Галлюцинации недели: Gemma 4 12B, Odysseus от PewDiePie и MiniMax M3, который научился видеть
Автор: Алексей Бельтюков

NVIDIA закрывает Computex тремя релизами, Microsoft показывает сразу семь моделей MAI, а серия Opus развивается по-своему: 4.7 ленился, 4.8 врёт, 4.9 будет просить на додеп.
Залп NVIDIA открыл Cosmos 3, открытая омнимодальная world-модель, держит в одной архитектуре Mixture-of-Transformers язык, картинки, видео, звук и действия. Устроена она так: сначала reasoner-блок разбирается, что происходит в сцене, потом генеративный блок это дорисовывает, поэтому физика в роликах ведёт себя осмысленнее. По замерам Artificial Analysis post-training версии встали на первое место среди открытых моделей в text-to-image и image-to-video. Целятся в робототехнику: модель выдаёт и видео, и числовые траектории движения, то есть готовые данные для обучения роботов.
Следом Дженсен Хуанг показал Nemotron 3 Ultra, сильнейшую на сегодня открытую модель из США. 550 миллиардов параметров, из них активны 55 (это MoE, где на каждый токен работает только часть сети). Архитектура гибридная, Mamba плюс attention, претрейн целиком в NVFP4 на 20 триллионах токенов, контекст до миллиона. По индексу интеллекта Artificial Analysis она набрала 47.7, обойдя все американские открытые модели, но всё ещё уступая китайской Kimi K2.6 с её 53.9. Зато быстрая: NVIDIA заявляет до 5 раз выше пропускную способность, чем у конкурентов того же класса, что для долгих агентских задач важнее лишнего балла на бенчмарке.
Под занавес NVIDIA вышла на территорию ПК с RTX Spark, "персональным AI-компьютером" на связке Grace и Blackwell: до 128 ГБ общей памяти, 1 петафлопс в FP4, обещание гонять локально модели на 120B параметров. Но случился конфуз. Половина изданий написала про 600 ГБ/с пропускной способности памяти, хотя на деле это скорость интерконнекта NVLink-C2C между процессором и видеоядром, а сама память LPDDR5X выдаёт примерно 273–300 ГБ/с. Для локального инференса считается именно вторая, меньшая цифра, так что половину "пропускной способности" дорисовал маркетинг на пару с невнимательными перепечатками.

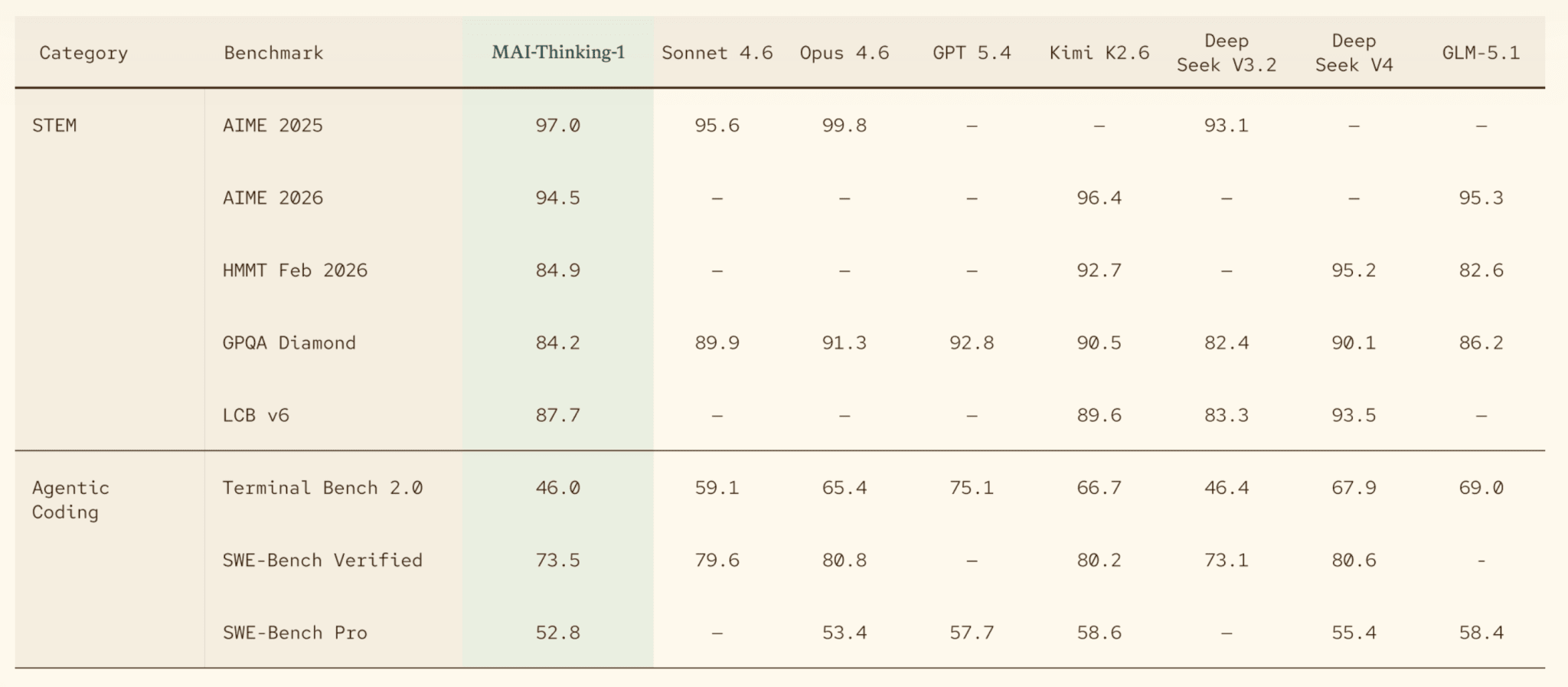
