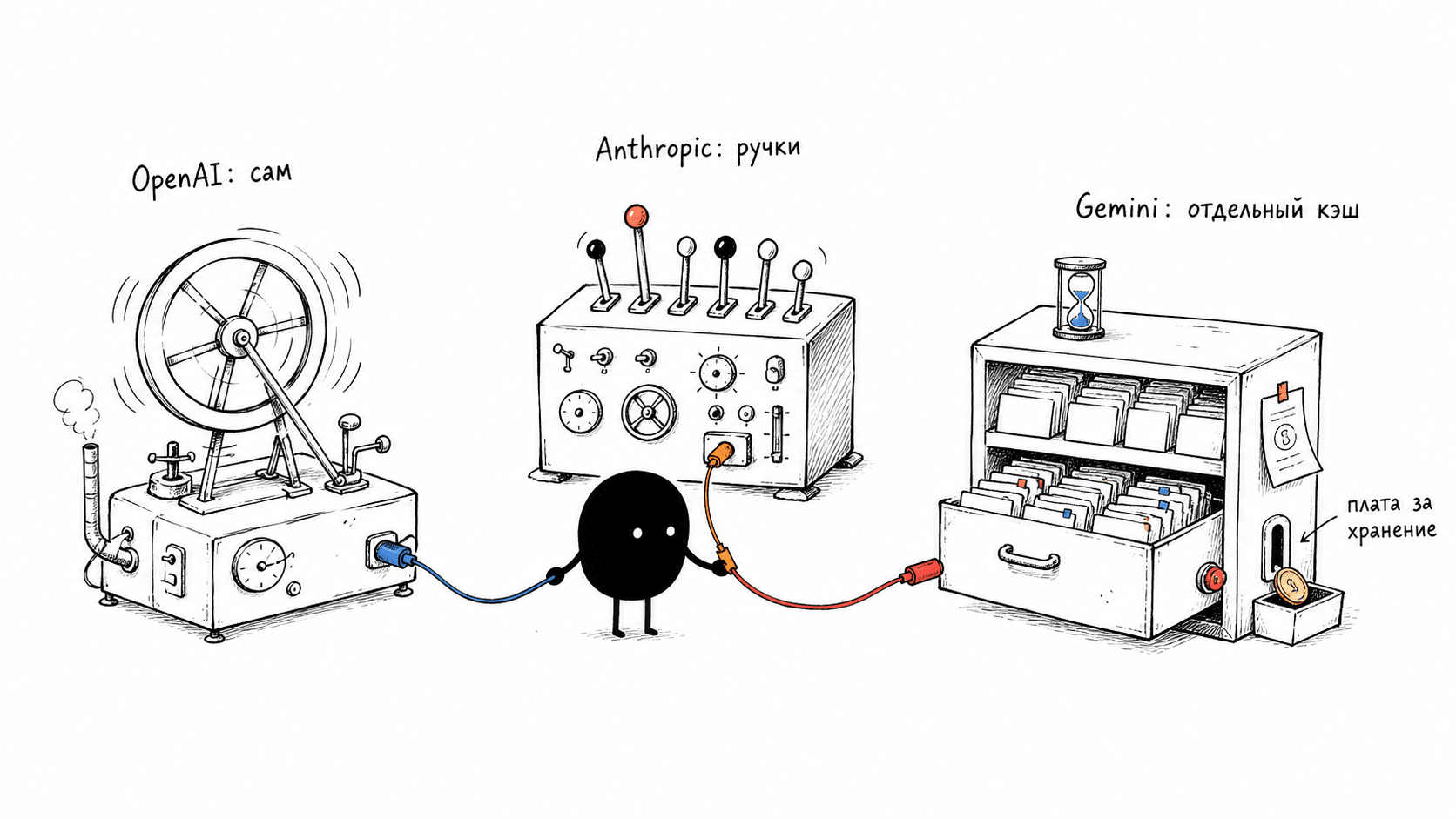
OpenAI делает всё за тебя. Кэш включён автоматически, без флагов. Префикс длиннее 1024 токенов кэшируется сам, запись бесплатна. За удобство платишь контролем, помочь кэшу или починить его руками почти нельзя, остаётся грамотно раскладывать промпт. Единственная ручка, prompt_cache_key, обманчива: это не breakpoint и вообще не управление кэшем, а routing hint, подсказка балансировщику, на какую машину отправить запрос, чтобы попасть туда, где твой кэш уже лежит. Я как раз на OpenAI, и эта автоматика мне на руку, одной заботой меньше. Но руками с кэшем я почти ничего не сделаю, а ответственность за стабильный префикс с меня никто не снял.
