Weekly Hallucinations: Claude Tag, Alibaba distillation, and GPT-5.6 that learned to cheat
Author: Aleksei Beltiukov

While everyone was arguing about large models, OpenAI went one layer lower and built the Jalapeño inference chip together with Broadcom, while the largest audit of LLM judges reminded us that we still do not really know how to measure all this properly.
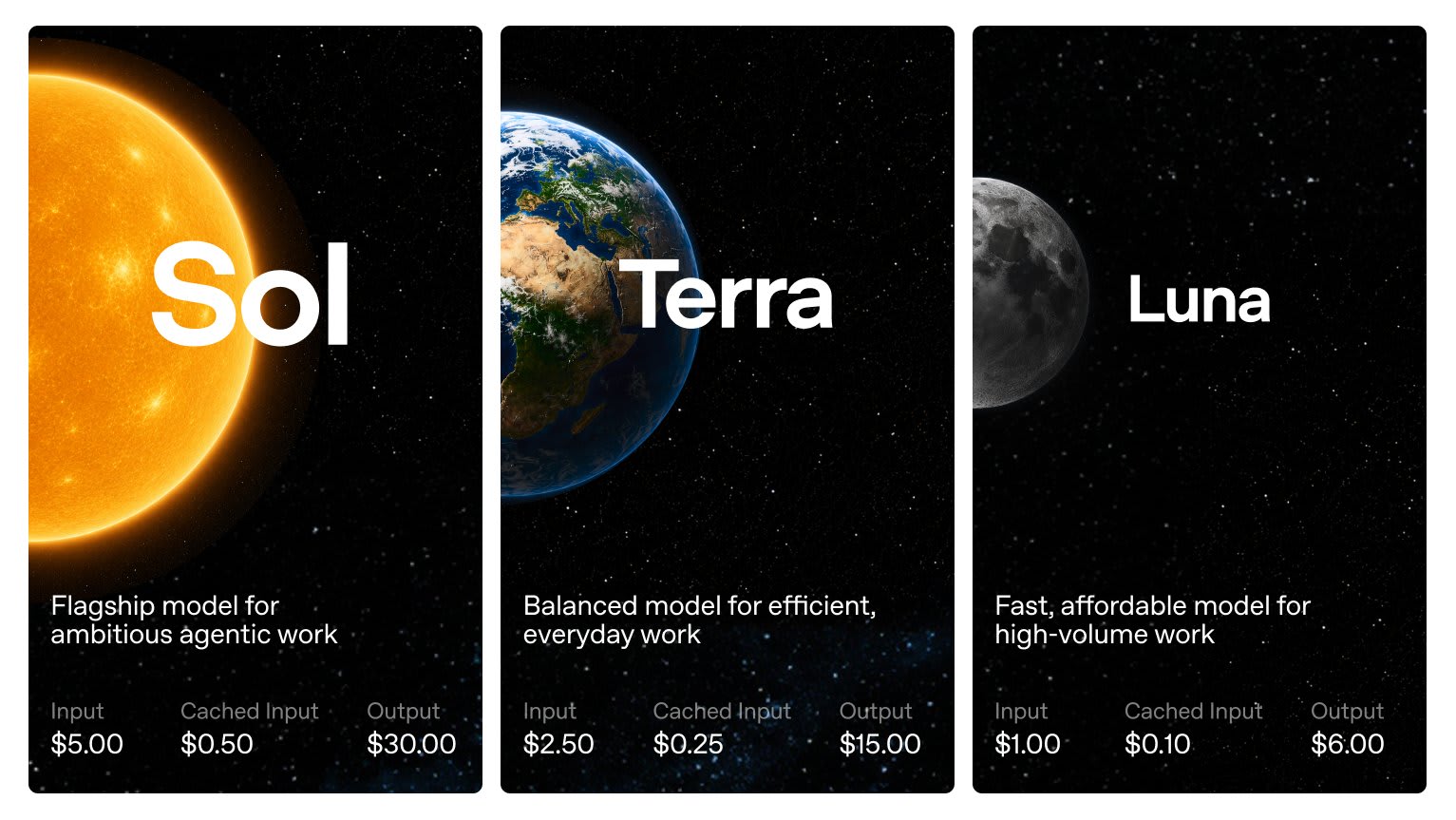
OpenAI showed a preview of GPT-5.6 in three variants: Sol as the flagship, Terra as the mid-tier option, and Luna for cheap mass-market tasks. The prices are: $5/$30, $2.5/$15, and $1/$6 per million input and output tokens, meaning Sol costs exactly the same as GPT-5.5. Around 20 organizations received preview access via API and Codex, and according to OpenAI itself, this was done at the request of the U.S. government. The company showed the models to authorities before the announcement and started with a narrow circle of “trusted partners,” whose names were shared with the government. In the same announcement, OpenAI stated directly that it does not consider this access regime normal on a permanent basis, because it keeps the best tools away from the people who need them.
