Почему один символ ломает кэш: prompt caching под капотом
Автор: Алексей Бельтюков

TL;DR: Кэшируются не текст промпта и не готовый ответ, а key/value-тензоры каждого токена, его внутреннее представление в модели. Каждый такой тензор зависит от всего, что стоит левее, это причинное внимание (causal attention). Поэтому переиспользовать можно только общий префикс, и это инвариант, а не деталь конкретного движка. vLLM хранит тензоры блоками по 16 токенов и индексирует их хэш-цепочкой в стиле git: хэш блока включает хэш родителя, поэтому правка одного токена в начале переписывает все хэши после него и рвёт цепочку. Отсюда сразу оба свойства кэша: хрупкость (один символ убивает попадание) и сила (пропускается весь prefill общего начала). SGLang делает то же через radix tree, vLLM под sliding window заводит отдельный обработчик, но зависимость от общего префикса не исчезает нигде.
В первой части я вывел одно правило и предложил жить по нему: стабильное в начало, изменчивое в хвост, один символ в системном промпте обнуляет весь кэш. Правило рабочее, я сам собираю агента вокруг него. Но жить по закону, которого не понимаешь, неуютно. Почему именно один символ? Почему "почти такой же" промпт не считается за попадание? Где та физическая причина, из-за которой кэш срабатывает либо целиком на общем начале, либо не срабатывает вовсе?
vLLM и paged attention я руками не писал. Зато исходники открыты, и я полез в них ровно за этим: увидеть байтовую причину под правилом, которому раньше слепо верил. Дальше веду репортаж из кроличьей норы. Что физически лежит на GPU в момент попадания, как движок управляет этой памятью и почему хватает одного символа, чтобы всё посыпалось. Все имена и числа ниже сверены по исходникам vLLM 0.23.0, так что код в статье настоящий.
Что вообще кэшируется
Прежде чем выдать первое слово ответа, модель читает весь промпт целиком. У этого чтения есть имя, prefill, и это самая дорогая часть. Все входные токены прогоняются через слои разом, одним большим матричным проходом. Такой проход упирается в вычисления (compute-bound): он насыщает GPU перемножением матриц, и чем длиннее промпт, тем дольше длится.
Дальше начинается вторая фаза, decode. Модель генерирует ответ по одному токену за шаг, авторегрессивно, и тут узкое место другое. Каждый новый токен заставляет заново тащить из памяти весь накопленный кэш прошлых токенов, так что decode упирается в пропускную способность памяти (memory-bandwidth-bound), а не в арифметику.
Аналогия, которая мне помогла. Prefill это когда читаешь книгу и на каждой странице оставляешь пометки на полях. Decode это когда после прочтения пишешь конспект, и вместо перечитывания книги заново на каждом слове заглядываешь в свои пометки. Кэшируются именно пометки. Если кто-то до тебя уже читал книгу и сделал пометки, перечитывать эти страницы не нужно — берёшь готовые и пишешь свой конспект.
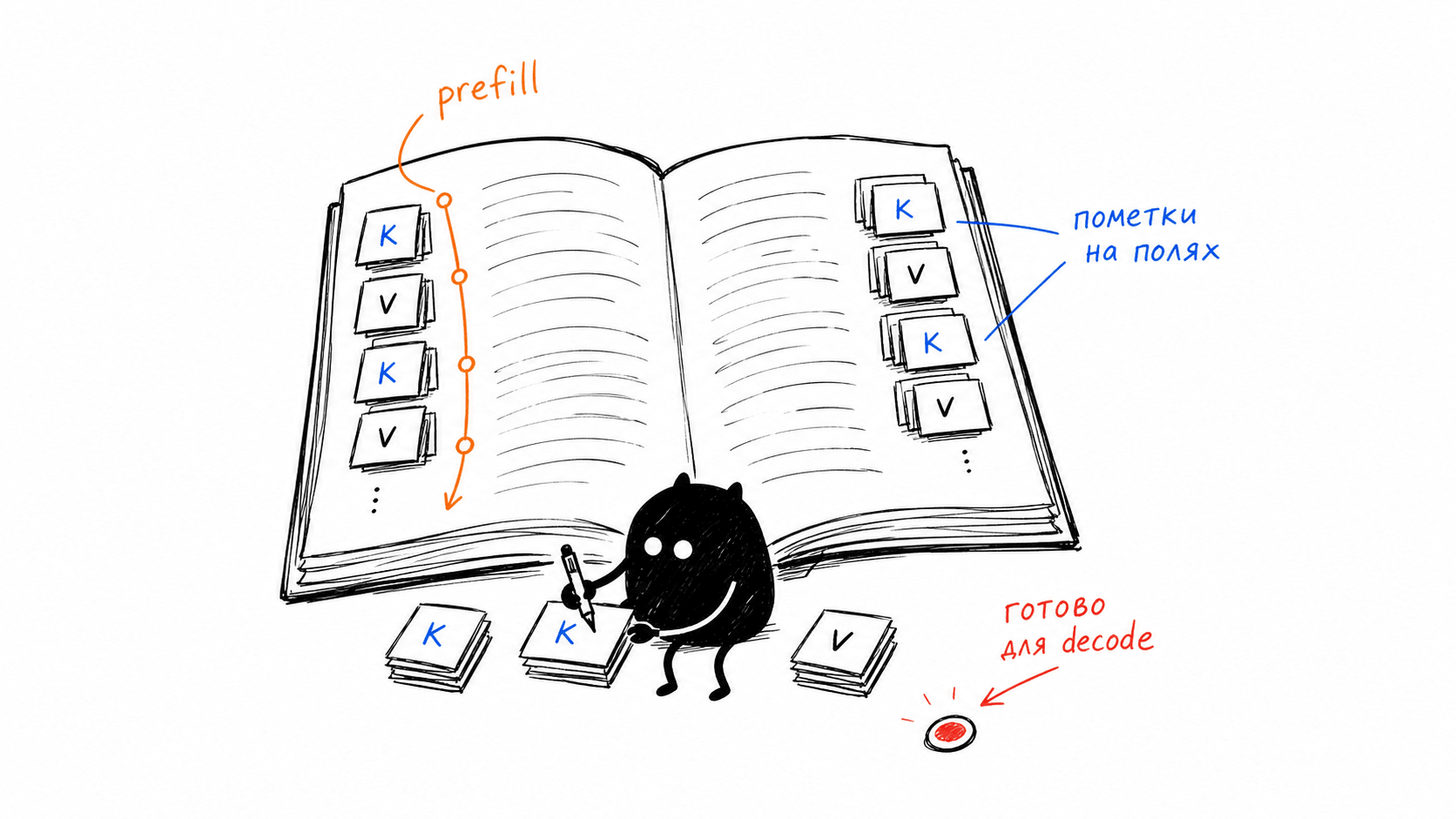
Теперь что это за пометки физически. В причинном внимании каждый токен через слои считает три тензора: Query, Key и Value. Грубо говоря: Query это "о чём спрашивает текущий токен", Key и Value это "что могут предложить остальным прошлые токены". Чтобы обработать новый токен, модели нужны Key и Value всех токенов слева от него. Их и сохраняют, это и есть KV-cache. Query хранить незачем: он свой у каждого шага, переиспользовать его нечем.