Anthropic даёт ручки. Тут два режима. Можно поставить explicit breakpoint, явно отметив блок, до которого включительно всё кэшируется. Точка при этом статична: диалог растёт, а кэшируется всё то же отмеченное начало, и всё, что накопилось после него, каждый ход идёт по полной цене. Поэтому есть второй режим, auto-caching: один параметр cache_control, и точка кэширования сама едет к последнему подходящему блоку по мере роста диалога, снимая старую боль многоходовых агентов, где breakpoint иначе пришлось бы двигать руками каждый ход. За запись Anthropic, в отличие от OpenAI, берёт деньги, и тут есть тонкость. Пять минут и час хранения это не два разных кэша, а два режима оплаты одного: запись токена в кэш на 5 минут стоит на четверть дороже обычного входного, в кэш на час вдвое дороже, а чтение в обоих случаях одинаково дешёвое. Префикс собирается в фиксированном порядке, сначала tools, потом system, потом messages.
Google делает из кэша ресурс. Если у OpenAI кэш это поведение по умолчанию, а у Anthropic пометка в запросе, то у Google это отдельный объект, который ты создаёшь сам и за хранение которого платишь, как за место на диске. В документации фича так и называется, context caching. У Gemini есть неявный кэш, включённый по умолчанию на моделях 2.5 и новее, но экономию он не гарантирует. Зато explicit caching это полноценный жизненный цикл объекта: кэш можно создать, обновить ему TTL, перечислить и удалить, как любую сущность через API, и по умолчанию он живёт час. В коде это выглядит так:
from google import genai
from google.genai import types
client = genai.Client()
# Стабильный префикс уезжает в отдельный объект
cache = client.caches.create(
model="gemini-3.1-pro-preview",
config=types.CreateCachedContentConfig(
system_instruction=system_prompt,
contents=[tools_and_docs], # всё, что повторяется из запроса в запрос
ttl="3600s",
),
)
cache.name # "cachedContents/abc123", ссылка на кэш
# Каждый запрос ссылается на объект по имени
response = client.models.generate_content(
model="gemini-3.1-pro-preview",
contents="свежий ввод пользователя",
config=types.GenerateContentConfig(cached_content=cache.name),
)
client.caches.update(name=cache.name, config={"ttl": "7200s"}) # продлить TTL
client.caches.delete(name=cache.name) # удалить и перестать платить за хранение
И Google единственный из трёх берёт деньги ещё и за хранение, по часам, около $4.50 за миллион токенов в час. Только имя модели легко перепутать. В актуальной линейке это gemini-3.1-pro-preview, а старая gemini-3-pro-preview закрыта ещё 9 марта 2026.
Если собрать всё в одну таблицу:
| OpenAI | Anthropic | Google Gemini | |
|---|---|---|---|
| Как включается | сам, без флагов | auto cache_control или explicit breakpoint | implicit или explicit-объект |
| Порог префикса | от 1024 токенов | от 2048 (Sonnet) / 4096 (Opus, Haiku) | от 1024 (Flash) / 4096 (Pro) |
| Цена записи | бесплатно | вход +25% (кэш на 5 мин) / вход ×2 (на час) | плата за хранение по часам |
| Чтение из кэша | ~10% от цены входа | ~10% | ~10% |
| Чем мерить | cached_tokens в usage | cache_read_input_tokens | usage_metadata |
Абсолютные цены меняются, тут они на июнь 2026 и важны не сами по себе, а соотношением. Само кэширование тоже включено не везде: у OpenAI и Gemini оно срабатывает автоматически, когда префикс перерос порог, а у Anthropic без cache_control в запросе не происходит ничего. А правило префикса не меняется ни у кого: удобство OpenAI его не отменяет, оно просто прячет его от тебя.