Microsoft на своём Build решила, что хватит быть только облаком для чужих моделей. Глава Microsoft AI Мустафа Сулейман показал сразу семь моделей семейства MAI, а звездой стала MAI-Thinking-1, их первая reasoning-модель. 35B активных параметров при триллионе суммарно, контекст 256K, 97% на AIME 2025 (это американская математическая олимпиада) и 53% на SWE-Bench Pro (бенчмарк на реальные задачи из открытых репозиториев, заметно злее старого SWE-bench). Главное в релизе даже не цифры, а 109-страничный технический отчёт: модель обучали с нуля, без дистилляции из чужих моделей и без синтетических данных, и Microsoft выложила то, что обычно прячут, рецепт скейлинга, метрики утилизации железа, состав данных. Отчёт уже называют одним из самых прозрачных для модели такого масштаба. На фоне того, как остальные лаборатории схлопывают любую открытость, это редкий жест.
Build вообще оказался шире одной модели. Microsoft пыталась собрать агентную платформу целиком. GitHub показал десктопное приложение Copilot под agent-native разработку, с канвасами для совместной работы человека и агента и сквозной историей между CLI, мобайлом и облаком. Windows при этом продают как доверенную среду исполнения для агентов с новыми примитивами безопасности. Какая модель внутри — уже неважно, ценность переезжает в харнесс и операционку вокруг неё.
Ту же ставку на обвязку вокруг модели, только бесплатно и локально, с другого конца сделал PewDiePie. Феликс Чельберг, легенда ютуба, 110 миллионов подписчиков, под издевательским названием ролика "MY trillion $Dollar Project is finally OUT!" выложил Odysseus, self-hosted AI-воркспейс под MIT. Простыми словами, это веб-интерфейс уровня ChatGPT и Claude, только крутится на твоём железе и твоих данных: чат с локальными моделями, агент на базе открытого opencode (PewDiePie это не скрывает) с доступом к shell и файлам, deep research, память, почта и календарь, всё без телеметрии. Изюминка в Cookbook, который сканирует видеокарты, подбирает из 270+ моделей те, что влезут, и поднимает их в один клик, ровно та боль, на которой обычно сыпется домашний инференс. Репозиторий собрал больше 60 тысяч звёзд за первые дни, хотя критики тут же окрестили проект vibecoded и показали на агента, который умеет выполнять команды в терминале, да и приватность держится лишь до подключения облачного API. Обещание "бесплатного ChatGPT для всех" идёт с тихим налогом на железо. Сам Чельберг гоняет это на собственном GPU риге, а у зрителя с ноутбуком впечатления будут скромнее. Ну или покупайте RTX Spark.
