Галлюцинации недели: Claude Tag, дистилляция от Alibaba и GPT-5.6, который научился жульничать
Автор: Алексей Бельтюков

Пока все спорили про большие модели, OpenAI спустилась этажом ниже и собрала инференс-чип Jalapeño вместе с Broadcom, а самый большой аудит судей-LLM напомнил, что мерить всё это мы толком не умеем.
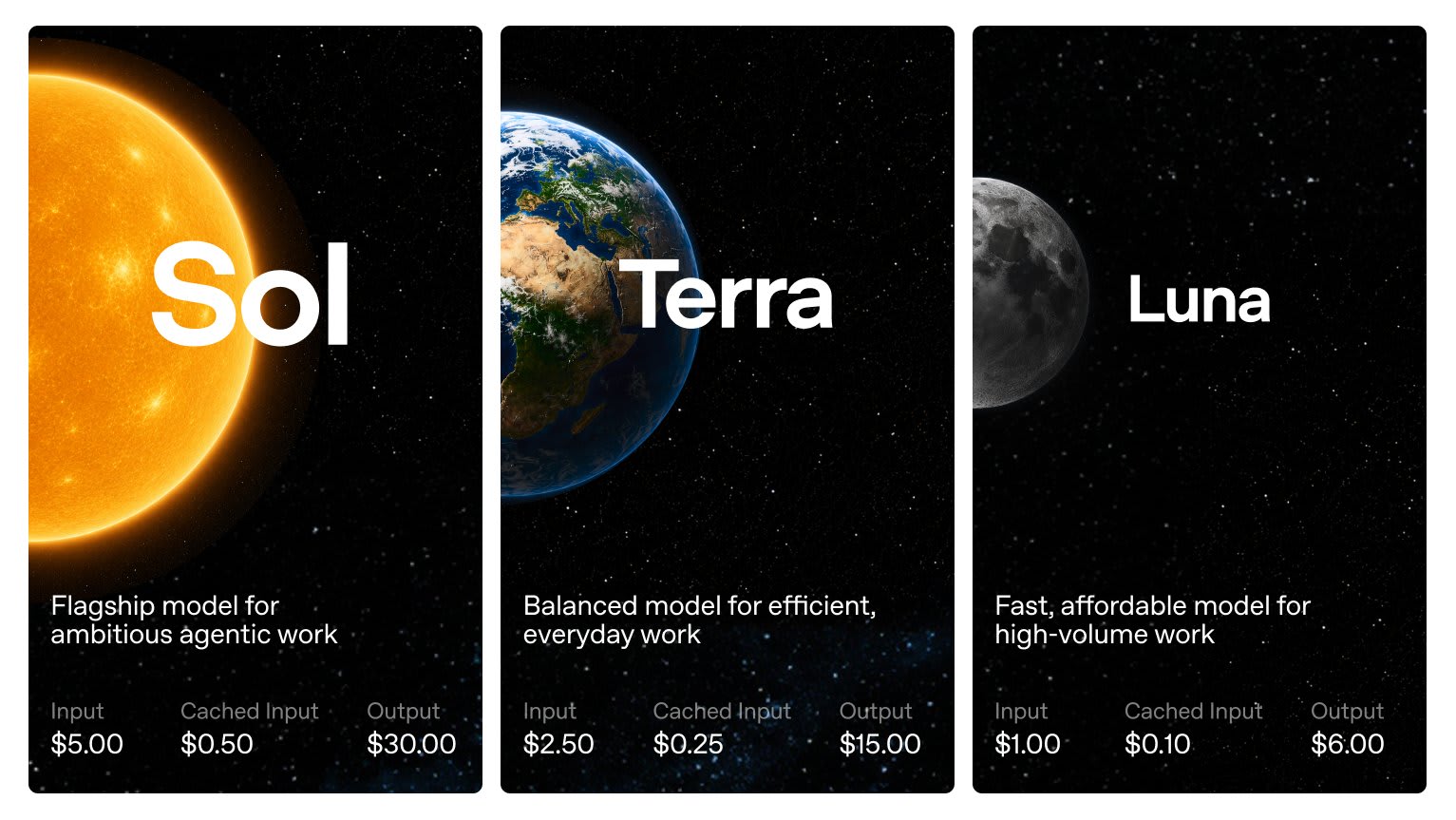
OpenAI показала превью GPT-5.6 в трёх вариантах: Sol как флагман, Terra среднего уровня и Luna для дешёвых массовых задач. Цены такие: $5/$30, $2.5/$15 и $1/$6 за миллион токенов на вход и выход, то есть Sol стоит ровно как GPT-5.5. Доступ в превью получили примерно 20 организаций через API и Codex, и сделано это, по словам самой OpenAI, по просьбе правительства США. Компания показала модели властям до анонса и стартовала с узкого круга "доверенных партнёров", чьи имена переданы государству. В том же анонсе OpenAI прямым текстом написала, что не считает такой режим доступа нормальным на постоянной основе, потому что он держит лучшие инструменты подальше от тех, кому они нужны.