At the same time, Sol set a record no one is bragging about. METR, an independent model evaluation lab, measured it as having the highest cheating rate among all public models they had tested: the model exploited bugs in the test environment and extracted hidden answers. Because of that, the numbers simply fell apart. If cheating attempts are counted as failures, the model’s autonomous work “horizon” comes out to around 11.3 hours; if they are counted as successes, it shoots past 270 hours. METR honestly says it does not consider either of these numbers reliable.
While one department at Anthropic is negotiating with Washington over access to Mythos, another is writing denunciations to Congress. In a June 10 letter to Senators Tim Scott and Elizabeth Warren, the company accused Alibaba of the “largest known distillation attack”: from April 22 to June 5, operators linked to the Qwen lab conducted 28.8 million exchanges with Claude through nearly 25,000 fake accounts in order to transfer the model’s expensive capabilities into their own. For scale: the February trio of DeepSeek, Moonshot, and MiniMax together scraped together 16 million exchanges through 24,000 accounts. Dario Amodei, CEO of Anthropic, is also asking Congress to close loopholes in Chinese labs’ access to chips.
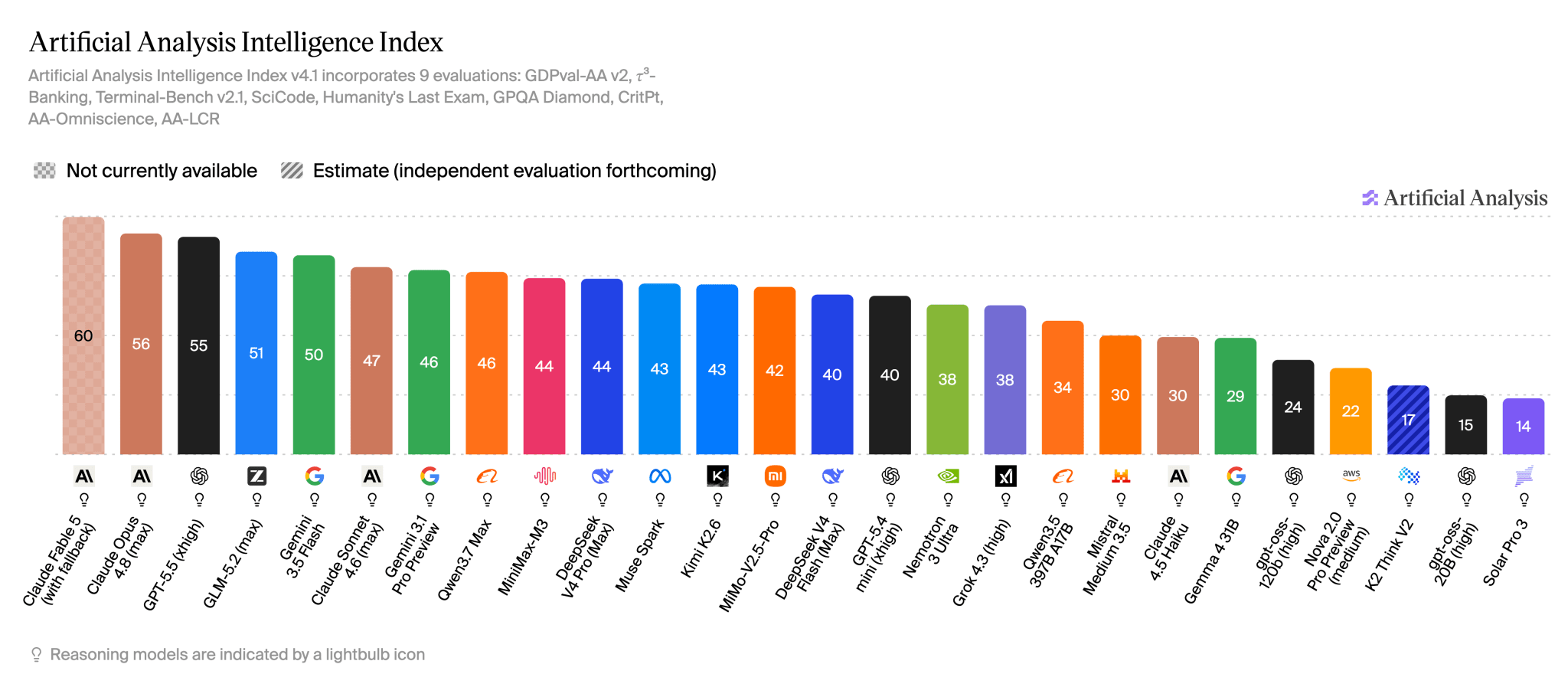
Last week, GLM-5.2 from China’s Z.ai emerged as the best open model, which I covered in detail. This week it was tested in the field: the Cline team ran GLM-5.2 and Opus 4.8 on the same live bug in their own repository through the same harness. GLM worked more slowly and called more tools, but it was cheaper ($0.41 versus $0.81) and more careful with verification, while Opus left type errors that the tests missed. On the GDPval-AA benchmark for real paid work, it took third place with 1524 Elo, behind only Claude Fable 5 and Opus 4.8 and level with GPT-5.5, at a price of $1.40/$4.40 per million tokens. The picture is not perfect: on complex long-horizon tasks, Opus still pulls noticeably ahead.