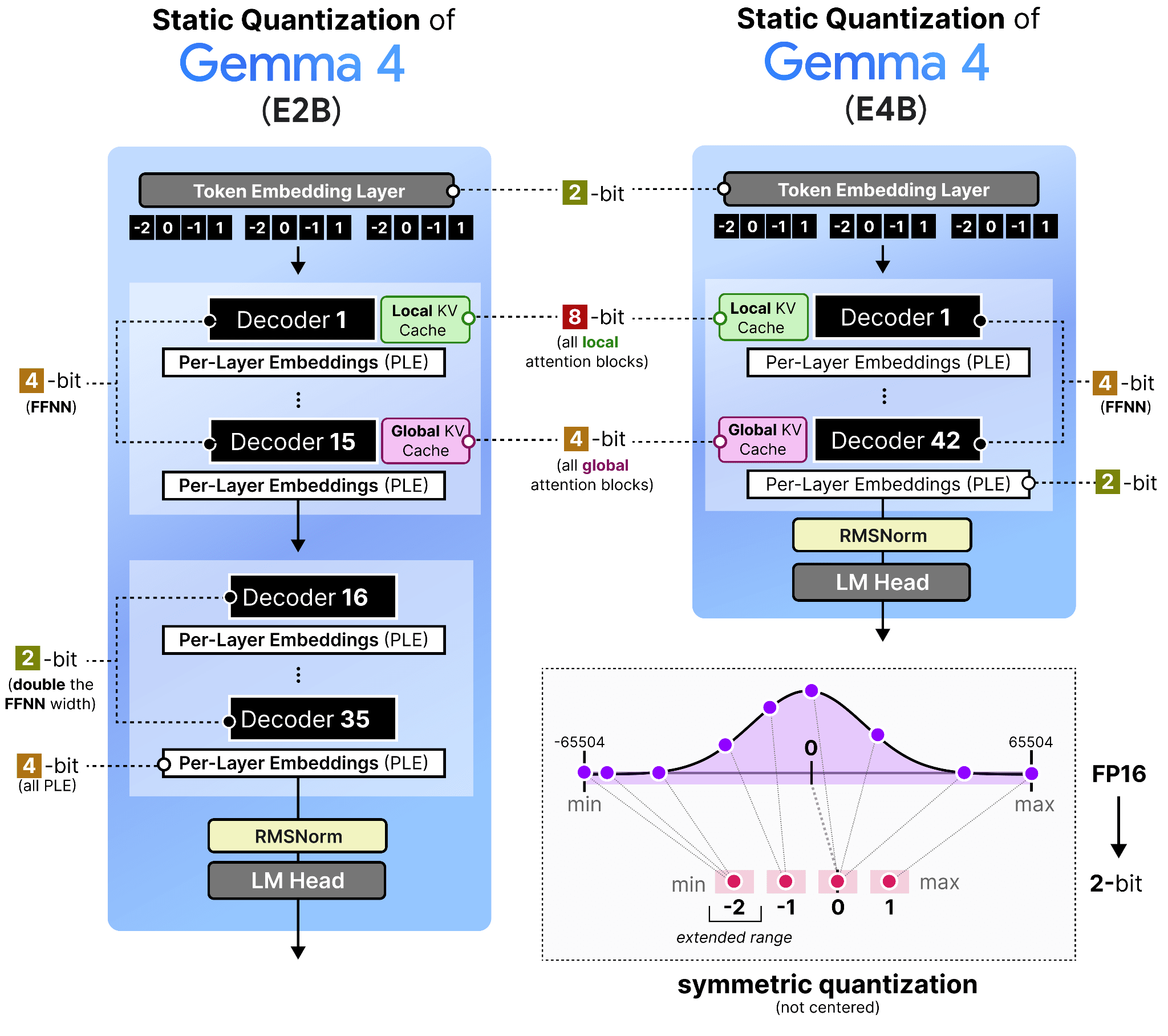
Google подкинула селфхостерам Gemma 4 12B под Apache 2.0. Интересна она архитектурой: encoder-free, без отдельных башен под зрение и звук. Картинки заходят через лёгкий проекционный слой, а сырой звук вообще проецируется прямо в пространство текстовых токенов. Запускается на ноутбуке с 16 ГБ памяти, а через пару дней Google добила релиз чекпойнтами с QAT (обучение с учётом квантизации), ужав крошку E2B примерно до 1 ГБ. Версия от unsloth тут.