Key и Value токена считаются не из самого токена в вакууме, а с оглядкой на всё, что левее: причинное внимание разрешает токену видеть только прошлое, и это прошлое в его представление впечатано. KV-тензор 50-го токена зависит от токенов с 0 по 49. Значит, эти посчитанные тензоры годятся для повторного использования при одном условии: весь предшествующий префикс совпадает дословно. Не "похож", а идентичен до символа. Я пока проговариваю это спокойно, как факт механики. Из этого одного свойства растёт вообще всё, что дальше.
Зато если префикс совпал, выигрыш огромен по простой арифметике. Дописать в кэш один новый токен при decode это O(1): посчитал его Key и Value, положил рядом. А вот пересчитать KV для всего префикса заново это работа, линейная по его длине, и именно её попадание в кэш позволяет не делать. У кодинговых агентов входной контекст на порядки длиннее ответа (конкретные цифры этого перекоса я приводил в первой части), поэтому экономия именно на prefill общего начала бьёт точно в больное место.
Почему этот кэш так дорого хранить
Раз кэш это посчитанные тензоры, у них есть вес в байтах. Размер KV-cache на один токен равен:
2 (K и V) × n_layers × n_kv_heads × head_dim × bytes_per_value
Формула точная, не прикидка. Двойка это две сущности, Key и Value. Дальше число слоёв, число KV-голов, размерность головы и сколько байт занимает одно значение. Знакомый вариант 2 × n_layers × d_model × bytes верен, но только для классического multi-head attention, где d_model = n_heads × head_dim. С GQA или MQA, где KV-голов меньше, чем голов внимания, эта короткая запись систематически завышает результат, иногда в разы. Считать надо через n_kv_heads.
Подставим числа для модели вроде Llama-2-7B (32 слоя, 32 KV-головы, head_dim 128, fp16, то есть 2 байта):
2 × 32 × 32 × 128 × 2 = 524 288 байт ≈ 512 KiB на токен
Полмегабайта на один токен. Контекст в тысячу токенов это уже около 500 MiB, а сотня одновременных запросов по тысяче токенов это порядка 50 GiB только под кэш. И всё это пометки на полях, а не сам ответ. На этом месте хочется записать "полмегабайта на токен" как универсальный факт про 7B-модели, но это была бы ошибка. Возьмите Qwen3.6-27B: модель почти вчетверо крупнее, слоёв вдвое больше (64 против 32), головы даже шире (head_dim 256 против 128), но KV-голов всего 4 вместо 32. Итог — 256 KiB на токен, вдвое меньше нашей MHA-семёрки. А Qwen3.6-35B-A3B, у которой KV-голов на слой всего две, укладывается и вовсе в 80 KiB. Никакой одной магической цифры нет, число живёт вместе с архитектурой, а не с числом параметров.