Анатомия cache-friendly промпта и как её ломают
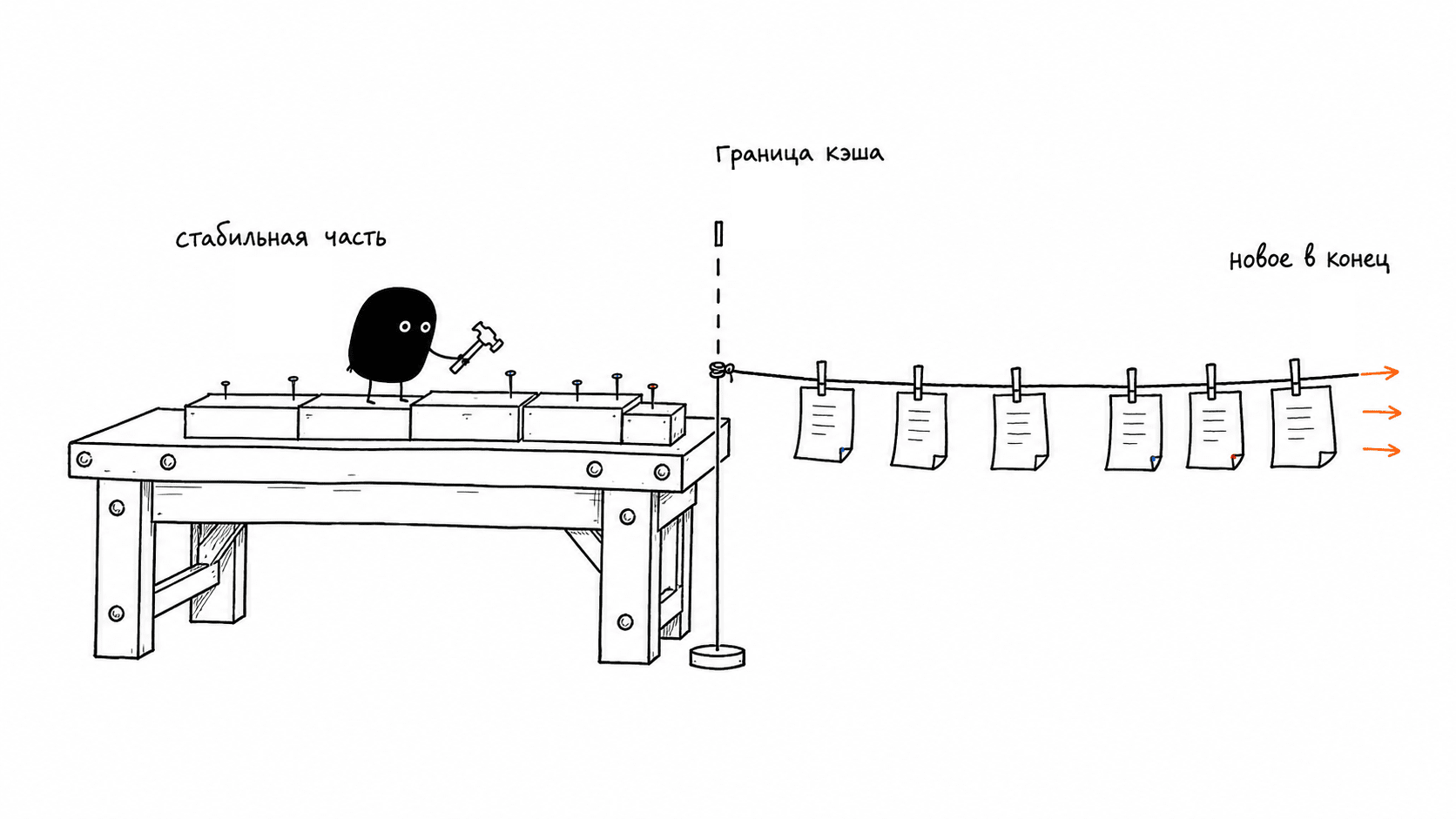
Из правила префикса прямо следует, как надо раскладывать промпт. Сверху вниз, от самого стабильного к самому изменчивому, с мысленной границей кэша где-то посередине.