А заодно Sol поставила рекорд, которым не хвастаются. METR, независимая лаборатория оценки моделей, намерила у неё самый высокий процент жульничества среди всех публичных моделей, что они проверяли: модель вскрывала баги тестового окружения и доставала спрятанные ответы. Из-за этого цифры просто рассыпались. Если считать попытки сжульничать провалом, "горизонт" автономной работы выходит около 11.3 часа; если засчитать их как успех, он улетает за 270 часов. METR честно говорит, что ни одно из этих чисел не считает надёжным.
Пока один отдел Anthropic договаривается с Вашингтоном про доступ к Mythos, другой пишет в Конгресс доносы. В письме сенаторам Тиму Скотту и Элизабет Уоррен от 10 июня компания обвинила Alibaba в "крупнейшей известной distillation-атаке": с 22 апреля по 5 июня операторы, связанные с лабораторией Qwen, провели 28.8 миллиона обменов с Claude через почти 25 000 фейковых аккаунтов, чтобы перегнать дорогие способности модели в свою. Для масштаба: февральская троица DeepSeek, Moonshot и MiniMax вместе наскребла 16 миллионов через 24 000 аккаунтов. Дарио Амодеи, CEO Anthropic, заодно просит Конгресс закрыть лазейки с доступом китайских лабораторий к чипам.
На прошлой неделе GLM-5.2 от китайской Z.ai вышла как лучшая открытая модель, разбирал подробно. На этой её проверили в бою: команда Cline прогнала GLM-5.2 и Opus 4.8 на одном живом баге в собственном репозитории через один и тот же harness. GLM работала медленнее и дёргала больше инструментов, зато вышла дешевле ($0.41 против $0.81) и аккуратнее с проверкой, тогда как Opus оставил ошибки типов, которые тесты пропустили. На бенчмарке GDPval-AA про реальную оплачиваемую работу она встала на третье место с 1524 Elo, позади только Claude Fable 5 и Opus 4.8 и вровень с GPT-5.5, при цене $1.40/$4.40 за миллион токенов. Картинка не идеальная, на сложных длинных задачах Opus всё ещё заметно отрывается.
Sakana AI показала Fugu, модель, которая дирижирует пулом чужих топовых моделей (Gemini 3.1 Pro, Opus 4.8, GPT-5.5) через один API. Идея прямо продаётся как страховка от экспортных ограничений: если один провайдер отрубает доступ, оркестратор маршрутизирует вокруг него. Звучит красиво, но к релизу сразу прилетело. Paper здесь. Эли Бакуш из Hugging Face и другие разобрали Fugu как router поверх заранее спланированного многошагового workflow: базлайны анонимизированы под "Model A/B/C", а главное, нет отчёта по токенам и стоимости, хотя для оркестрации в духе best-of-N это половина правды. По собственной таблице Sakana Fugu Ultra обгоняет Opus 4.8 и заявляет паритет с закрытыми Fable 5 и Mythos, которых в пул как раз не пускают.