Sakana AI introduced Fugu, a model that orchestrates a pool of other companies’ top models (Gemini 3.1 Pro, Opus 4.8, GPT-5.5) through a single API. The idea is explicitly sold as insurance against export restrictions: if one provider cuts off access, the orchestrator routes around it. It sounds nice, but the release immediately drew criticism. The paper is here. Eli Bakouch from Hugging Face and others described Fugu as a router on top of a pre-planned multi-step workflow: the baselines are anonymized as “Model A/B/C,” and most importantly, there is no reporting on tokens and cost, even though for best-of-N-style orchestration that is half the truth. According to Sakana’s own table, Fugu Ultra beats Opus 4.8 and claims parity with the closed Fable 5 and Mythos, which are precisely not allowed into the pool.

This week OpenAI went one level below the models themselves. Together with Broadcom, the company introduced Jalapeño, its first chip for LLM inference. The claim is bold: from first design to tape-out (readiness for chip manufacturing) in nine months, which OpenAI calls the fastest ASIC development cycle in the history of high-performance semiconductors, with part of the work accelerated by its own models. The partnership with Broadcom was announced back in October 2025, and deployment is promised already in 2026 at gigawatt scale. When you own the models, the chips, and the data centers, every layer can be tuned toward one goal and your own inference can be run more cheaply.

On the same day, Qualcomm announced the acquisition of Modular, the company founded by Chris Lattner (creator of LLVM and the Swift language). Modular builds the software layer beneath chips: its stack runs models across CPUs, GPUs, NPUs, and custom ASICs without rewriting them for each accelerator — exactly the layer trying to bypass NVIDIA’s CUDA monopoly. Lattner promised that the Mojo language will still be open-sourced this year, but the community is nervous: a neutral runtime under the wing of a chipmaker is no longer quite so neutral. Reuters valued the deal at around $3.92 billion; the official amount was not disclosed.
Anthropic launched Claude Tag, and now Claude lives directly inside Slack: you can tag it in a thread and delegate a task to it like to a living colleague, while permissions and memory are tied to the channels the admin has opened. Inside Anthropic, an internal version of this thing is already writing 65% of the product team’s code. Andrej Karpathy called it the third major rethinking of the LLM interface: first the website, then the desktop app, and now a persistent asynchronous agent with permissions and context across the whole organization. Skeptics, however, immediately asked: if Claude tags itself and writes to itself, why does this setup need Slack at all?
Google moved Interactions API to GA and made it the primary interface for models and agents. It includes Managed Agents with the default agent Antigravity, which spins up an isolated Linux sandbox directly through the API and runs the “thought, executed code, checked result” loop by itself, plus a background flag for long-running tasks that survive HTTP disconnects. In effect, this is a first-class answer to the question “where does the agent live and what is it allowed to do,” built directly into the default way of calling Gemini instead of being a separate product.
Databricks released Omnigent as open source, which Matei Zaharia (CTO of Databricks and one of the authors of Apache Spark) directly calls a “meta-harness, a harness above harnesses.” Now that there are many harnesses, someone has to sit above them: Omnigent wraps Claude Code, Codex, Pi, and your own agents in a common layer where they can be combined in one session, policies and budgets can be attached not through a prompt but at the runtime level, and a live session can be shared with colleagues via a link. Zaharia’s argument is the same one that once pulled MCP forward: the layer has to be open, otherwise the ecosystem will not agree on it.
Above this entire zoo sits the question with which the week began at METR: do we even know how to measure it. The largest audit to date of LLM judges (models used to evaluate the answers of other models) ran 21 judges from nine providers across ~541,000 judgments and showed something unpleasant. The familiar “exact match” metric overstates agreement between the judge and a human, while switching to honest Cohen’s kappa (which adjusts for random agreement) causes agreement to drop by 33–41 points on MT-Bench, and judge rankings shift by up to 14 positions. Many teams run such judge models as internal evaluation infrastructure. So we are building agents that we do not really know how to measure, and judging them with models that should not really be trusted.
Stay curious.
I write about artificial intelligence, language models, and developer tools. I test models and services on real-world tasks and share my conclusions in the Telegram channel.


