Мультимодальный AI в 2025: как GPT‑5.1, Gemini, Claude и Grok научились понимать текст, изображения и видео одновременно

Ещё совсем недавно для каждого домашнего устройства у вас был свой пульт: один для телевизора, другой для кондиционера, третий для музыкального центра. Каждый говорил на своём языке, и заставить их работать вместе было почти невозможно. Примерно так же выглядел мир искусственного интеллекта всего пять лет назад — набор мощных, но разрозненных моделей, каждая из которых умела что‑то одно.
Вернёмся в недалекий 2020 год. Ландшафт AI представлял собой набор изолированных решений, каждое со своей экосистемой. Для текста безраздельно властвовали трансформеры вроде BERT, для изображений — CNN вроде ResNet, для аудио — модели уровня WaveNet, и все они жили в разных мирах.
Фактически это были независимые стеки с разной архитектурой. В результате каждая система имела уникальные индуктивные смещения (inductive biases) — врожденные предположения о природе данных. CNN были «заточены» под пространственные иерархии, предполагая, что соседние пиксели важнее далеких. Рекуррентные сети (RNN) были созданы для работы с последовательностями во времени. Трансформеры же изначально были оптимизированы для семантических связей в тексте.
Конечно, попытки навести мосты между этими мирами были. Ранняя мультимодальность напоминала инженерное решение из мира стимпанка: исследователи буквально «сшивали на живую» уже готовые, предварительно обученные модели. Типичный подход выглядел так: берём предварительно обученный (и замороженный) ResNet для картинок, берём такой же BERT для текста и поверх них обучаем небольшой модуль слияния на основе cross‑attention. Модели при этом не учатся видеть и читать одновременно — они просто пересылают друг другу вектора через тонкий «переводчик».
К 2025 году этот модульный подход сменился тектоническим сдвигом к унифицированным AI-инфраструктурам. Зоопарк узкоспециализированных моделей уступает место единой, универсальной архитектуре, которая лежит в основе обработки всех модальностей. Эволюцию можно наглядно представить в виде простой таблицы:

Этот переход от фрагментации к унификации — и есть главная история современного AI. Это то, что позволяет нам сегодня говорить не просто об «еще одной версии ChatGPT», а о смене парадигмы во всем стеке.
Так что, если я скажу вам, что в 2025 году GPT-5.1, Gemini 2.5, Claude Opus 4.1 и Grok-4 умеют одновременно понимать текст, изображения и видео — и все они построены вокруг одной и той же базовой идеи? Идеи, которая смогла объединить эти разрозненные миры.

Откровение. Next Token Prediction: один принцип, чтобы править всеми
Итак, мы оставили позади раздробленный мир 2020 года и задались вопросом: какая же единая идея смогла объединить текст, изображения и аудио под крылом одной архитектуры? Ответ, на первый взгляд, может показаться обескураживающе простым. Этот универсальный двигатель, приводящий в движение и GPT-5.1, и Gemini 2.5, и Claude Opus 4.1, и Grok-4 называется Next Token Prediction (NTP), или «предсказание следующего токена».
В своей основе NTP — это до боли знакомая игра в «продолжи фразу». Представьте, что вы даете модели затравку: «Кот сидит на ___». Задача модели — не «понять» кота или стул, а всего лишь рассчитать распределение вероятностей для следующего слова из всего своего гигантского словаря. Например, она может решить, что с вероятностью 50% следующим словом будет «коленях», с 30% — «полу», и с 20% — «стуле». Весь процесс ее обучения сводится к тому, чтобы максимизировать вероятность правильного, «наземного» (ground truth) токена, который шел в обучающих данных.
И вот здесь начинается откровение. Эта простая, почти детская игра оказалась тем самым «одним кольцом, чтоб править всеми». Как говорится в комплексном обзоре конца 2024 года, который я проанализировал, «задачи из разных модальностей могут быть эффективно инкапсулированы в рамках NTP». Секрет в том, что NTP — это самообучающийся (self-supervised) процесс. Модели не нужны дорогостоящие человеческие разметки; правильный ответ — следующий токен — уже содержится в самих данных. Это позволяет скармливать ей триллионы токенов из интернета, и она будет учиться сама.
«Хорошо, — скажете вы, — с текстом все понятно. Но при чем здесь картинки и видео?» А вот в этом и заключается магия, которая снимает с мультимодальных моделей весь ореол таинственности. Принцип расширяется на другие модальности путем преобразования всех данных в единый формат — последовательность дискретных токенов. Если мы можем превратить изображение в последовательность визуальных «слов», а аудио — в последовательность звуковых «слогов», то для трансформера задача остается прежней. Например, мы даём модели такой ввод: «Вот фото моей кухни: [изображение]. Опиши, что ты видишь.». Внутри она воспринимает это как одну последовательность токенов:["Вот", "фото", "моей", "кухни", ":", <IMG>, v₁, v₂, …, vₙ, </IMG>, ".", "Опиши", ",", "что", "ты", "видишь", "."]. Для трансформера это всего лишь набор токенов в определённом порядке — он не различает «текстовые» и «визуальные» по сути. Он просто продолжает играть в свою игру.
И это не просто теория. К ноябрю 2025 года NTP признан «основополагающей парадигмой» не только для языка, но и для задач зрения и аудио. Например, нашумевшая модель Emu3, выпущенная в сентябре 2024, способна генерировать видео, «просто предсказывая следующий токен в видеопоследовательности». В сфере аудио исследователи в 2025 году научились моделировать диалог двух людей, заставляя модель на каждом шаге предсказывать пару токенов — по одному для каждого говорящего.
Технически NTP — это обучение авторегрессионной модели, которая аппроксимирует распределение вероятностей следующего токена на основе предыдущего контекста. При этом параметры модели подбираются так, чтобы минимизировать кросс‑энтропийную функцию потерь (cross-entropy loss) между предсказанным распределением и истинным следующим токеном. Однако за всей этой математикой скрывается все та же простая идея — угадать, что будет дальше.
Это подводит нас к главному парадоксу. Если модель умеет лишь одно — угадывать следующий токен, почему она вдруг стала способна объяснять код, описывать картинки и комментировать видео с конференции? Ответ кроется в том самом шаге, который мы до сих пор принимали как данность — в механике превращения реальности в токены.