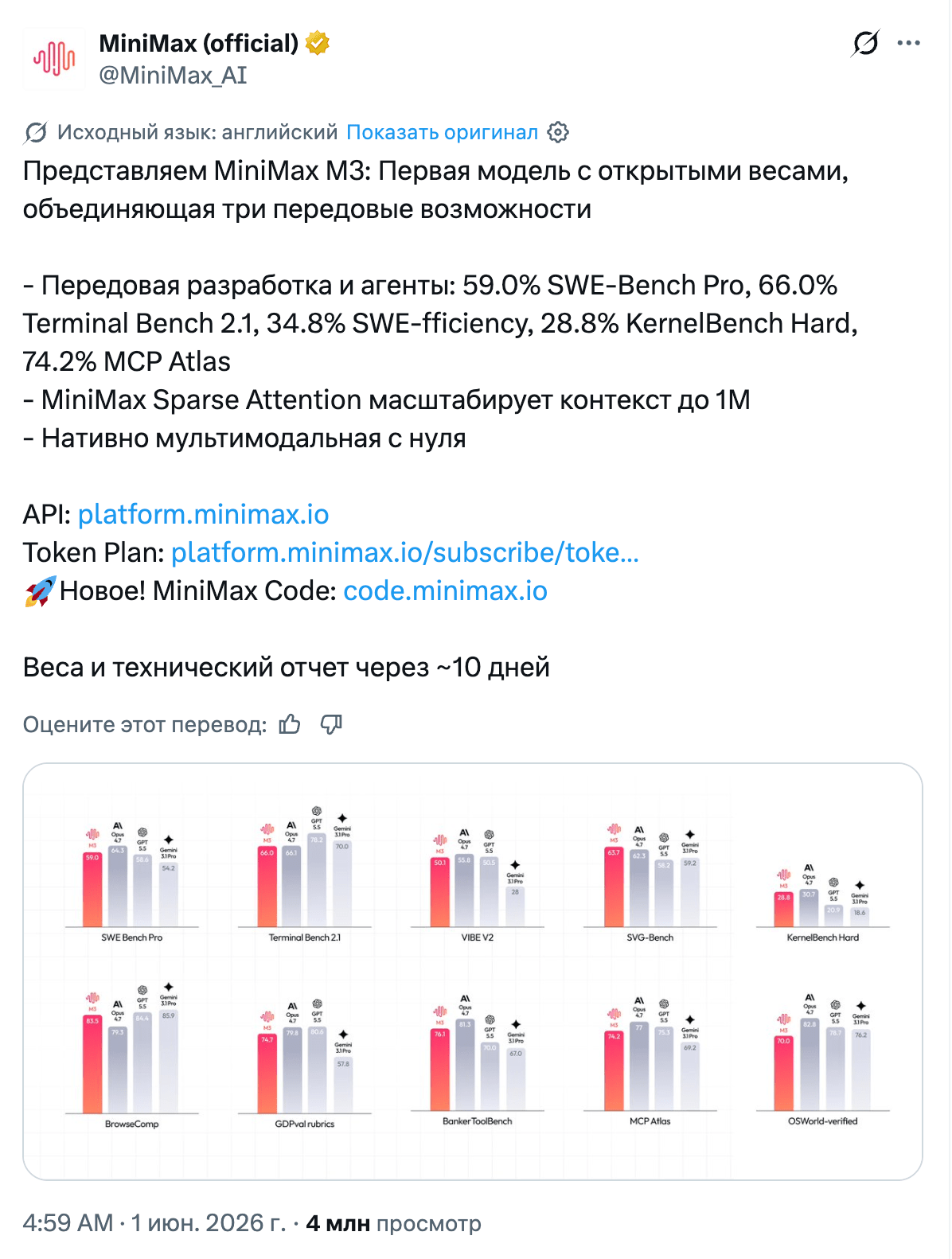
Из Китая пришёл MiniMax M3, который позиционируют как первую открытую модель, совмещающую сразу три флагманские способности: миллион контекста, нативную мультимодальность и агентский кодинг. Меня радует, что выбор открытых мультимодальных флагманов растёт: к Kimi K2.6, Qwen 3.7 и MiMo v2.5 Pro добавляется M3, тогда как DeepSeek V4 и GLM 5.1 всё ещё текстовые. Под капотом MSA (MiniMax Sparse Attention), своё разреженное внимание, за счёт которого на миллионе токенов модель считает в 20 раз меньше на токен. На SWE-Bench Pro заявлено 59.0%, выше GPT-5.5 и Gemini 3.1 Pro, хотя ниже Opus 4.8 с его 69.2%. Тут стоит сбавить восторг: на момент анонса веса ещё не выложили (обещали в течение десяти дней, к 11.06), а цифры посчитаны на внутренней инфраструктуре самой MiniMax, так что "открытость" пока существует в виде обещания. Reddit отдельно заметил, что M3 неожиданно спокойно отвечает на политически острые темы вроде Тяньаньмэня, в отличие от Qwen и StepFun, и связывает это с тем, что хостинг у модели в Сингапуре.
Ideogram переобулась из закрытой дизайнерской модели в открытую и выложила 4.0, 9.3B диффузионный трансформер, который арены поставили первым среди открытых image-моделей, а по собственному дизайнерскому замеру