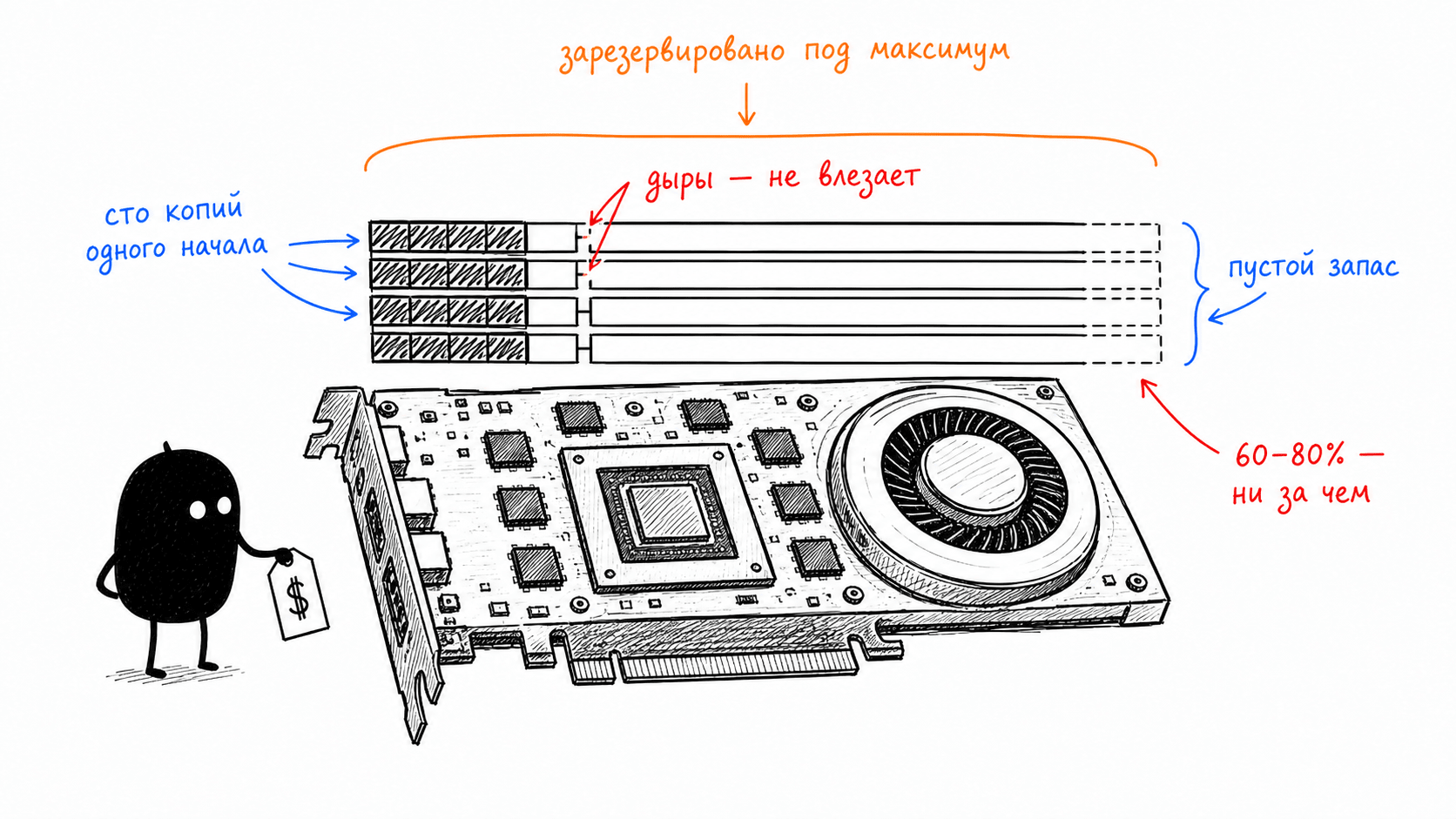
Десятки гигабайт под кэш это полбеды. Хуже то, как легко эту память растратить впустую. Наивный способ хранения, один непрерывный кусок VRAM на запрос, выделенный сразу под максимальную длину, наследует все классические болезни управления памятью из ОС. Зарезервировал место под максимум, а запрос оказался коротким — internal fragmentation, дыры внутри выделенного. Запросы приходят и уходят разной длины, между ними остаются щели, в которые новый запрос не влезает — external fragmentation. И отдельная боль агентов: сто запросов с одним и тем же системным промптом это сто независимых копий одного и того же KV-cache, потому что традиционный кэш живёт внутри запроса и после генерации просто выбрасывается. Между запросами он не разделяется вообще.
Насколько это расточительно, измерил оригинальный paper по PagedAttention: в системах, актуальных на момент его выхода, под реальные токены шло лишь 20,4–38,2% выделенной KV-памяти. Остальное уходило в зарезервированные впрок слоты и фрагментацию. 60–80% дорогой видеопамяти движок держал, по сути, ни за чем.
PagedAttention: виртуальная память для GPU
Berkeley посмотрела на проблему "память выделена непрерывным куском, оттого фрагментация и потери" и узнала в ней задачу, которую операционные системы решили полвека назад. Свой PagedAttention они описывают как алгоритм, вдохновлённый классической виртуальной памятью и страничной организацией в ОС.
Идея переносится один в один. KV-cache режется на блоки фиксированного размера, страницы. Логически тензоры запроса идут подряд, единой лентой, а физически блоки раскиданы по VRAM как попало. Связывает одно с другим block table: для каждого логического блока хранит его настоящий физический адрес. Это ровно page table из операционки, только страницы здесь не четыре килобайта оперативки, а несколько KV-тензоров на GPU. Я лез в код за хитрой GPU-магией, а нашёл то, что проходят на втором курсе. Логическая непрерывность отделена от физического размещения, и фрагментация как проблема просто испаряется: блоки одинаковые, дыр между ними не бывает.