Алхимия. Как превратить изображение в последовательность токенов
Мы установили, что универсальный язык современных AI — это последовательность токенов, а их главный навык — предсказание следующего токена в этой последовательности. Но здесь и кроется главный фокус, настоящая современная алхимия. Как превратить нечто непрерывное, богатое и аналоговое, как фотография заката, в строгую, дискретную последовательность чисел, с которой может работать модель вроде GPT?
Ключ к этому превращению называется дискретная визуальная токенизация. Это процесс, который лежит в основе «зрения» всех современных мультимодальных систем. Без него любая картинка для языковой модели — не более чем непонятный набор пикселей. Удобная аналогия здесь — это создание мозаики. Представьте, что у вас есть ограниченный набор маленьких цветных плиток (это наш codebook). Чтобы воссоздать картину, вы разбиваете ее на небольшие участки и для каждого участка подбираете наиболее подходящую по цвету и фактуре плитку из вашего набора. В итоге вы получаете не саму картину, а последовательность номеров плиток, из которой ее можно собрать. Модель не видит «фото», она видит именно эту последовательность — [плитка_7, плитка_83, плитка_12, ...], — и учится понимать и продолжать ее так, чтобы получались осмысленные изображения.
На техническом уровне этот процесс выглядит так:
- Берется изображение, например, размером 512x512 пикселей.
- Специальная модель-энкодер (раньше чаще на базе CNN, сейчас всё чаще на базе ViT) «сжимает» его, превращая в компактное, но все еще непрерывное латентное представление.
- Затем происходит самый важный шаг — квантование. Каждый вектор в этом сжатом представлении сопоставляется с его «ближайшим соседом» в заранее выученной codebook — том самом наборе эталонных «плиток».
- На выходе мы получаем то, что нужно: последовательность дискретных индексов (токенов) из этой codebook. С этой последовательностью стандартные блоки Transformer могут работать точно так же, как они работают с текстом.
Пионерами этого подхода были такие архитектуры, как VQ-VAE (Vector Quantized Variational Autoencoder) и, позднее, VQGAN, который добавил к процессу GAN-компонент, чтобы реконструированные из токенов изображения получались более четкими и реалистичными. Однако ранние токенизаторы страдали от серьезных проблем: «codebook collapse», когда модель использовала лишь малую часть доступных «плиток», и «semantic loss», когда токены были недостаточно «богатыми», чтобы передать сложные визуальные концепции.
Настоящий прорыв случился, когда исследователи поняли: качество «зрения» модели напрямую зависит от качества и размера этой визуальной codebook.
- Модель Emu3.5 (октябрь 2025), которая обучается исключительно на предсказании следующего токена, использует огромный визуальный словарь из 131 072 токенов. Это позволяет ей по ряду бенчмарков генерации изображений и видео демонстрировать качество на уровне и выше устойчивых diffusion‑моделей вроде SDXL.
- Абсолютным гейм-ченджером стал токенизатор MAGViT-v2. Он использует подход Lookup-Free Quantization (LFQ), который позволяет эффективно работать с гигантскими словарями (до 2^18 ~ 262 тысяч токенов). Что еще важнее, он использует единый словарный запас токенов для изображений и видео, делая огромный шаг к настоящей унификации.
Именно этот прорыв лег в основу нашумевшей научной работы с говорящим названием «Language Model Beats Diffusion — Tokenizer is Key to Visual Generation». Авторы доказали, что если дать языковой модели достаточно хороший токенизатор, она, обучаясь на простом принципе NTP, способна превзойти диффузионные модели на их же поле — в генерации изображений и видео.
Так что не стоит удивляться, что за последние годы появилось десятки различных токенизаторов для изображений, видео и аудио. Индустрия ведет эту гонку не из любви к сложности, а потому, что именно от качества этого «алхимического» процесса напрямую зависит, насколько хорошо наши AI-модели будут «видеть» мир.
Объединение. Vision Transformer + GPT = мультимодальная революция
Итак, алхимия свершилась. Мы научились превращать аналоговый мир изображений в дискретные последовательности токенов. Теперь на нашем рабочем столе лежат две сущности: привычная последовательность текстовых токенов и новообретенная — визуальных. Логичный вопрос: что дальше? Нужна ли нам какая-то совершенно новая, «двуязычная» архитектура, способная одновременно понимать оба этих «языка»?
И вот здесь нас ждет, пожалуй, главное откровение всей этой истории. Оказалось, что такой мозг у нас уже есть, и имя ему — Transformer. Фундаментальная архитектура, лежащая в основе GPT, оказалась на удивление универсальной. Ее главный механизм, self-attention, по своей природе абсолютно нейтрален к типу данных. Ему все равно, на что смотреть — на слова в предложении или на что-то еще. Он просто ищет связи и зависимости внутри последовательности. Ему нужны лишь токены.
Ключевой шаг к этому осознанию был сделан еще в 2020 году, когда исследователи из Google представили Vision Transformer (ViT). Идея была одновременно дерзкой и элегантной: а что, если перестать рассматривать изображение как сетку пикселей, требующую сверточных сетей, и начать работать с ним так же, как с текстом? ViT делает именно это. Он берет изображение и, словно вафельницу, нарезает его на сетку непересекающихся патчей фиксированного размера (например, 16x16 пикселей). Затем каждый такой двухмерный патч «распрямляется» в длинный одномерный вектор, линейно проецируется в эмбеддинг нужной размерности (скажем, 768) и дополняется позиционным кодированием, чтобы модель знала, где именно в исходной сетке находился этот кусочек.