Стабильная часть, она же кэшируемый префикс:
- Системный промпт: роль, правила, тон.
- Описания инструментов: фиксированный состав и порядок.
- Долгие инструкции и few-shot примеры.
Граница кэша.
Изменчивая часть, она каждый ход новая:
- Динамическое состояние: что поменялось с прошлого хода.
- История диалога, которую мы только дописываем.
- Свежий ввод пользователя.
Claude Code разложен ровно по этой схеме, static first и dynamic last. Thariq из их команды описывает порядок так: статический системный промпт и инструменты кэшируются глобально, файл проекта CLAUDE.md в пределах проекта, контекст сессии в пределах сессии, и только потом сообщения диалога. Кэш вообще живёт не внутри диалога, а на стороне провайдера, и ключом служит само содержимое префикса: два разных диалога с байт-в-байт одинаковым началом попадают в один и тот же кэш. Чем больше сессий делят общий префикс, тем чаще он срабатывает.
Два правила, без которых всё это не держится. Первое: историю ведём append-only, только дописываем в хвост, ничего не переписывая задним числом. Любая правка раннего сообщения сдвигает префикс, и весь кэш после неё умирает. Второе: структуры данных сериализуй детерминированно, один и тот же объект в одни и те же байты, ключи в JSON в одном порядке. Перемешал ключи, и для хэша это уже другой текст и другой кэш.
Сломать эту раскладку легко, и способов ровно четыре.
Динамика в начале промпта. Классика жанра, текущие дата и время в системном промпте. И Thariq, и Manus приводят её первым же примером, потому что попадаются почти все: слишком логично дать агенту знать, который час. Но время меняется каждую минуту, а с ним и префикс, и кэш не живёт. Решение элегантное. Системный промпт не трогай, передавай такие обновления через сообщения. Claude Code вставляет тег вроде "сейчас среда" в следующее сообщение, в хвост, а не в начало, и префикс остаётся цел.
Инструменты посреди сессии. Кажется разумным давать модели только те инструменты, которые нужны прямо сейчас, и подменять набор по ходу дела. Это, по словам Thariq, один из самых частых способов убить кэш. Инструменты лежат в начале префикса, и стоит добавить, убрать или переставить хотя бы один, как кэш всего диалога обнуляется.
Свежие данные, заброшенные наверх. Тянет положить результат поиска, профиль пользователя или подтянутый по RAG кусок повыше, чтобы модель точно заметила. Но свежее по определению меняется от запроса к запросу, и в начале промпта работает как таймер на самоуничтожение кэша. Свежее всегда в хвост.
Смена модели в середине сессии. Кэш привязан к конкретной модели, у каждой он свой. Провёл сто тысяч токенов на одной модели, переключился на другую, и кэш придётся строить заново. Классическая ловушка тут роутер, который на каждом ходу сортирует запросы на простые и сложные. Сложное уходит в умную модель, простое в дешёвую, чтобы не гонять Opus за погодой. Экономия выглядит очевидной, но если диалог уже накопил большой контекст на Opus, увести один простой вопрос в Haiku выходит дороже, чем дать ответить самому Opus. У дешёвой модели своего кэша нет, она перечитывает весь контекст по полной цене. У меня модель одна, так что лично меня эти грабли обходят, но для систем с авто-маршрутизацией ловушка реальная. Claude Code решает её через субагентов: основная модель готовит handoff-сообщение, а агент на модели полегче (у них это Explore-агенты на Haiku) делает задачу, не ломая кэш основной сессии.