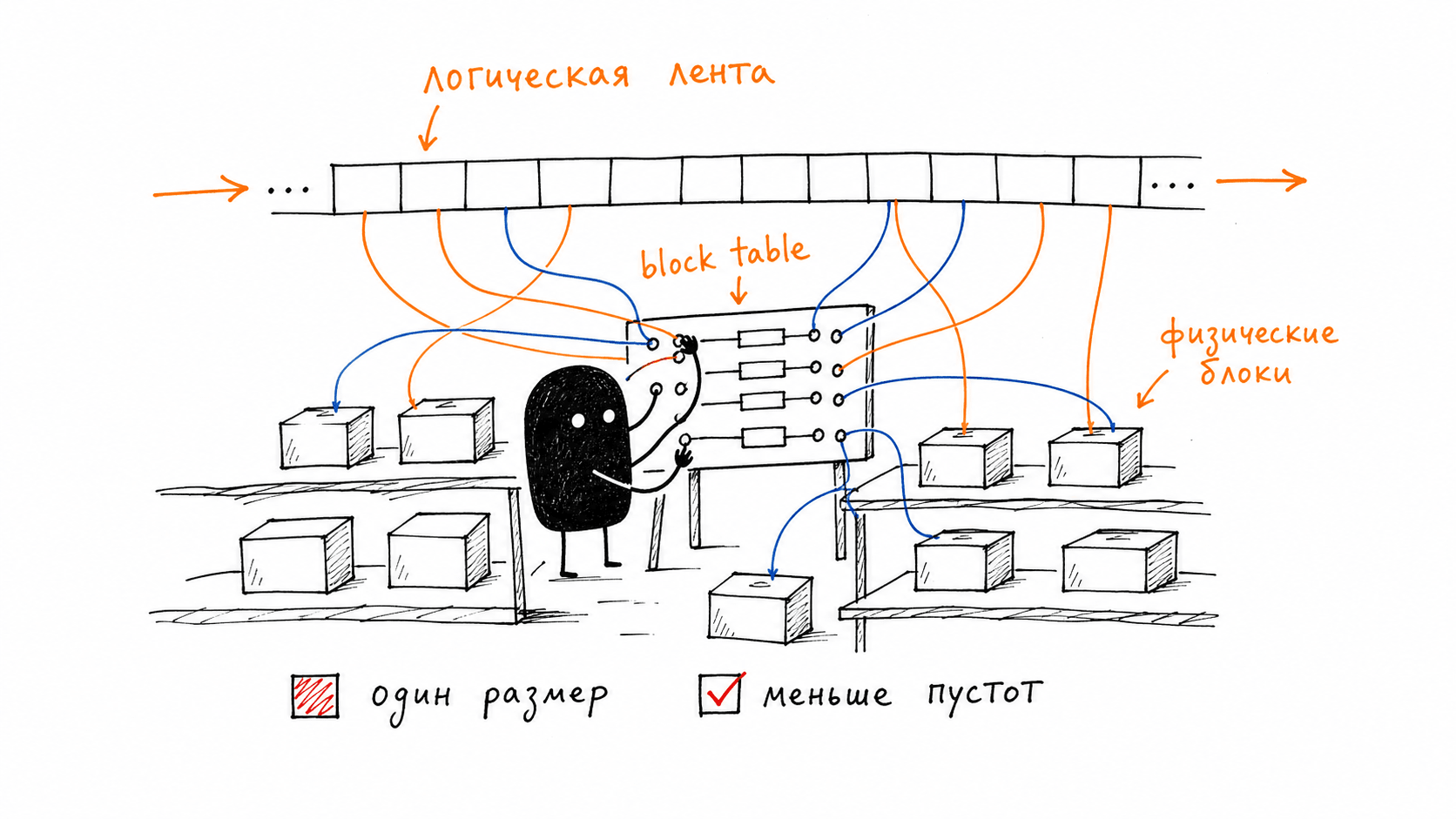
Потери памяти схлопываются до почти нулевых: единственное, что теперь пропадает впустую, это хвостик последнего неполного блока запроса, потери ограничены одним блоком. За счёт того, что освободившуюся память можно отдать под реальные запросы, vLLM поднимает throughput в 2–4 раза против тогдашних FasterTransformer и Orca при той же латенси. Та самая видеопамять, которая раньше на две трети простаивала под резерв, теперь работает.
Раз блоки это отдельные адресуемые страницы, один физический блок можно подключить сразу к нескольким логическим. Движок ведёт счётчик ссылок, ref_cnt, сколько запросов прямо сейчас держат этот блок. Если одному из них понадобится что-то в блоке поменять, срабатывает copy-on-write на уровне блока — приём прямиком из ОС. Авторы статьи описывают общий префикс как разделяемую библиотеку, загруженную в память один раз и подключённую к множеству процессов. Один системный промпт, посчитанный однажды, физически лежит в одной копии и обслуживает кучу запросов. Вот только чтобы это сработало, движок должен уметь быстро узнавать "о, этот блок я уже считал". Как именно он узнаёт, и есть самое интересное.
Хэш-цепочка в стиле git
Именно в устройстве этих хэшей и лежит байтовый ответ на вопрос из заголовка.
vLLM на старте нарезает пул блоков фиксированного размера. Размер по умолчанию 16 токенов: в vllm/config/cache.py это DEFAULT_BLOCK_SIZE, значение конфигурируемо. Цифра не с потолка. Оригинальный paper отдельно обосновывает её как баланс между утилизацией GPU и internal fragmentation. Каждый заполненный блок умеет считать свой хэш, и вот как выглядит сам блок (поля сокращены, файл vllm/v1/core/kv_cache_utils.py):
@dataclass(slots=True)
class KVCacheBlock:
block_id: int
ref_cnt: int # сколько запросов прямо сейчас держат блок
_block_hash: ... # хэш блока; есть, только когда блок заполнен и закэширован
prev_free_block: ... # связки блока в LRU-очереди свободных
next_free_block: ...
Хэш блока считает функция hash_block_tokens. Суть в одной строке:
def hash_block_tokens(hash_function, parent_block_hash,
curr_block_token_ids, extra_keys):
return BlockHash(
hash_function((parent_block_hash, curr_block_token_ids, extra_keys))
)
Смотрите, что входит в хэш блока. Токены самого блока, curr_block_token_ids, это ожидаемо. Некие extra_keys, к ним вернёмся в разделе про безопасность. И главное — parent_block_hash, хэш предыдущего блока. Хэш блока N включает в себя хэш блока N−1, который включает хэш блока N−2, и так до самого начала, у которого вместо родителя стартовый сид NONE_HASH. Получается цепочка, где каждое звено зафиксировало в себе всю историю до него.