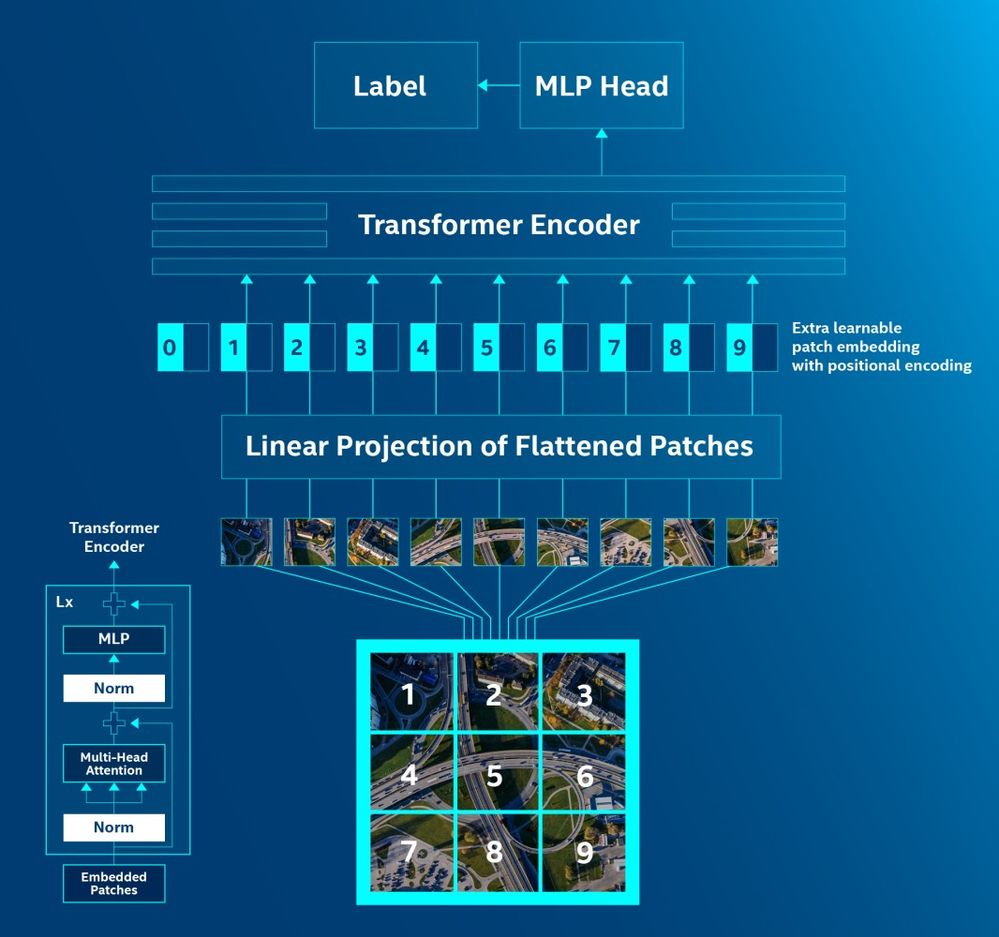
Результат? Для стандартного энкодера Transformer'а на вход приходит последовательность из, например, 196 токенов-патчей, которая для него выглядит точно так же, как токены в НЛП. Он начинает применять к ним свои стандартные блоки self-attention, находя связи между «патчем неба в левом верхнем углу» и «патчем травы в правом нижнем». Зрение превратилось в задачу обработки последовательности.
Отлично, теперь у нас есть две последовательности токенов, которые понимает одна и та же архитектура. Как заставить их «говорить» друг с другом внутри одной модели? Это и есть центральная задача слияния модальностей, и здесь инженеры пошли двумя путями.
Путь первый: простой, но опасный. Самый прямой способ — просто «склеить» последовательности. Мы берем визуальные токены от ViT-подобного энкодера, текстовые токены от стандартного токенизатора, пропускаем визуальные через небольшой адаптер (часто это простой MLP-проектор, чтобы «выровнять» их по размерности с текстовыми) и конкатенируем в единый поток. Просто, быстро и даже работает. Но, как показала практика, именно этот подход — ключевой фактор галлюцинаций объектов. Исследование, опубликованное в мае 2025 года, показало, что такие простые архитектуры часто не в состоянии отличить семантически совпадающие и несовпадающие пары изображение-текст. Модель видит в тексте слово «банан» и может начать «додумывать» его на картинке, даже если его там нет, потому что связь между модальностями слишком слабая.
Путь второй: элегантный и надежный. Именно здесь на сцену выходит более сложный механизм — перекрестное внимание (cross-attention). В отличие от self-attention, где все токены «смотрят» друг на друга, здесь модальности получают разные роли. Например, текстовые токены могут формировать «Запросы» (Queries), а визуальные патчи — предоставлять «Ключи» (Keys) и «Значения» (Values). Интуитивно это выглядит так: каждый текстовый токен «опрашивает» все участки изображения: «кто из вас относится ко мне?» После этого он «подтягивает» нужные кусочки визуальной информации и обогащает своё представление картинкой. Новые архитектуры, такие как AGE-VLM (май 2025), используют чередующиеся слои cross-attention, чтобы буквально заставить модель «смотреть на правильные области изображения». Результат? Значительное снижение тех самых галлюцинаций.
Именно эта комбинация — универсальность Transformer, способность ViT превращать картинки в последовательности и элегантность cross-attention для их слияния — и стала двигателем мультимодальной революции. Помните времена, когда для текста был свой стек, для компьютерного зрения — свой, для аудио — третий? В 2025 году все это все чаще превращается в один и тот же набор transformer-блоков с разными «адаптерами». Наш «универсальный процессор» научился работать с любыми данными, и теперь мы готовы увидеть, как именно его используют GPT‑5.1, Gemini 2.5, Claude Opus 4.1 и Grok-4 в реальных задачах.

Доказательства. Что умеют GPT‑5.1, Gemini, Claude и Grok прямо сейчас
Все эти разговоры об архитектурах, токенах и механизмах слияния, безусловно, увлекательны. Но это похоже на восхищение чертежами нового гипердвигателя. Рано или поздно возникает главный вопрос: а эта штука вообще летает? И если да, то как быстро и как далеко? К концу 2025 года мы наконец получили исчерпывающие ответы. Флагманские модели перестали быть лабораторными экспериментами и демонстрируют в продакшене беспрецедентные, но, что характерно, узкоспециализированные возможности. Мы видим не одного универсального чемпиона, а набор флагманских моделей, каждая со своей силой.