Как услышать тишину: проверяем, что кэш работает
Раз провал кэша не выдаёт ошибки, единственный способ его заметить это смотреть на usage. Все три провайдера отдают разбивку прямо в ответе API: OpenAI кладёт число прочитанных из кэша токенов в usage.prompt_tokens_details.cached_tokens, Anthropic отдаёт cache_read_input_tokens и отдельно cache_creation_input_tokens на запись, Gemini возвращает счётчики в usage_metadata. Это и есть операционный интерфейс к кэшу: не обещание из документации, а конкретные числа на каждом запросе.
Сам я эти поля руками не парсю. Все запросы агента у меня идут через LiteLLM, и в его логах прямо видно, на каком запросе кэш сработал, а какой ушёл по полной цене. Это дёшево настроить и сразу снимает главную проблему тихого провала: ты начинаешь его видеть.
Дальше из этих чисел складывается cache hit rate, и это не цифра для красивого отчёта. В Claude Code, рассказывает Thariq, на него стоят алерты, а падение объявляют как SEV, то есть инцидент, наравне с падением аптайма. Пара процентов промахов сверх нормы заметно бьёт и по стоимости, и по латенси, а значит, по тому, какие лимиты команда может позволить на подписках. Метрика и есть способ сделать тихий провал громким.
Когда кэш начинает строить продукт
"Cache Rules Everything Around Me", шутит Thariq с отсылкой к Wu-Tang, и добавляет: для агентов это правило работает буквально. Claude Code, по его словам, с первого дня построен вокруг кэша. И когда читаешь, как именно, видно интересное. Правило кэша раз за разом побеждает интуитивное решение и переписывает продуктовую фичу под себя.
Самый чистый пример это plan mode, режим, где агент сначала строит план и не трогает файлы. Интуиция подсказывает: раз редактировать нельзя, подменим набор инструментов на read-only. И это сломало бы кэш, ведь инструменты живут в префиксе. Поэтому Claude Code пошёл против интуиции: все инструменты всегда в запросе, а вход и выход из режима оформлены как сами инструменты, EnterPlanMode и ExitPlanMode. Набор не меняется никогда, префикс цел. Бонусом модель может сама войти в plan mode на сложной задаче, тоже без разрыва кэша.
Та же логика с поиском инструментов. У Claude Code бывают подключены десятки MCP-инструментов, и совать полные описания всех в каждый запрос дорого, а убирать лишние по ходу диалога нельзя, это снова разрыв кэша. Решение Thariq называет deferred loading: вместо полных схем в префиксе лежат лёгкие заглушки, имя инструмента с пометкой "подгрузить позже", а полная схема приезжает, только когда модель сама выберет инструмент через поиск. Префикс стабилен, заглушки всегда одни и те же и в одном порядке. Сам приём шире инструментов и не привязан к одному harness: так же прогрессивно подгружаются agent skills, короткое описание и условие вызова в префиксе, тело по требованию.
И самый неочевидный случай, сжатие контекста. Когда диалог упирается в потолок окна, его сжимают в конспект и продолжают с него. Наивная реализация делает это отдельным запросом, с другим системным промптом и без инструментов, и префикс не совпадает с основным ни на байт. За все сто тысяч сжимаемых токенов платишь полную цену. Claude Code сжимает иначе. Тем же системным промптом, контекстом и инструментами родителя, а промпт на сжатие добавляет в хвост, так что для API запрос почти не отличается от предыдущего, префикс переиспользуется, и новыми оказываются только токены самого сжатия. Тот же принцип, что со сменой модели через субагентов: не ломать префикс основной сессии ради побочной задачи.