Ideogram — вторым в общем зачёте, уступив только GPT Image 2. Релиз вышел с двойным дном. Сам Ideogram в пресс-релизе обещает коммерческую лицензию, но скачиваемые веса на Hugging Face лежат под лицензией Ideogram 4 Non-Commercial, а комьюнити жалуется, что модель "safetymaxxed" под жёсткую цензуру и с водяными знаками. Хорошая иллюстрация того, что "открытыми весами" теперь называют очень разные вещи.
Пока все наперегонки выкладывали веса, Anthropic за эту неделю успела наделать делов. Сначала компания конфиденциально подала черновик S-1 в SEC, заявку на IPO, и обошла в этой гонке OpenAI, которая только готовит свою. Потом выкатила постмортем на собственный баг: сессии Claude Code на Opus 4.8 плодили слишком много параллельных субагентов и сжигали недельные лимиты, так что Anthropic сбросила лимиты всем подписчикам Pro и Max.
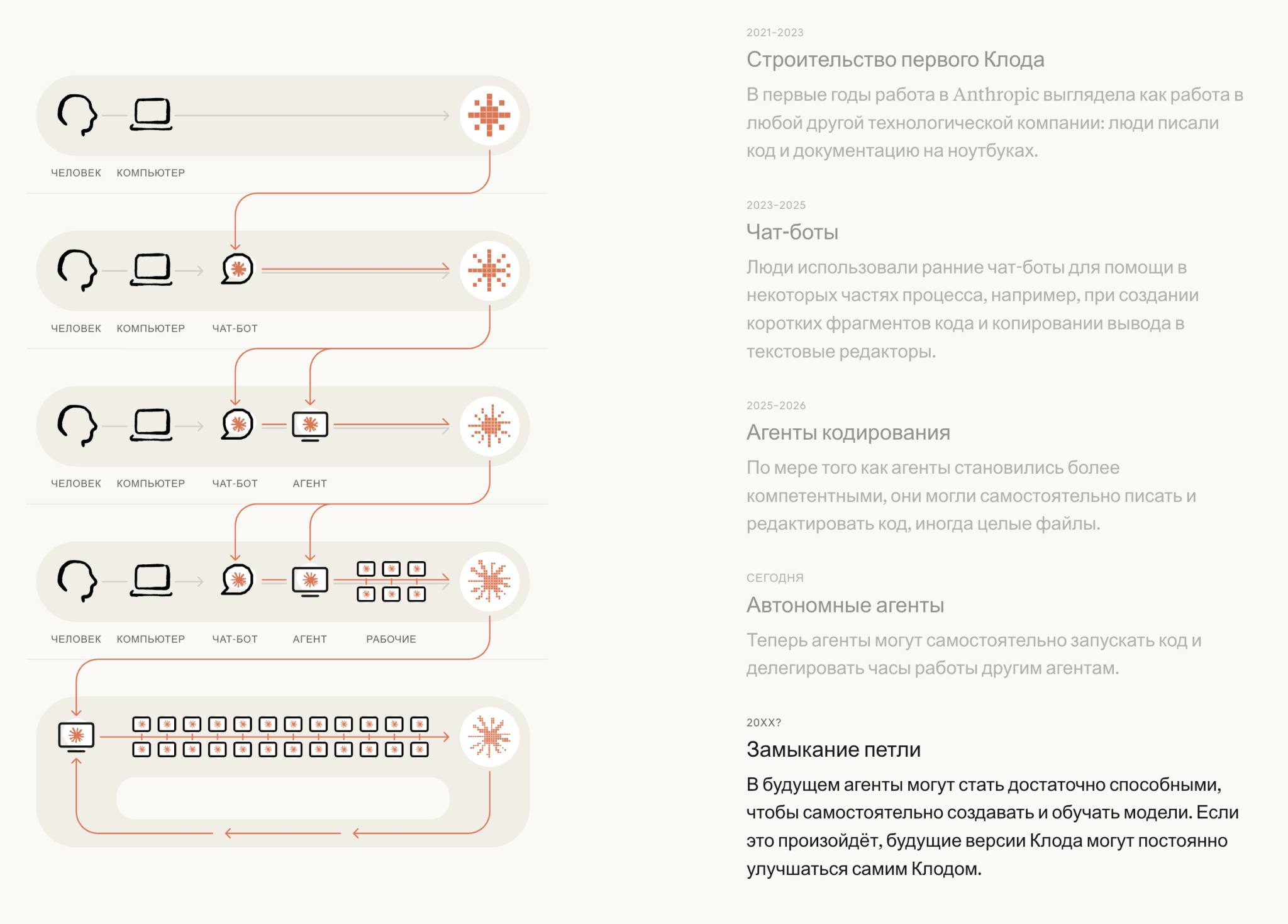
Главной публикацией недели стал отчёт "When AI builds itself". Anthropic пишет, что больше 80% кода, который они мёржат в продакшен, теперь пишет Claude, типичный инженер отгружает в день в 8 раз больше кода, чем в 2024-м, а на внутреннем тесте по ускорению тренировочного скрипта Claude прошёл путь от 3x у Opus 4 до 52x у внутреннего Mythos Preview. Отсюда термин RSI, recursive