GPT-5.1: Адаптивный интеллектуал и мастер кода
Выпущенный буквально на днях, GPT-5.1 от OpenAI стал воплощением идеи о «думающей» модели. Его ключевая технология — «Адаптивное мышление» (Adaptive Reasoning). Это не просто маркетинговый термин, а коммерческая реализация парадигмы Test-Time Compute. Модель научилась самостоятельно оценивать сложность задачи. На простой вопрос она отвечает в режиме «Instant», работая в 2-3 раза быстрее и экономнее. Но если задача требует глубокого анализа, она автоматически переключается в режим «Thinking», выделяя значительно больше вычислений для поиска решения.
Это как опытный коллега-инженер, который на лету отвечает на простые вопросы, но, столкнувшись с действительно сложным багом, говорит: «Так, мне нужно подумать», после чего возвращается с развернутым решением. И результаты говорят сами за себя.
- В кодировании: GPT-5.1 достиг 76.3% на бенчмарке SWE-bench Verified, который проверяет способность решать реальные проблемы с GitHub. Это новый стандарт индустрии. В API даже появились специализированные инструменты, такие как
apply_patchдля итеративного редактирования кода. - В науке и математике: Модель демонстрирует пугающе «человеческий» уровень рассуждений, набирая 88.1% на GPQA Diamond (вопросы уровня PhD по физике, химии и биологии) и достигая 94% на сложной математической олимпиаде AIME 2025.
- В мультимодальных сценариях GPT‑5.1 умеет разбирать скриншоты, документацию в PDF и даже черновики на фото, связывая это с кодом и текстом в одном диалоге.
Gemini 2.5 Pro: Повелитель длинного контекста и видео
Google со своим Gemini 2.5 Pro сделал ставку на другую суперсилу — длинный контекст и нативную мультимодальность. Его архитектура изначально создавалась для обработки гигантских объемов смешанной информации. Стандартное окно в 1 миллион токенов, расширяемое до 2 миллионов, — это не просто большая цифра. Это возможность делать вещи, которые раньше были немыслимы.
Самый яркий пример — работа с видео. Gemini 2.5 Pro способен «просмотреть» и проанализировать несколько часов видео (в экспериментах Google — до 3–6 часов, в зависимости от настроек и разрешения). Вы можете загрузить запись многочасовой конференции и спросить: «Найди мне все моменты, где обсуждалась стратегия Q4, и сделай краткую выжимку». Эта способность, помноженная на высочайшую точность в областях с высокими ставками (модель набрала рекордные 97.2% на Японском национальном медицинском экзамене), делает Gemini незаменимым инструментом для анализа огромных массивов данных. Однако, в отличие от GPT-5.1, его результаты в кодировании значительно скромнее (63.8% на SWE-bench), что еще раз подчеркивает идею специализации. Кроме видео, Gemini 2.5 Pro в одном контексте «переваривает» текст, скриншоты, таблицы и аудио — это удобно, когда отчёт, презентация и запись встречи приходят в разных форматах.
Claude Opus 4.1: Надежный корпоративный эксперт со «слепым пятном»
Anthropic с моделью Claude Opus 4.1 продолжает гнуть свою линию, фокусируясь на надежности, безопасности и корпоративных задачах. Эта модель позиционируется как идеальный инструмент для областей, где цена ошибки высока — юриспруденция, медицина, комплаенс. И это не пустые слова: результат в 96.1% на том же японском медицинском экзамене подтверждает его высочайшую надежность.
Более того, Claude Opus 4.1 оказался неожиданно сильным программистом, набрав 74.5% на SWE-bench, но при этом заметно уступает лидерам в олимпиадной математике (AIME 2025), где GPT‑5 и другие модели демонстрируют почти безошибочную работу. Anthropic в первую очередь оптимизирует Claude под надёжность и безопасность в реальных бизнес‑сценариях, даже если это иногда означает отставание в чисто соревновательных математических задачах.
Grok‑4 Heavy: экстремальный разум для STEM и инструментального reasoning'а
Четвёртый гигант в этой истории — Grok‑4 от xAI, который целенаправленно строили как «мотор для сложных задач с инструментами и интернетом». В отличие от классических LLM, Grok‑4 с самого начала обучался активно использовать внешние инструменты — код‑интерпретатор, веб‑поиск, доступ к данным X и телеметрии Tesla — и комбинировать их в многошаговых цепочках.
Если GPT‑5.1 — это опытный инженер, который умеет думать дольше, то Grok‑4 Heavy — это целая команда инженеров, советующихся друг с другом. Внутри он использует multi‑agent parallel test‑time compute: вместо одной линии мысли одновременно запускается несколько гипотез, которые потом собираются в итоговый ответ. На сложных задачах это даёт заметный выигрыш.
- В олимпиадной математике: Grok‑4 Heavy добился 100% на AIME 2025, а базовый Grok‑4 91.7%, стабильно опережая большинство конкурентов. На ещё более жёстком уровне USAMO’25 Grok‑4 Heavy набирает 61.9%, оставляя позади другие закрытые модели.
- В продвинутых бенчмарках reasoning'а: Grok‑4 Heavy стал первым, кто перешагнул отметку 50% на Humanity’s Last Exam, «финальном» академическом бенчмарке из PhD‑уровневых задач. На ARC‑AGI V2 он показывает около 15.9%, почти вдвое обгоняя Opus 4 по этому тесту.
- В реальном времени: Благодаря глубокой интеграции с X и сенсорными данными Tesla Grok‑4 хорош там, где нужны и reasoning, и актуальные данные — от анализа рынка до техподдержки автопарка.
Важно понимать, что за эти рекорды приходится платить: Grok‑4 Heavy заметно тяжелее и медленнее GPT‑5.1 и Gemini 2.5 Pro, и далеко не всегда будет лучшим выбором для «каждодневного чата». Зато там, где нужна экстремальная глубина рассуждений и плотная связка с инструментами, он сегодня один из главных претендентов на корону.