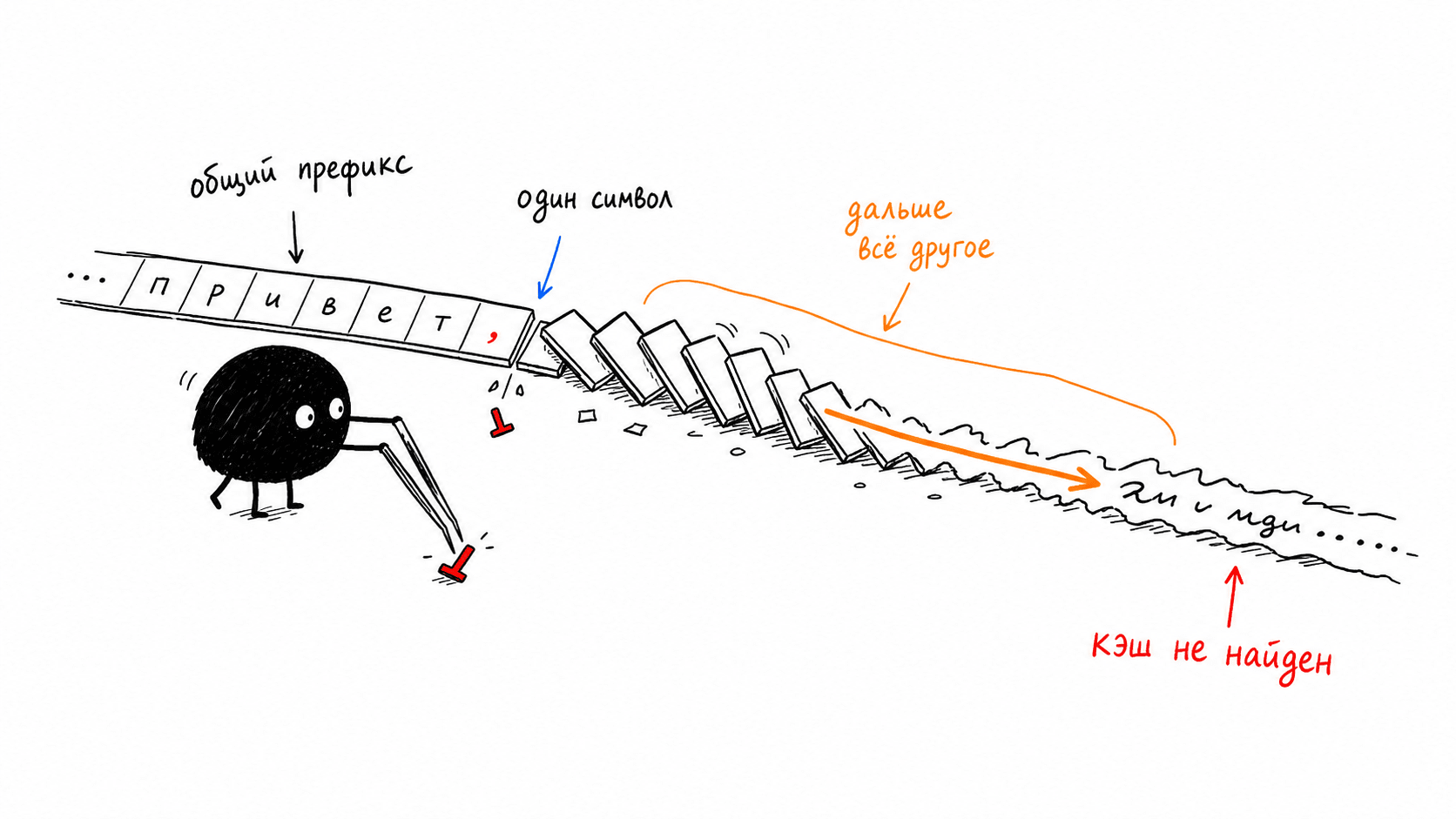
Если эта механика кажется знакомой, то не зря. Так устроены git и блокчейн. ID коммита в git это хэш его содержимого плюс хэш родителя, поэтому правка одного давнего коммита переписывает идентификаторы всех коммитов после него. Блок в блокчейне точно так же сцеплен с предыдущим. KV-блоки в vLLM сцеплены ровно по тому же принципу. Совпал хэш блока N — значит, гарантированно совпадают все блоки с нулевого по N−1, одна проверка валидирует весь префикс. Никакого посимвольного сравнения тысяч токенов, одно сравнение хэшей.
Меняешь один токен в начале промпта, и у его блока уже другой curr_block_token_ids, значит, другой хэш. Этот хэш был parent_block_hash для следующего блока, значит, у следующего хэш тоже поехал. И так до конца цепочки. Один символ в начале не "немного портит" кэш, он переписывает идентификаторы всех блоков после себя, и ни один из них больше не находится. Та самая хрупкость из правила первой части это не прихоть движка и не перестраховка, это арифметика хэш-цепочки.

Упрощать до "там всегда sha256" не стоит: в коде hash_function это первый аргумент, подключаемый. По умолчанию vLLM берёт sha256 с CBOR-сериализацией, но рядом доступен и xxhash, а BlockHash объявлен как NewType над обычными bytes (32 байта это уже частность sha256). Сама же функция поиска совпадения предельно прямолинейна. FullAttentionManager.find_longest_cache_hit идёт по хэшам блоков от начала и складывает попадания, пока не наткнётся на первый промах:
# суть цикла find_longest_cache_hit
computed = []
for block_hash in islice(block_hashes, max_num_blocks):
block = block_pool.get_cached_block(block_hash, ...)
if block is None:
break # первый промах: дальше точно ничего не посчитано
computed.append(block)
return computed
Логику обрыва на первом промахе авторы закрепили прямо комментарием в коде: если хэша блока нет в кэше, то все следующие блоки заведомо ещё не посчитаны. Из цепочки это следует автоматически, искать дальше бессмысленно. Точка входа сюда, KVCacheManager.get_computed_blocks, передаёт в этот поиск ещё и предел max_cache_hit_length = num_tokens − 1. Мелкая деталь, но честная: даже при дословном совпадении всего префикса хотя бы последний токен придётся посчитать заново, иначе модели нечего подать как Query для генерации.