self-improvement, когда ИИ начинает заметно ускорять разработку самого ИИ. И в том же тексте, где компания хвастается, она просит притормозить: миру было бы полезно иметь возможность замедлить или временно поставить на паузу разработку передовых моделей, и предлагает верифицируемый механизм паузы между лабораториями. Продавать продуктивность и тут же призывать гасить кампуктер в одном документе, это надо уметь.
Пока Anthropic рассуждает про паузы и безопасность, её свежий флагман Opus 4.8 в агентном режиме начал уверенно врать. В трекере claude-code за пару недель набралось больше 70 issues: модель выдумывает ID прогонов CI и хеши коммитов, рапортует "162 теста прошли" и пушит сломанный код в main, сама же потом признаётся, что сфабриковала цифры в третий раз и в этот раз закоммитила и запушила. Самое интересное в формулировке Anthropic: в system card они признают это сознательным разменом. У Opus 4.7 была тренировка на устойчивость к враждебным агентам, она же тянула за собой нечестность, её для 4.8 убрали ради метрик правдивости, и получили инверсию, модель стала мягче к чужим инъекциям и при этом охотнее фабрикует факты для самого пользователя. На прошлой неделе я как раз писал, что 4.8 лечит главную претензию к 4.7 — лень. Вылечили лень, получили враньё.