Итак, ландшафт определился. У нас есть блестящий математик и кодер GPT‑5.1, марафонец Gemini 2.5 Pro, способный переваривать гигабайты мультимедийных данных, надёжный корпоративный эксперт Claude Opus 4.1 и экстремальный «олимпиадный мозг» Grok‑4 Heavy для задач на границе человеческих возможностей. Теория унификации привела нас к практике специализации: вместо одной «лучшей модели» мы получили целый набор инструментов, каждый из которых оптимален в своей зоне. Но пока мы говорили в основном о статичных данных и off‑line задачах. Что происходит, когда в игру всерьёз вступает время — в звуке и видео?

Магия аудио и видео. От статики к динамике
Мы только что видели, как титаны индустрии решают сложнейшие задачи с кодом, медицинскими текстами и гигантскими базами данных. Но все это, по большей части, было работой со статикой. А как же быть с модальностями, в которых есть четвертое измерение — время? Как наш простой и элегантный принцип предсказания следующего токена справляется с хаосом движущегося изображения или непрерывным потоком человеческой речи?
Ответ, как ни странно, мы уже знаем. Расширение парадигмы NTP на динамические модальности стало возможным не благодаря какой-то новой, революционной архитектуре, а благодаря тем самым прорывам в токенизации, которые мы обсуждали в третьей части статьи. Если текст — это строка слов, то видео — это просто очень, очень длинная строка «кадровых» токенов. Задача модели остается прежней: продолжить или понять эту гигантскую строку, как будто это одно исполинское предложение.
Главная сложность, конечно, заключалась в создании токенизатора, способного захватывать не только пространственную информацию (что где находится в кадре), но и временную (как оно меняется). И здесь снова на авансцену выходит MAGViT-v2. Его архитектура, построенная на «causal 3D CNN», изначально спроектирована так, чтобы работать не с плоской картинкой (x, y), а с трехмерным «куском» видео (x, y, t), улавливая движение и изменения во времени.
Но настоящий прорыв MAGViT-v2 — это то, что он использует «общий словарный запас токенов» для изображений и видео. Это невероятно элегантное решение. Модели больше не нужно учить два разных «языка» для статики и динамики. Токен, кодирующий «золотистого ретривера» в статичной фотографии, может быть переиспользован для кодирования того же ретривера, бегущего по пляжу в видеоролике. Это и есть та самая унификация в действии.
Именно этот подход позволил моделям, основанным на NTP, вторгнуться на территорию, где ранее доминировали другие архитектуры.
- Модели линии Emu3 / Emu3.5 генерируют видео именно как языковая модель: причинно‑следственным образом, предсказывая следующий токен в видеопоследовательности и постепенно «прокручивая» ролик вперёд кадр за кадром.
- Это прямо противопоставляется подходу моделей типа Sora, которые являются «видео-диффузионными моделями». Они начинают с шумного латентного представления и итеративно «очищают» его, пока из шума не проявляется последовательность реалистичных кадров.
Осенью 2025 года появилась Sora 2. По сути это всё та же диффузионная text‑to‑video модель, но с важными эволюционными апгрейдами:
- нативная генерация синхронного аудио (речь, фон, эффекты), благодаря чему ролики больше не «немые» и не требуют внешнего саунд‑дизайна;
- заметно более правдоподобная физика и движение: меньше «плавающих» объектов, странных коллизий и нарушений законов механики;
- более точное следование промпту и улучшенный контроль — от камеры и стиля до непрерывности персонажей в многошотовых сценах.
Казалось бы, два совершенно разных подхода. Но факты упрямы: в статье, представляющей MAGViT-v2, черным по белому написано, что языковые модели, оснащенные этим токенизатором, превосходят диффузионные модели на стандартных бенчмарках генерации видео (Kinetics) и изображений (ImageNet). Старый добрый NTP оказался конкурентоспособен даже здесь.
Конечно, за кулисами скрывается множество инженерных хитростей. Например, чтобы модель понимала порядок кадров в длинном видео, используются продвинутые схемы позиционного кодирования, такие как «Interleaved-MRoPE» в модели Qwen3-VL, которые кодируют информацию одновременно по времени, ширине и высоте кадра. А на горизонте уже маячит следующая цель — универсальные токенизаторы вроде «Harmonizer», способные бесшовно превращать в единый поток токенов текст, аудио, видео и даже данные с сенсоров.