Под капотом это всё оркеструет BlockPool. Хэши и блоки лежат в BlockHashToBlockMap с O(1)-поиском, свободные блоки в FreeKVCacheBlockQueue, двусвязном списке, откуда любой блок вынимается за O(1), а в голове живёт кандидат на вытеснение по LRU. Когда чужой запрос попал в твой блок, touch поднимает счётчик ссылок и вынимает блок из очереди свободных. Когда запрос закончился, free_blocks уменьшает ref_cnt, и при падении до нуля блок возвращается в очередь, откуда его рано или поздно вытеснит _maybe_evict_cached_block. Аллокация, шаринг, вытеснение — вся жизнь блока в одном классе. И заметьте слово "чужой": блоки тут спокойно переходят между разными запросами. Это не оговорка.
Этот кэш не твой
Эта мысль перевернула мне картинку сильнее всего.
Интуиция подсказывает, что кэш живёт внутри моего диалога: я отправляю ходы, движок помнит начало моей беседы, экономит мне токены и доллары. Картинка неверная. Prefix caching работает по содержимому, а не по разговору. Блоки индексируются хэшем токенов, и хэшу совершенно всё равно, чей это запрос. Если другой пользователь пришёл с запросом, у которого начало совпадает с твоим (тот же системный промпт, та же шапка инструкций), его запрос попадёт в блоки, которые посчитал ты, и пропустит для них prefill целиком. И наоборот.
То есть общий системный промпт публичного сервиса считается со всей дорогой работой prefill ровно один раз на всех. Дальше он просто лежит готовыми тензорами в общем пуле и раздаётся всем, кто начинает с тех же токенов. Та самая "разделяемая библиотека" из paper, только подключаются к ней разные люди. Для нагруженного сервиса это огромная экономия, она и делает дешёвый кэш возможным в принципе.
Только поверните эту мысль на пол-оборота. Если мой запрос ускорился оттого, что кто-то до меня уже посчитал общее начало, то по скорости моего запроса можно судить о том, что лежало в кэше до него.
Значит, кэш можно подсматривать
Кэш-попадание это быстро, кэш-промах это медленно, и эта разница во времени измерима снаружи. Отсюда timing side-channel: злоумышленник шлёт пробные запросы и по латенси определяет, закэширован ли уже такой префикс, то есть проходил ли через сервис кто-то с таким же началом. На общих системных промптах это безобидно. Если же в начало запроса попадает что-то чувствительное, угроза становится осязаемой. Это не гипотеза из головы: есть отдельная работа InputSnatch ровно про то, как через тайминги кэша воруют чужой ввод.