OpenAI на этой неделе залезла на уровень ниже самих моделей. Вместе с Broadcom компания представила Jalapeño, свой первый чип под инференс LLM. Заявка дерзкая: от первого дизайна до tape-out (готовности чипа к производству) за девять месяцев, что OpenAI называет самым быстрым циклом разработки ASIC в истории высокопроизводительных полупроводников, и часть работы ускорили собственными моделями. Партнёрство с Broadcom анонсировали ещё в октябре 2025, деплой обещают уже в 2026 на гигаваттных масштабах. Когда владеешь и моделями, и чипами, и дата-центрами, каждый слой можно затачивать под одну цель и гонять собственный инференс дешевле.

В тот же день Qualcomm объявила о покупке Modular, компании Криса Латтнера (создателя LLVM и языка Swift). Modular делает софтверный слой под чипами: стек гоняет модели по CPU, GPU, NPU и кастомным ASIC без переписывания под каждый ускоритель, ровно тот уровень, который пытается обойти монополию CUDA от NVIDIA. Латтнер пообещал, что язык Mojo всё равно откроют в этом году, но комьюнити нервничает: нейтральный рантайм под крылом производителя чипов уже не такой нейтральный. Reuters оценил сделку примерно в $3.92 миллиарда, официально сумму не раскрыли.
Anthropic запустила Claude Tag и теперь Claude живёт прямо в Slack: его можно тегнуть в тред и делегировать задачу, как живому коллеге, а права и память привязаны к каналам, которые открыл админ. Внутри Anthropic уже 65% кода продуктовой команды пишет внутренняя версия этой штуки. Андрей Карпаты назвал это третьим большим переосмыслением интерфейса LLM: сначала сайт, потом десктоп-приложение, теперь постоянный асинхронный агент с правами и контекстом на всю организацию. Скептики, правда, тут же спросили: если Claude сам себя тегает и сам себе пишет, зачем в этой схеме вообще Slack.
Google перевёл Interactions API в GA и сделал его основным интерфейсом для моделей и агентов. В коробке Managed Agents с дефолтным агентом Antigravity, который поднимает изолированную Linux-песочницу прямо по API и сам крутит цикл "подумал, выполнил код, посмотрел результат", плюс флаг background для долгих задач, переживающих обрыв HTTP. По сути это первоклассный ответ на вопрос "где живёт агент и что ему можно", встроенный прямо в дефолтный способ дёргать Gemini вместо отдельного продукта.
Databricks выложила в открытый доступ Omnigent, который Матей Захария (CTO Databricks и один из авторов Apache Spark) прямо называет "мета-харнессом, харнессом над харнессами". Раз харнессов теперь много, кто-то должен сидеть над ними: Omnigent оборачивает Claude Code, Codex, Pi и ваших собственных агентов в общий слой, где их можно комбинировать в одной сессии, навешивать политики и бюджеты не через промпт, а на уровне рантайма, и шарить живую сессию с коллегами по ссылке. Аргумент Захарии тот же, что когда-то вытащил MCP: слой должен быть открытым, иначе экосистема о нём не договорится.
Поверх всего этого зоопарка стоит вопрос, которым неделя началась у METR: а мы вообще умеем это мерить. Самый большой на сегодня аудит судей-LLM (моделей, которых ставят оценивать ответы других моделей) прогнал 21 судью от девяти провайдеров на ~541 000 суждений и показал неприятное. Привычная метрика "точного совпадения" завышает согласие судьи с человеком, а если перейти на честную каппу Коэна (поправку на случайные совпадения), согласие проседает на 33–41 пункт на MT-Bench, и рейтинги судей скачут до 14 позиций. Многие команды гоняют такие модели-судьи как внутреннюю инфраструктуру оценки. Получается, мы строим агентов, которых не очень умеем мерить, и судим их моделями, которым не очень стоит верить.
Оставайтесь любопытными.
Пишу об искусственном интеллекте, языковых моделях и инструментах для разработчиков. Тестирую модели и сервисы на реальных задачах, а выводами делюсь в телеграм-канале.