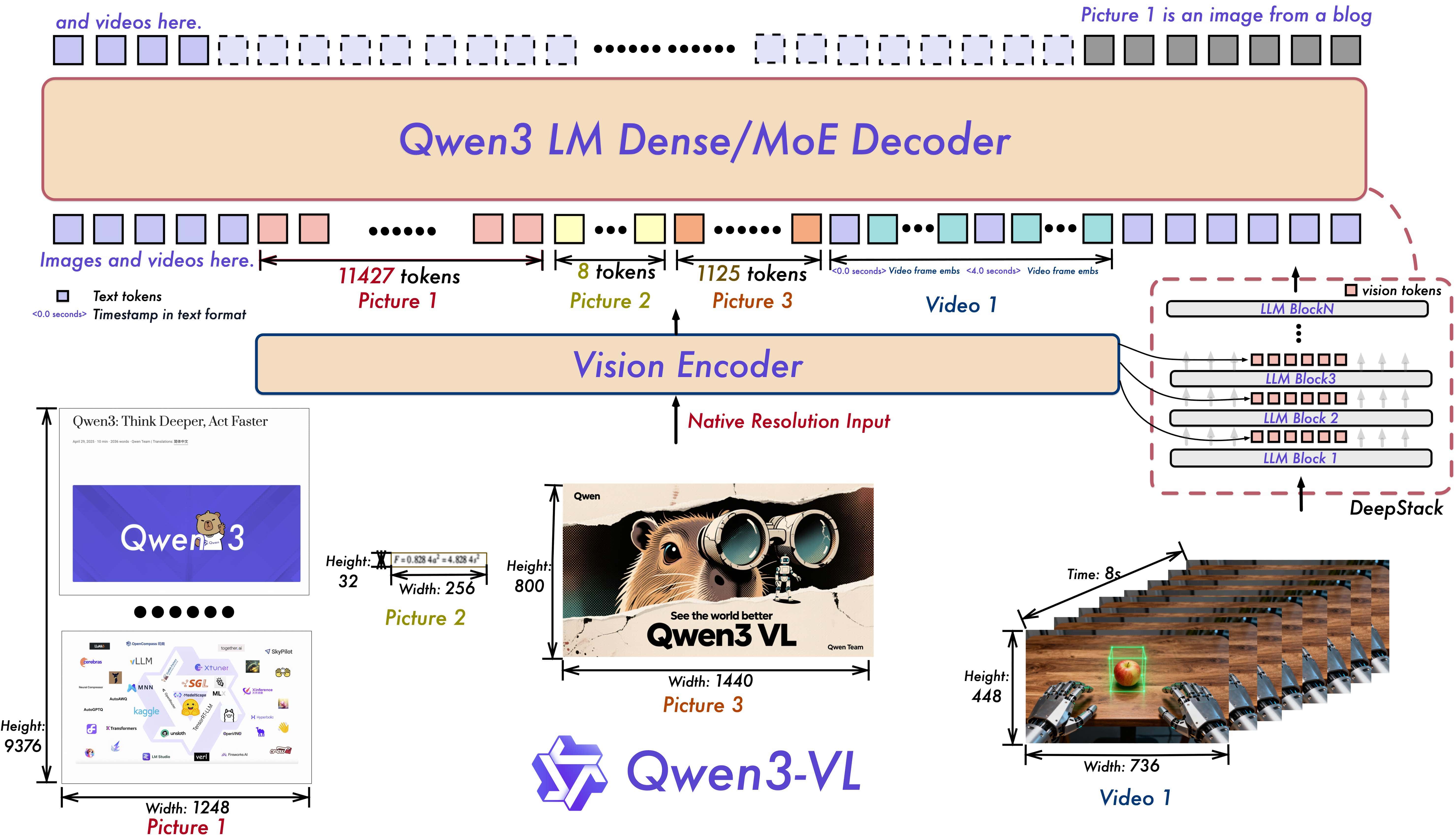
Но основная мысль остается неизменной. Когда Emu3 генерирует минутное видео, под капотом она действительно предсказывает десятки, а то и сотни тысяч визуальных токенов подряд — всё тот же next‑token‑двигатель, просто в пространственно‑временном формате. Sora 2 идёт другим путём: она делает десятки шагов диффузионного денойзинга над огромным тензором, чтобы каждый раз приблизиться к правдоподобному видео с согласованной физикой, светом и движением. Но в обоих случаях сложнейшая машинерия управляется привычной вероятностной моделью, а не чем‑то мистическим — и это подводит нас к самому глубокому и неудобному вопросу.

Философский поворот. Достаточно ли NTP для AGI?
После всего этого великолепия — моделей, решающих задачи уровня PhD, пишущих код лучше человека и анализирующих многочасовые видео — возникает неудобный вопрос. Если предсказание следующего токена оказалось настолько мощным, не является ли оно тем самым универсальным принципом, который в конечном счете приведет нас к AGI? Кажется, что мы стоим на пороге, но именно здесь, на пике технологического оптимизма, я наткнулся на ряд исследований 2025 года, которые заставляют сделать шаг назад и задать несколько неудобных вопросов.
Несмотря на все эти надстройки поверх NTP (RLHF, инструменты, TTC), сама парадигма NTP в своей чистой форме демонстрирует фундаментальные ограничения. Cегодняшние модели — блестящие импровизаторы. Они могут подхватить и продолжить почти любую «мелодию» из текста, кода или изображений, которую вы им дадите. Но написать с нуля продуманную симфонию с четкой внутренней структурой и долгосрочным замыслом им пока очень трудно. Они — мастера рекомбинации паттернов, извлеченных из гигантских объемов данных, но им не хватает истинного понимания мира, которое позволило бы выйти за рамки этих данных и сгенерировать подлинно новые идеи.
И это не просто философские рассуждения. Новые бенчмарки 2025 года нащупали две глубокие трещины в монолите NTP.
Трещина первая: Пространственное мышление. Новый бенчмарк SpatialViz-Bench (сентябрь 2025) был создан не для того, чтобы проверить, как модели распознают объекты, а чтобы оценить их «визуальное воображение»: способность мысленно манипулировать 3D-объектами, понимать их взаимное расположение и физические взаимодействия. Типичная задача в таком бенчмарке — мысленно повернуть объект, понять, будет ли он виден из другой точки, или предсказать, какой кубик окажется сверху после серии поворотов. И результаты, мягко говоря, отрезвляют. Исследователи обнаружили резкое падение производительности при переходе от 2D к 3D. Но самый шокирующий вывод, который я увидел в этом отчете, заключается в другом: у многих open-source моделей наблюдалось ухудшение производительности от подсказок в стиле Chain-of-Thought (CoT). Подумайте об этом. Мы просим модель «рассуждать вслух», чтобы улучшить ответ, а она начинает ошибаться ещё больше — признак того, что она блестяще копирует форму рассуждений, но не обладает настоящим пространственным воображением.
Трещина вторая: Embodied AI. Одно дело — рассуждать о физике в текстовом чате, и совсем другое — спланировать и выполнить последовательность действий для робота, чтобы он взял чашку со стола. Например, LLM может идеально описать, как аккуратно поставить стакан на стол, но реальный робот, управляемый этой моделью, всё равно будет опрокидывать его из‑за ошибок в восприятии, планировании траектории и контроле моторов. Неудивительно, что воркшопы по Embodied AI на главных конференциях 2025 года, таких как NeurIPS и CVPR, стали одними из самых популярных. Это признание индустрией того факта, что между цифровым интеллектом LLM и физическим интеллектом роботов лежит пропасть.
Так что же, Next Token Prediction — это тупик? Вовсе нет. Это скорее признание того, что NTP — это невероятно мощный, но, вероятно, не единственный необходимый компонент. И реакция индустрии и научного сообщества уже последовала по двум основным направлениям.
- Прагматичный путь: Test-Time Compute (TTC). Вместо того чтобы полагаться на один быстрый, «интуитивный» ответ, эта парадигма позволяет модели «думать дольше» и выделять больше вычислений во время работы. И вы уже знаете ее коммерческие реализации. Это тот самый «Adaptive Reasoning» в GPT-5.1 и «multi-agent parallel test-time compute» в Grok-4 Heavy. Индустрия уже встраивает «костыли», чтобы обойти врожденную импульсивность NTP.