Помните extra_keys в формуле хэша, мимо которых мы прошли? Вот их работа. vLLM умеет подмешивать в хэш соль, cache_salt. Параметр запроса попадает в extra_keys, причём только у первого блока (в коде соль добавляется при start_token_idx == 0). Хэш первого блока через цепочку влияет на все последующие, одной точки достаточно. Эффект простой: блоки делят между собой только запросы с одинаковой солью. Дал каждому тенанту свою соль, и кэш разрезан на изолированные пространства имён, чужой запрос физически не сможет попасть в твои блоки, даже если начало совпадает дословно. Изоляция через одно поле в запросе.
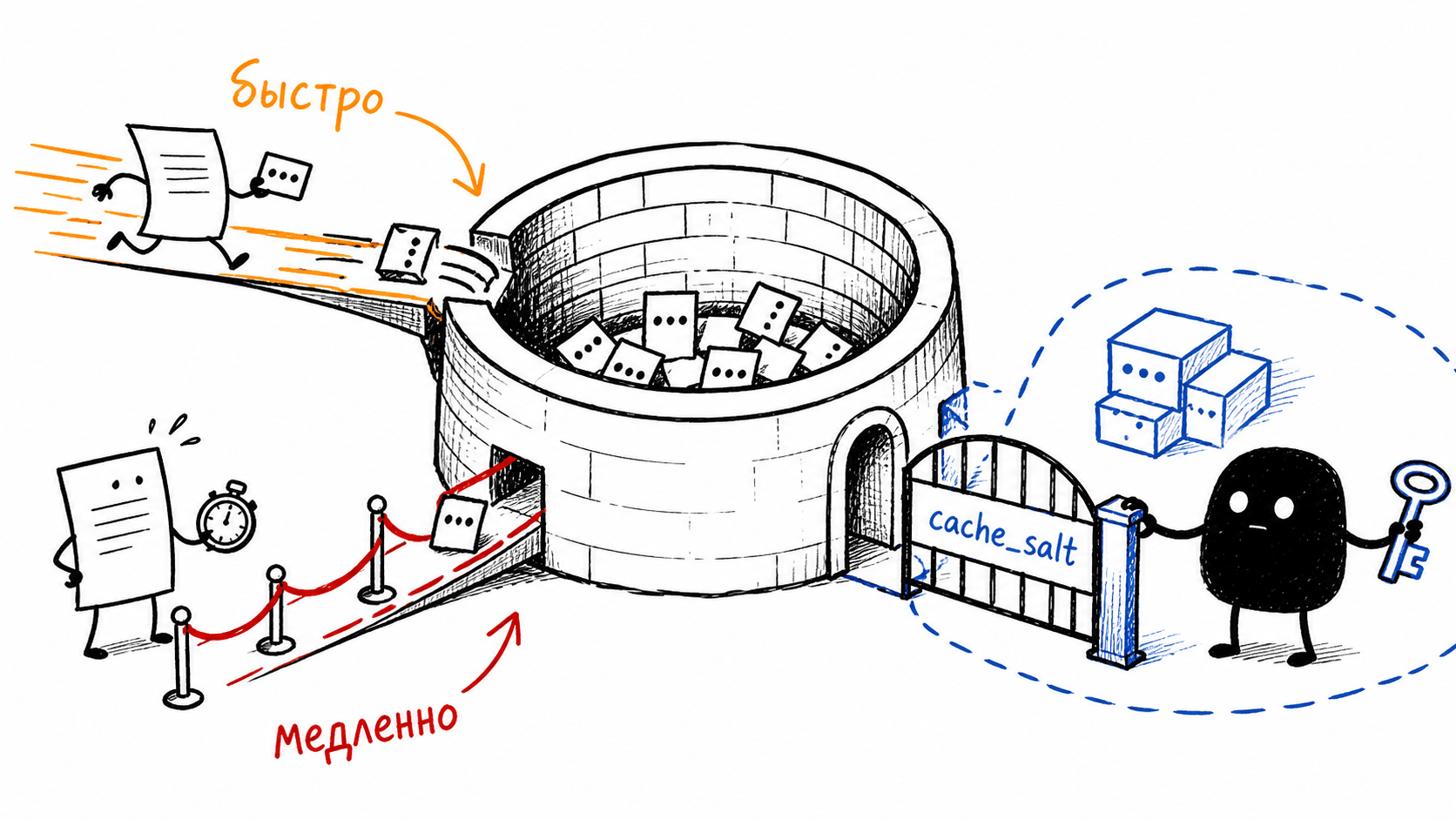
У провайдеров кэш живёт по таймеру: OpenAI пишет, что префикс держится 5–10 минут неактивности, до часа в пределе, а на новых моделях тензоры выгружаются в GPU-local storage с удержанием до суток. Это поведение провайдера, а не механика vLLM. У самого vLLM никакого TTL по времени нет, блок вытесняется только по LRU и только когда память понадобилась под новый запрос. Когда читаете про "время жизни кэша", держите в голове, какой это слой.
Это закон, а не реализация
После всего этого легко решить, что prefix caching это просто "как сделали в vLLM". Линейная хэш-цепочка, блоки по 16, LRU. Поменяли бы движок, был бы другой кэш. Но инвариант и его воплощение здесь не одно и то же.
SGLang индексирует переиспользование совсем иначе. Там KV-cache не выбрасывается, а складывается в radix tree: ключи это последовательности токенов, значения это их KV-тензоры. Дерево само умеет искать общий префикс, вставлять новый путь и вытеснять листья по LRU, а ещё даёт ветвление из коробки: две сессии с общим системным промптом это две ветки от одного узла. Структура данных другая, не цепочка хэшей, а префиксное дерево. Больше того, разные индексы уживаются даже внутри одного vLLM: для sliding window там свой SlidingWindowManager, который переопределяет тот самый find_longest_cache_hit под логику окна.
Линейная цепочка, radix tree, отдельный обработчик под окно. Реализаций индекса много, а переиспользуется во всех одно и то же: совпадающий префикс токенов. Почему все эти разные структуры сходятся к одному? Потому что KV-тензор токена впечатал в себя всё, что левее, причинное внимание не оставляет вариантов. Общий префикс это единственное, что физически валидно переиспользовать, какое дерево или цепочку ты над ним ни построй. Инвариант диктует механика модели, а не вкус авторов движка.
Отсюда же финальная симметрия, которую мне эта нора показала. Хрупкость и сила кэша это не два отдельных свойства, за которые отвечают разные части системы. Это одно свойство, увиденное с двух сторон. Тензоры намертво сцеплены с префиксом, поэтому общий префикс можно пропустить целиком (сила), и поэтому же одного изменённого токена хватает, чтобы обрушить всё после него (хрупкость). Одна причина, два следствия.