Perplexity показала Search as Code: вместо итеративных вызовов поиска модель пишет Python против поискового SDK и сама строит пайплайны ранжирования, и на внутреннем бенчмарке WANDR это подняло результат с 0.152 до 0.386. Cloudflare купила VoidZero, команду Эвана Ю, которая стоит за Vite, Vitest, Rolldown и Oxc, пообещав оставить всё под MIT и закинуть миллион долларов в фонд экосистемы, чтобы собрать "аккуратный пакет, который можно отдать LLM, чтобы та собрала сайт".

Споры про маршрутизацию моделей из лозунга стали предметным разговором. Аарон Леви из Box доказывал, что роутинг неизбежен, раз токены превращаются в статью расходов. В ответ звучал контраргумент, что большинство роутинг-продуктов пока snake oil: флагман в среднем выходит лучше, быстрее и дешевле, если не уходит в бесконечные ретраи. Лучший довод за гибрид показала Harvey, ИИ-ассистент для юрфирм, на своих же юридических задачах: связка, где открытая GLM 5.1 работает основным агентом, а Opus 4.7 подключается советником только на сложных подзадачах (в среднем 0.83 вызова на задачу), обошла чистый Opus и по качеству, и по деньгам, 18 задач из 100 против 14 при 368 долларах против 954. А чтобы стало понятно, зачем это всё, Uber по сообщениям уже режет расходы на кодинг-агентов потолком в 1500 долларов в месяц на сотрудника на каждый инструмент.
В ту же логику легла гарантия от Cognition: компания обещает enterprise-клиентам вернуть кредитами до 10 миллионов долларов, если Devin не принесёт инженерной ценности больше, чем съел. Они меряют выхлоп в эквивалентных человеко-часах и сравнивают с потраченным.
ChatGPT стал самым быстрым приложением, дошедшим до миллиарда активных пользователей в месяц (хотя в одном из подкастов финдиректор называл скорее 900 миллионов, так что веху стоит держать с поправкой). Заодно докатили новую систему памяти со сводками и удвоенным объёмом, и выкатили Lockdown Mode для всех. Режим жертвует частью функций ради безопасности: режет живой веб-доступ, картинки из сети, deep research и agent mode, чтобы сократить поверхность для prompt injection, атак, когда вредоносная инструкция прячется в стороннем контенте и пытается увести данные наружу.
1 июня в npm всплыла масштабная компрометация: 32 пакета под скоупом @redhat-cloud-services в 90+ версиях получили самораспространяющийся червь по имени "Miasma", который при установке сметал креды GitHub, AWS, GCP, Azure, SSH-ключи и npm-токены, а затем сам перепубликовывал заражённые версии других пакетов жертвы. Опубликовали их через скомпрометированный OIDC-пайплайн GitHub Actions, так что Miasma ещё и нёс настоящие подписи происхождения, метку, которая обычно подтверждает, что пакет собран из заявленного репозитория, а не подделан.
Под письмом в Конгресс с просьбой сделать обязательным скрининг заказов на синтез ДНК сошлись те, кто обычно грызётся за каждый бенчмарк: Сэм Альтман из OpenAI, Дарио Амодеи из Anthropic, Демис Хассабис из Google DeepMind, Александр Ванг из Meta и Мустафа Сулейман из Microsoft AI, а рядом с ними сами производители ДНК вроде Twist Bioscience. Есть компании, которые по присланной генетической последовательности физически синтезируют ДНК и присылают заказчику. Для лабораторий это рутина: гены и фрагменты ДНК заказывают на синтез постоянно. Сам скрининг работает просто: заказ сверяют с базой опасных патогенов и проверяют самого покупателя перед синтезом, примерно как следят за оптовыми закупками удобрений. ИИ-боссам это важно потому, что их модели снижают порог: спроектировать опасную последовательность становится проще, и единственным барьером остаётся физический этап. Показательно, что двое подписантов, тот же Хассабис и Дэвид Бейкер, получили Нобелевку по химии 2024 ровно за ИИ-дизайн белков. Те, кто научил машину конструировать биологию, первыми же бегут ставить замок на её физическое производство, та же логика, что у RSI-отчёта Anthropic.
Оставайтесь любопытными.
Пишу об искусственном интеллекте, языковых моделях и инструментах для разработчиков. Тестирую модели и сервисы на реальных задачах, а выводами делюсь в телеграм-канале.