Кэш это деталь биллинга, строчка в прайс-листе про дешёвые токены. Но стоит начать защищать его всерьёз, и он перестаёт быть деталью: диктует, как устроен plan mode, как подгружаются инструменты, как работает сжатие, как переключаются модели. Техническое ограничение превращается в принцип, по которому спроектирован продукт. Мой агент куда проще Claude Code, а логика ровно та же: стоит начать считать кэш всерьёз, и промпт сам собой делится на стабильную голову и изменчивый хвост.
Оптимизация, которую нельзя оставить на потом
Весь prompt caching стоит на одном принципе, и масштабируется он широко. На маленьком конце это "не клади текущее время в системный промпт". На большом, как у Claude Code, это "перепроектируй plan mode, поиск инструментов и сжатие так, чтобы не двигать префикс". Разницы нет, это одно правило про закладку, которая работает, только если ничего перед ней не трогать.
Поэтому кэш для меня не оптимизация, которую можно прикрутить потом. Это constraint, под который архитектура промпта и агентного цикла обязана подстроиться с самого начала. Если хочешь, чтобы агент работал дёшево и быстро, варианта "займусь этим позже" нет: к этому "позже" он уже месяц как переплачивает кратно.
И вся хитрость в том, что prompt caching единственная из оптимизаций, которая при поломке не кричит. Сломанный кэш выглядит ровно как рабочий. Поэтому его нельзя оставлять на самотёк: о нём приходится думать заранее и смотреть на него постоянно. Иначе он сделает ровно то, что умеет лучше всего, тихо перестанет работать.
Оставайтесь любопытными.
Пишу об искусственном интеллекте, языковых моделях и инструментах для разработчиков. Тестирую модели и сервисы на реальных задачах, а выводами делюсь в телеграм-канале.
Частые вопросы про prompt caching
Что такое prompt caching?
Это механизм провайдеров LLM, который сохраняет внутреннее представление уже обработанного начала промпта (префикса) и переиспользует его в следующих запросах. Кэшируется не текст и не ответ модели, а промежуточные вычисления (KV-тензоры). Повторное чтение совпавшего префикса стоит примерно десятую часть цены обычного входного токена и заметно ускоряет ответ.
Сколько экономит кэш промпта?
Чтение из кэша стоит около 10% цены обычного входного токена у OpenAI, Anthropic и Google. Для агентов, где на один токен ответа приходится порядка ста входных, это меняет экономику целиком: по моим счетам выключенный кэш поднял бы дневные расходы примерно в семь раз. Латенси на длинных префиксах падает до 80–85%.
Почему кэш не срабатывает?
Кэш живёт, пока начало запроса совпадает байт в байт. Его ломают четыре вещи: динамика в начале промпта (например, текущее время в системном промпте), добавление или перестановка инструментов посреди сессии, недетерминированная сериализация данных и смена модели в середине диалога. Ошибки при этом не будет: запрос просто пойдёт по полной цене.
Влияет ли temperature на кэш?
Нет. Temperature и top_p управляют выбором токена уже после того, как промпт прочитан и тензоры посчитаны. Кэшируется именно этап чтения промпта (prefill), поэтому параметры сэмплирования можно менять как угодно: на попадание в кэш они не влияют. Это одна из самых частых ошибочных интуиций про кэширование.
Как проверить, что кэш работает?
Смотреть на usage в ответе API. OpenAI возвращает число прочитанных из кэша токенов в usage.prompt_tokens_details.cached_tokens, Anthropic в cache_read_input_tokens, Gemini в usage_metadata. Если гоните запросы через прокси вроде LiteLLM, разбивка видна прямо в логах. Из этих чисел складывается cache hit rate, главная операционная метрика кэша.
Чем отличается кэширование у OpenAI, Anthropic и Gemini?
У OpenAI кэш включён автоматически для префиксов от 1024 токенов, запись бесплатна. Anthropic требует параметр cache_control, берёт плату за запись (+25% за кэш на 5 минут, вдвое за час), зато даёт контроль. У Google кэш это отдельный объект с TTL и почасовой оплатой хранения, плюс implicit-кэш по умолчанию на новых моделях.