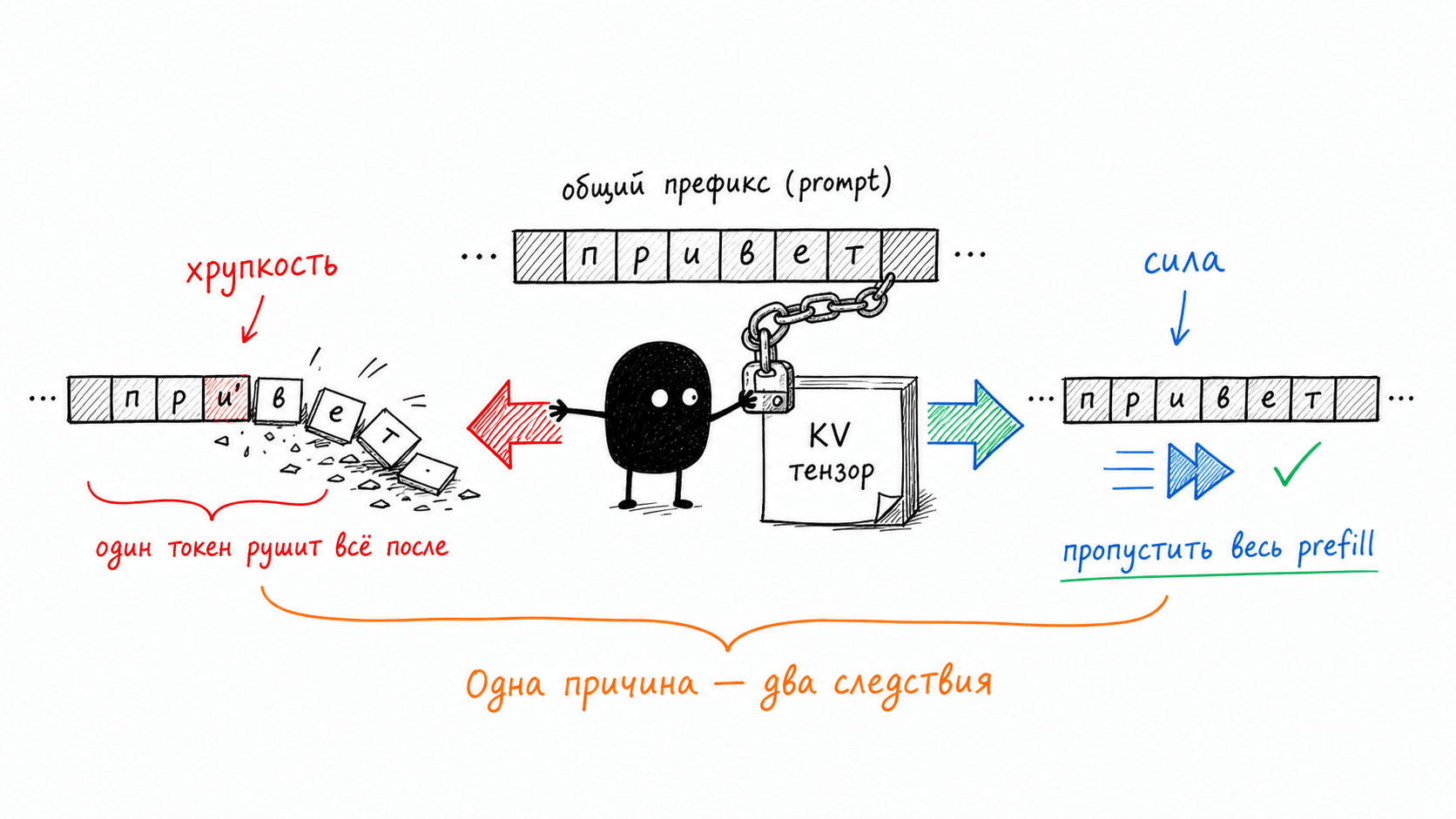
Правило из первой части, стабильное в начало, изменчивое в хвост, теперь стало более прозрачным. Под ним лежит хэш-цепочка, в которой ранний токен переписывает все звенья после себя. Архитектурные приёмы Claude Code, которыми он эту хрупкость обходит (Plan Mode вместо смены набора инструментов, отложенная загрузка, аккуратная компакция), я разбирал там же, повторяться не буду. Скажу только, что теперь виден их общий байтовый смысл: все они про одно, не трогать ранние блоки префикса, чтобы не поехала цепочка хэшей. Кроличья нора закончилась там же, где правило из первой статьи, только теперь это не заклинание, а механизм, который видно до последнего блока.
Оставайтесь любопытными.
Пишу об искусственном интеллекте, языковых моделях и инструментах для разработчиков. Тестирую модели и сервисы на реальных задачах, а выводами делюсь в телеграм-канале.
Частые вопросы про KV-cache и prompt caching
Что такое KV-cache?
KV-cache — это сохранённые key/value-тензоры каждого токена, его внутреннее представление в модели. Чтобы обработать новый токен, модели нужны Key и Value всех токенов слева, и их считают один раз и держат в памяти, чтобы не пересчитывать прочитанный промпт заново на каждом шаге генерации. На модели вроде Llama-2-7B такой кэш весит около 512 KiB на токен.
Почему изменение одного токена в начале промпта ломает весь кэш?
Потому что key/value-тензор токена зависит от всего префикса слева — это причинное внимание. vLLM хранит блоки и сцепляет их хэш-цепочкой в стиле git: хэш блока включает хэш родителя. Меняешь один токен в начале — у его блока другой хэш, и у всех блоков после него тоже. Ни один из них больше не находится в кэше, и prefill идёт заново.
Что такое PagedAttention?
PagedAttention — приём из vLLM, переносящий на KV-cache идею виртуальной памяти из операционных систем. Кэш режется на блоки фиксированного размера (по умолчанию 16 токенов), а block table связывает логический порядок тензоров с их физическим адресом в VRAM. Это убирает фрагментацию и позволяет нескольким запросам делить один физический блок общего префикса.
Сколько памяти занимает KV-cache на один токен?
Зависит от архитектуры: 2 × число слоёв × число KV-голов × размерность головы × байт на значение. Для Llama-2-7B (fp16) это около 512 KiB на токен. С GQA или MQA, где KV-голов меньше, кэш на токен падает в разы. Универсальной цифры нет, число живёт вместе с архитектурой, а не с числом параметров, и короткая формула через d_model при GQA/MQA завышает результат.
Чем prefix caching в vLLM отличается от SGLang?
Переиспользуется одно и то же — совпадающий префикс токенов, но индексируют его по-разному. vLLM сцепляет блоки линейной хэш-цепочкой, SGLang складывает KV-тензоры в radix tree (префиксное дерево) и делит общий префикс между несколькими ветками из коробки. Структура индекса — выбор движка, а зависимость от общего префикса диктует сама механика причинного внимания.
Можно ли подсмотреть чужой кэш через тайминги?
Да, это timing side-channel. Кэш-попадание быстрее промаха, и разница измерима снаружи: по латенси видно, проходил ли через сервис запрос с таким же началом (об этом работа InputSnatch). На общих системных промптах это безобидно, но если в начало попадает чувствительное — угроза реальна. vLLM изолирует кэш по тенантам через cache_salt: соль подмешивается в хэш первого блока.