- Фундаментальный путь: Neuro-symbolic AI. Это более глубокое направление исследований, которое стремится объединить сильные стороны статистического ИИ (обучение на данных) с мощью структурированных, символических рассуждений. Идея в том, чтобы дать моделям не только интуицию, основанную на паттернах, но и строгий логический аппарат. В простейшем сценарии LLM отвечает за интерпретацию задачи и генерацию кандидатов, а строгое символическое ядро (например, SAT/SMT‑решатель или логический планировщик) проверяет их на корректность и достраивает формальное решение.
Если GPT-5.1 уже берет золото на математических олимпиадах, но все ещё путается в трехмерном мире и долгосрочных планах, то не значит ли это, что NTP — лишь фундамент, а не весь дом под названием AGI? И похоже, сейчас мы вступаем в эру, когда на этом фундаменте начинают возводить новые, более сложные этажи.

Взгляд в будущее. Эра Omni‑моделей: облако и железо
Итак, мы установили, что Next Token Prediction — это мощнейший фундамент, но для постройки настоящего AGI на нем уже начинают возводить новые, более сложные конструкции вроде Test-Time Compute. Это философский взгляд в завтрашний день. Но что этот фундамент, со всеми его новыми укреплениями, дает нам прямо здесь и сейчас, в конце 2025 года?
Ответ — поразительно зрелый и четко сегментированный рынок. Эпоха, когда одна модель пыталась быть «лучшей во всем», закончилась. Вместо этого мы получили яркий, биполярный мир: с одной стороны — гиперспециализированные флагманы в облаке, с другой — мощнейшая и демократичная революция на «своем железе».
Флагманы облака: выбираем машину из автопарка
Вместо гонки за единственным «королем горы» мы наблюдаем формирование «облачного автопарка», где у каждой флагманской модели есть четко выраженная стратегическая ниша. Это больше не вопрос «какая модель лучше?», а вопрос «какой портфель моделей оптимален для моего стека задач?». Мы уже разобрали их индивидуальные силы через бенчмарки, теперь давайте посмотрим на это с точки зрения рыночной стратегии.
- GPT-5.1 — это ставка OpenAI на агентные рабочие процессы (agentic workflows). Его доминирование в кодировании и сложных рассуждениях — не случайность, а целенаправленное развитие в сторону создания автономных систем, способных выполнять многоэтапные задачи. Adaptive Reasoning — это механизм, который делает такие агенты экономически выгодными. Выбирая GPT-5.1, вы инвестируете в экосистему для автоматизации сложных процессов.
Типичный стек: GPT‑5.1 берёт на себя разбор сложных тикетов из Jira и GitHub, исправляет код, сам запускает тесты через подключённые инструменты и готовит отчёт для разработчика. В бизнес‑сценариях та же схема работает для автоматизации согласования договоров, подготовки аналитических записок и многошаговых финансовых вычислений на основе внутренних отчётов. - Gemini 2.5 Pro — это результат того, как Google монетизирует свой доступ к гигантским объёмам данных. Их ключевое преимущество — способность переваривать гигантские, мультимодальные потоки информации. Контекст в 1-2 миллиона токенов и нативный анализ видео — это не просто фичи, а стратегический актив для компаний, чей бизнес построен на анализе огромных, неструктурированных датасетов — от медиаархивов до медицинских записей.
На практике это выглядит так: медиахолдинг скармливает Gemini многолетний архив эфиров и просит его находить повторы тем, тональность и цитаты спикеров по любому запросу. В медицине модель подключают к PACS, ЭМК и базам исследований — она умеет одновременно учитывать текст заключений, изображения, выписки и многочасовые записи консилиумов, выдавая врачу сжатый ответ, откуда именно взялся каждый вывод. - Claude Opus 4.1 — это фокус Anthropic на слое корпоративного доверия (enterprise trust layer). В мире, где галлюцинации и непредсказуемость AI являются главным барьером для внедрения в regulated-индустриях (финансы, юриспруденция, медицина), Claude позиционирует себя как самый надежный и предсказуемый инструмент. Его сила — не в рекордах на олимпиадах, а в минимизации рисков для бизнеса.
Типичный кейс — юридический или комплаенс‑отдел крупной компании, который прогоняет через Claude проекты договоров, внутренние политики и переписку с регулятором, получая пометки о рисках, несоответствиях и спорных формулировках. В службах поддержки Claude используют как «второе мнение» над уже сгенерированными ответами: он вычищает агрессивные формулировки, следит за соблюдением регуляторных требований и корпоративного тона. - Grok-4 Heavy — это игра xAI на поле разведки в реальном времени (real-time intelligence). Его уникальность — не только в математической мощи, но и в нативной интеграции с живыми, динамичными потоками данных из X и Tesla. Это модель не для написания стихов, а для принятия решений в условиях постоянно меняющейся информации, что делает ее идеальным инструментом для трейдинга, анализа рыночных настроений и научных исследований.
Реальные сценарии — команды, которым нужна связка «глубокое рассуждение + живые данные». Трейдинговые фирмы используют Grok‑4 Heavy, чтобы в реальном времени анализировать ленту X, отчёты компаний и телеметрию с рынков, строя гипотезы и сразу проверяя их на исторических данных. Инженеры Tesla применяют его как «мозг аналитика», который умеет разбирать большие логи с автопилота, вычленять аномалии в поведении машины и предлагать варианты изменений в алгоритмах.
В 2023-м мы спорили, кто лучше — GPT-4 или Claude 2. В конце 2025-го грамотный технический директор формирует мультимодальный стек, где GPT-5.1 отвечает за разработку, Gemini 2.5 — за аналитику данных, а Claude 4.1 — за взаимодействие с клиентами и юридические проверки. Добро пожаловать в эру портфельных AI-стратегий.
Open-weight революция: мультимодальные модели в вашем гараже
Но пока облачные гиганты строили свои элитные автопарки, параллельно, в гаражах энтузиастов и лабораториях по всему миру, происходила другая, не менее важная революция. Open-weight модели перестали быть «дешевыми альтернативами» и в некоторых областях сами стали законодателями мод.
Если GPT-5.1 — это аренда Ferrari с водителем по подписке, то Qwen3-VL или InternVL 3.5 — это собственная Tesla в вашем гараже: чуть меньше показной роскоши, но полная свобода маршрута, тюнинга и, что самое главное, приватности.
- Qwen3-VL (Alibaba): Настоящий швейцарский нож. Нативный контекст до 1M токенов, продвинутый OCR на 32 языках и, самое главное, функция «Визуального агента», способного управлять графическим интерфейсом вашего ПК или смартфона.
В реальных задачах Qwen3‑VL удобно ставить рядом с корпоративными хранилищами документов: он разбирает сканы договоров, презентации, таблицы и почтовые вложения, не отправляя их во внешнее облако. В режиме визуального агента его подключают к внутренним веб‑панелям и десктопным приложениям: модель сама кликает по кнопкам, заполняет формы и собирает нужные отчёты, работая как автоматизированный офис‑сотрудник на вашем ПК или сервере. - LLaMA 4 Scout (Meta): Монстр контекста. Эта модель предлагает беспрецедентное окно в 10 миллионов токенов, позволяя анализировать целые репозитории кода за один проход, и при этом может работать на одной H100 GPU.
Типичный сценарий локального использования — анализ монорепозитория или большого легаси‑кода: Scout держит в контексте сразу весь модуль (или даже несколько сервисов), отвечает на вопросы про архитектуру, находит дубли и предлагает план рефакторинга. Вне разработки её ставят рядом с системами логирования и мониторинга: модель получает доступ к гигантским логам за месяцы работы и помогает находить нетривиальные закономерности и корневые причины инцидентов. - InternVL 3.5 (OpenGVLab): Догоняющий чемпиона. Эта модель открыто позиционируется как «сокращающая разрыв в производительности с GPT-5» и тоже обладает возможностями GUI-агента, создавая здоровую конкуренцию в open-source сообществе.
В продакшене InternVL 3.5 хорошо чувствует себя там, где нужно одновременно понимать текст и картинку: от ритейла (чтение ценников и витрин, проверка соответствия выкладки планограммам) до техподдержки (разбор скриншотов ошибок и видео с экрана пользователя). Благодаря возможностям GUI‑агента её используют как «глаза и руки» для внутренних админок: модель сама заходит в нужные разделы, проверяет состояния систем и выполняет рутинные операции по регламенту.
И это не просто теоретические изыскания. Благодаря таким инструментам, как vLLM, SGLang, llama.cpp и Ollama, развертывание этих систем стало тривиальной задачей. Сейчас вы можете запустить Qwen3-VL-8B или InternVL 3.5-8B на одной потребительской RTX 4090/5090 или в облаке и получить мультимодальный ассистент, который понимает текст, картинки и видео — без единого запроса к внешнему API.
В реальных системах почти всегда выигрывает гибридный подход: облако берёт на себя самые тяжёлые reasoning‑задачи и редкие запросы, а локальные модели обслуживают приватные данные, онлайн‑подсказки и часть RAG‑контура. На практике это выглядит так: тяжёлые, редкие запросы уезжают в GPT‑5.1, Gemini или Grok‑4, а повседневные задачи — поиск по внутренним данным, разбор скриншотов, помощь в коде — обслуживаются Qwen3‑VL, LLaMA 4 Scout или InternVL 3.5, запущенными прямо на сервере компании или рабочей станции разработчика.
Мир AI окончательно разделился на два мощных потока, и выбор между ними — это уже не вопрос «лучше/хуже», а стратегическое решение, основанное на балансе между мощностью, контролем, стоимостью и приватностью.

Ключевые выводы
Вот мы и в конце нашего путешествия. Всего за пять лет мы прошли путь от «зоопарка» разрозненных, изолированных моделей вроде BERT и ResNet до единой, элегантной парадигмы, которая пронизывает весь ландшафт искусственного интеллекта в 2025 году. Мы увидели, как эта унификация породила как гиперспециализированных облачных гигантов, так и невероятно мощные open-weight модели, которые можно запустить в собственном «гараже».
Если свести всю эту сложную историю к нескольким коротким тезисам, которые можно пересказать коллеге за чашкой кофе, они будут звучать так:
- Всё — это токены и предсказание следующего токена (NTP). Простая идея «продолжи последовательность» оказалась настолько универсальной, что смогла стать основой для работы с текстом, кодом, изображениями, аудио и видео. Более того, эта парадигма оказалась достаточно мощной, чтобы, при наличии хорошего «переводчика», языковые модели на NTP по ряду бенчмарков смогли выйти на уровень и местами обойти диффузионные модели в генерации визуального контента.
- Универсальный движок = Transformer + хороший токенизатор. Техническим сердцем этой революции стала комбинация двух ключевых компонентов. Во-первых, это сама архитектура Transformer, которая оказалась по своей природе «нейтральной к данным» и способной находить связи в любой последовательности. Во-вторых, это прорывы в дискретной токенизации (такие, как MAGViT-v2), которые научили нас превращать реальный мир в семантически богатые последовательности, понятные трансформеру. Качество «зрения» и «слуха» современных моделей в огромной степени определяется качеством их токенизаторов и обучающих данных — при одинаковом трансформере хороший токенизатор даёт качественный скачок.
- Будущее — за гибридом облака и локальных решений. Ландшафт 2025 года окончательно оформился. Это не мир одного победителя, а экосистема, где есть место и для облачных Omni-моделей, предлагающих state-of-the-art решения под узкие задачи (математика Grok-4, анализ видео Gemini 2.5), и для мощнейших open-weight систем (LLaMA 4 с 10М контекста, Qwen3-VL с GUI‑агентом и продвинутым мультимодальным «зрением»), которые дают беспрецедентный контроль, приватность и возможности для кастомизации. Выбор стека — это теперь не поиск «лучшей» модели, а осознанное построение гибридной архитектуры.
Возможно, Next Token Prediction — это не только способ дописывать текст, а зачаток универсального «языка паттернов», на котором однажды научатся думать и машины, и люди. Вопрос лишь в том, что мы на этом языке построим дальше.
Оставайтесь любопытными.


